
2026-04-29
16、网络连接的内存开销
这一节要回答的核心问题是:
- 一条 TCP 连接在 Linux 内核里到底会消耗哪些内存?
- 一台机器最多能支撑多少条 TCP 连接,真正的瓶颈是什么?
- 为什么空连接、收发数据的连接、
TIME_WAIT连接,占用的内存不一样?
先给结论:**TCP 连接的基础开销主要来自内核对象,这些对象由 slab/slub 管理;有数据收发时,还会额外消耗 TCP 发送缓冲区、接收缓冲区以及 sk_buff 等相关内存。**所以“一个连接占多少内存”不是固定常数,只能在某个内核版本、某种连接状态、某种收发行为下估算。
一、从实际困惑开始
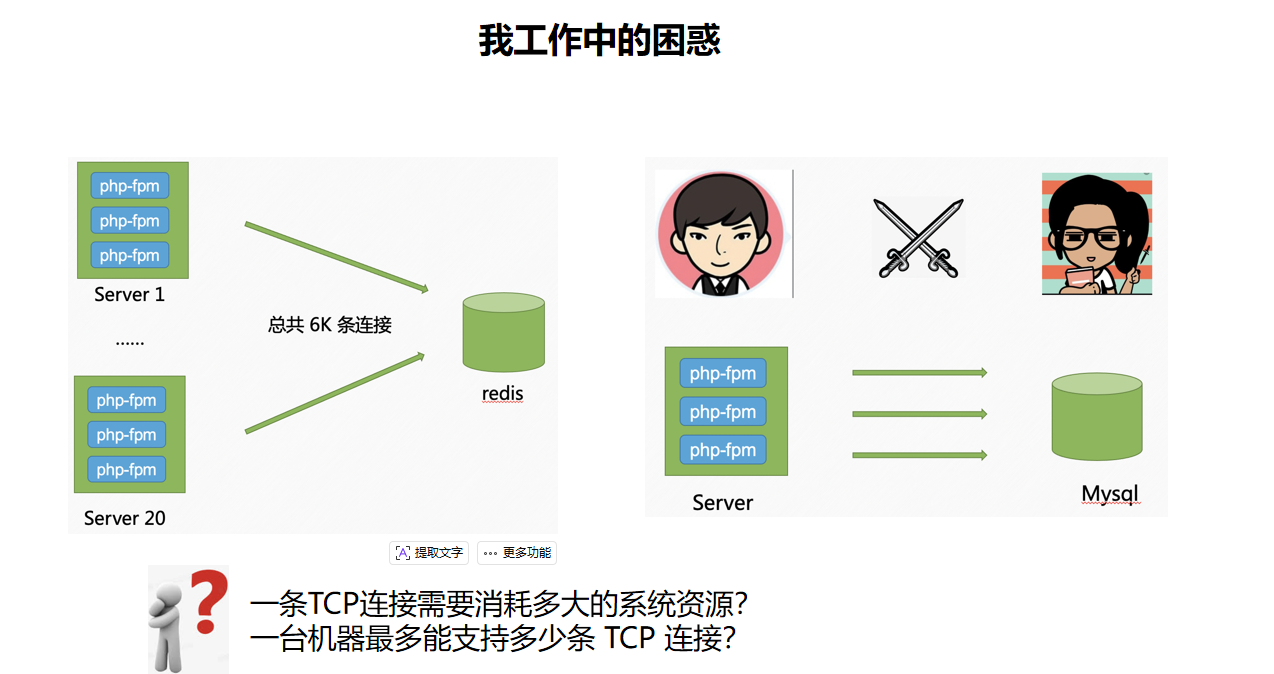
这张图里的场景是线上很常见的长连接问题:
- 左侧:多台业务服务器上的
php-fpm进程都连接到同一个 Redis,总共约 6K 条连接。 - 右侧:业务服务器连接 MySQL,也会形成大量 TCP 连接。
- 问题:一条 TCP 连接会消耗多少系统资源?一台机器最多能维护多少条连接?
这里容易有两个误区:
- **误区一:最多只能 65535 条连接。**端口号确实是 16 位,但服务端连接由四元组唯一确定:源 IP、源端口、目的 IP、目的端口。对一个监听在固定 IP:Port 上的服务端来说,客户端的源 IP 和源端口都可以变化,所以理论四元组空间远大于 65535。
- **误区二:理论四元组空间就是实际上限。**真实机器会先被文件描述符、内核对象、TCP 缓冲区、CPU 调度、业务处理能力等资源限制住。本文重点看内存。
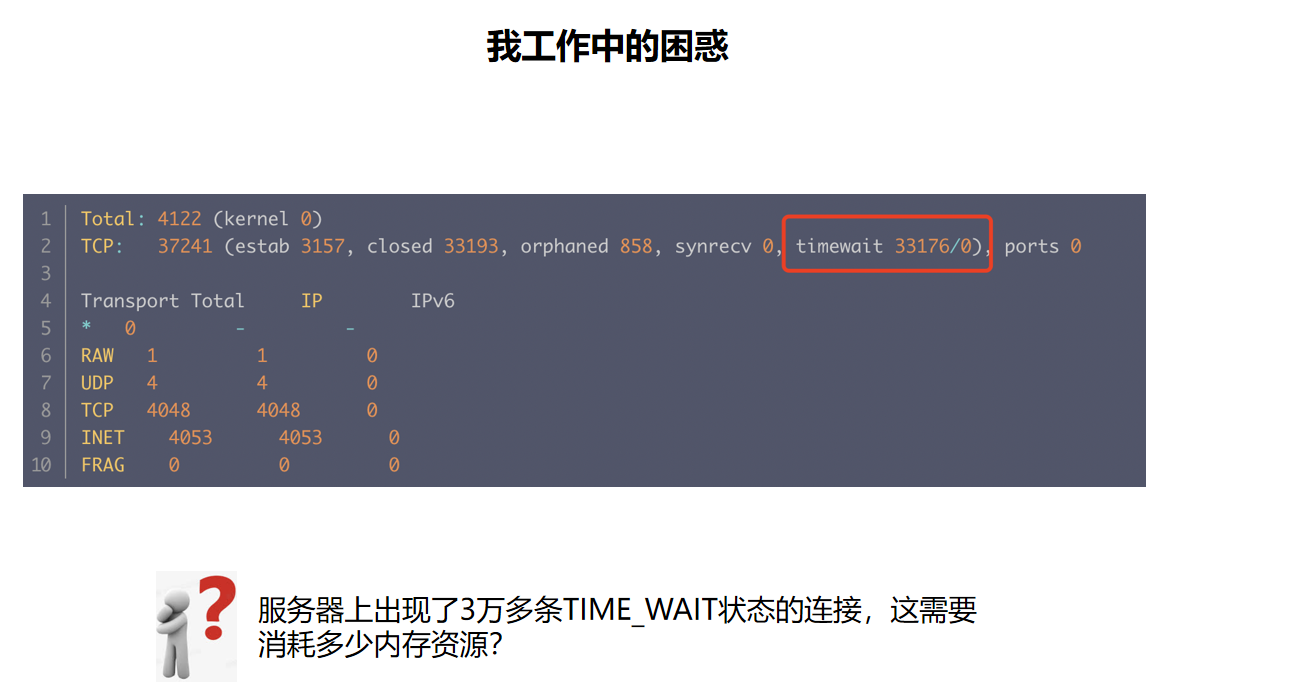
这张图展示的是 ss -s 或类似统计输出:机器上出现了 3 万多条 TIME_WAIT 连接。问题变成:TIME_WAIT 会不会像 ESTABLISHED 一样消耗很多内存?
答案是:不会完全一样。TIME_WAIT 状态下,Linux 会释放掉很多完整 socket 连接阶段才需要的对象,只保留更轻量的 time-wait 结构,用来完成 2MSL 等 TCP 语义。因此它比一条活跃的 ESTABLISHED 连接轻很多,但数量极大时仍然值得关注。
二、先理解 Linux 内核怎样管理内存
要理解 TCP 连接的内存开销,不能直接从 TCP 开始。因为 TCP 连接最终要落到 Linux 内核的内存分配体系里。可以按三层理解:
- 物理页分配器:以页为基本单位,常见页大小是 4KB。
- 伙伴系统 buddy system:管理 4KB、8KB、16KB、… 这类 2 的幂大小的连续页块。
- slab/slub 分配器:面向内核小对象,比如
struct file、socket、TCP 控制块等。
2.1 NUMA Node、Zone、Page
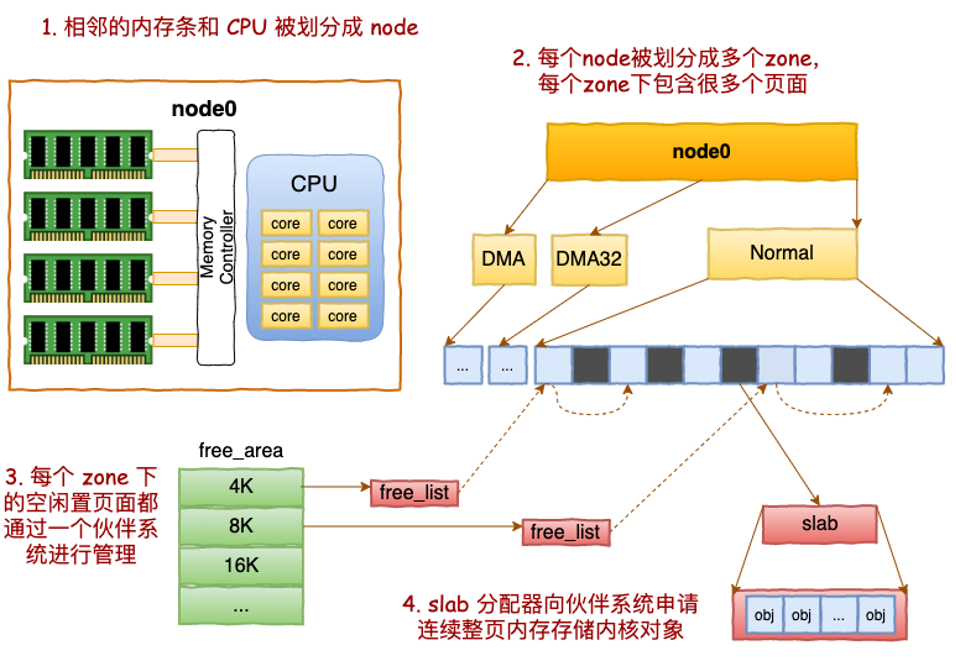
这张图把 Linux 物理内存管理的层次画出来了:
- Node:在 NUMA 机器上,CPU 和内存会被划分为多个 node。CPU 访问本 node 的内存更快,跨 node 访问更慢。
- Zone:每个 node 下面会继续分成多个 zone,常见有
DMA、DMA32、Normal。这是为了满足不同硬件或地址范围的分配需求。 - Page:zone 下面是一个个页框,常见大小是 4KB。内核页分配器主要以页为单位工作。
- 伙伴系统:当内核需要连续内存时,会从不同 order 的空闲链表中分配页块。
- slab:当内核需要比 4KB 更小、但频繁创建销毁的对象时,会从 slab/slub 管理的对象池中分配。
2.2 Buddy System:页级别的连续内存管理
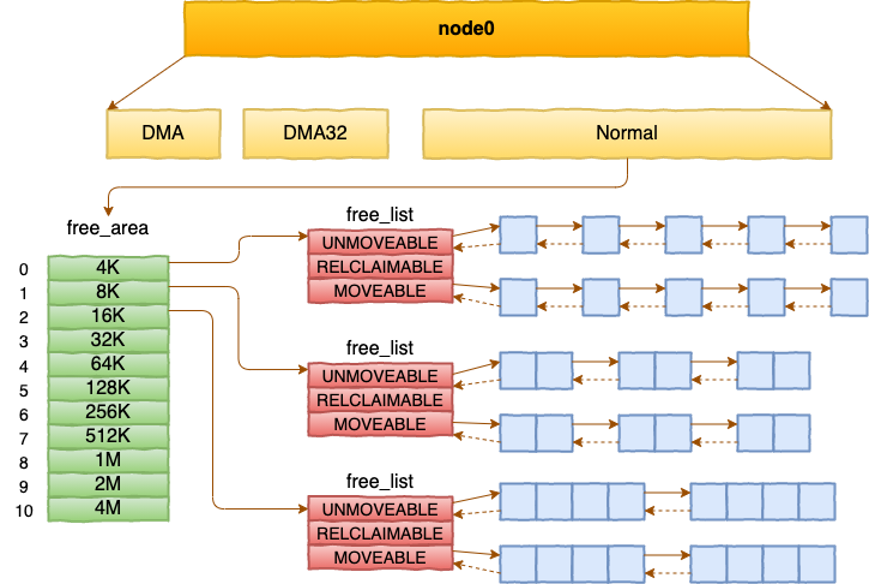
这张图放大了伙伴系统:
- 左侧的
4K、8K、16K、...、4M对应不同的 order。 - 如果页大小是 4KB,那么:
order 0 = 1 page = 4KBorder 1 = 2 pages = 8KBorder 2 = 4 pages = 16KBorder n = 2^n pages
- 右侧每一行是同一 order 的空闲块链表。
- 中间的
UNMOVABLE、RECLAIMABLE、MOVABLE是迁移类型,用来降低内存碎片。
伙伴系统的核心思想是“拆分与合并”:
- 分配 4KB 时,如果
order 0没有空闲块,可能从更大的块拆出来,比如8KB的,但是将其一份8KB分为2个小块 - 释放内存时,如果相邻的 buddy 块也空闲,会尝试合并成更大的连续块。
这解释了为什么 Linux 不只是看“还剩多少内存”,也关心“有没有足够大的连续空闲块”。大量小块分配和释放会造成外部碎片。
2.3 怎么查看物理机的 Node 和内存条

这张图展示用 dmidecode 查看 CPU 和内存条信息:
dmidecode -t processor
dmidecode -t memory
图里可以看到:
- 机器有两颗 CPU,例如
CPU1、CPU2。 - 每颗 CPU 下面插了多条内存,例如
CPU1 DIMM A1、CPU1 DIMM A2。
这类硬件布局和 NUMA node 有关。实际排查时也常配合:
lscpu
numactl --hardware
cat /sys/devices/system/node/node*/meminfo
2.4 怎么查看 Zone 和 Buddy 空闲情况
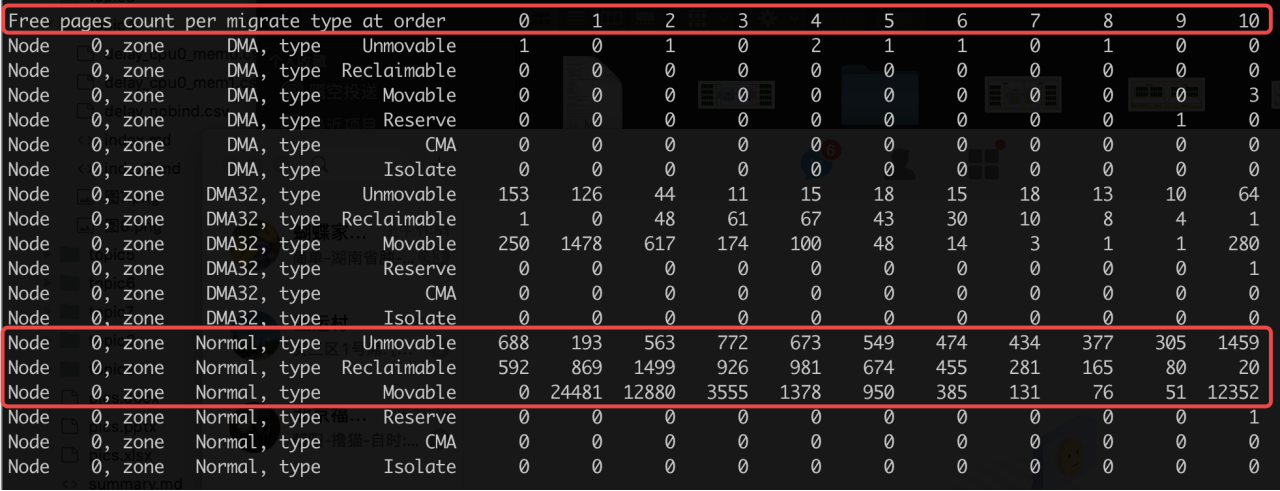
图中命令是:
cat /proc/pagetypeinfo
重点读法:
- 表头
order 0 ... 10表示不同大小的连续页块。 - 行里的
Node 0, zone Normal, type Unmovable表示某个 node、某个 zone、某种迁移类型。 - 数字表示对应 order 下还有多少个空闲块。
例如某行 order 10 的数字很少,说明大块连续内存不足。Linux 内核文档也说明,buddyinfo/pagetypeinfo 可以用来诊断外部碎片;每一列表示某个 order 的可用页块数量。1
这部分和 TCP 连接有什么关系?因为 slab/slub 最终也要向页分配器申请 page。大量 TCP 连接会让 socket 相关 slab cache 膨胀,间接消耗大量物理页。
三、SLAB/SLUB:内核小对象从哪里来
上一节看的都是 4KB 页及更大页块。但 TCP 连接里的很多结构不是 4KB 整数倍的大块,而是几百字节到几 KB 的内核对象。此时就轮到 slab/slub 分配器。
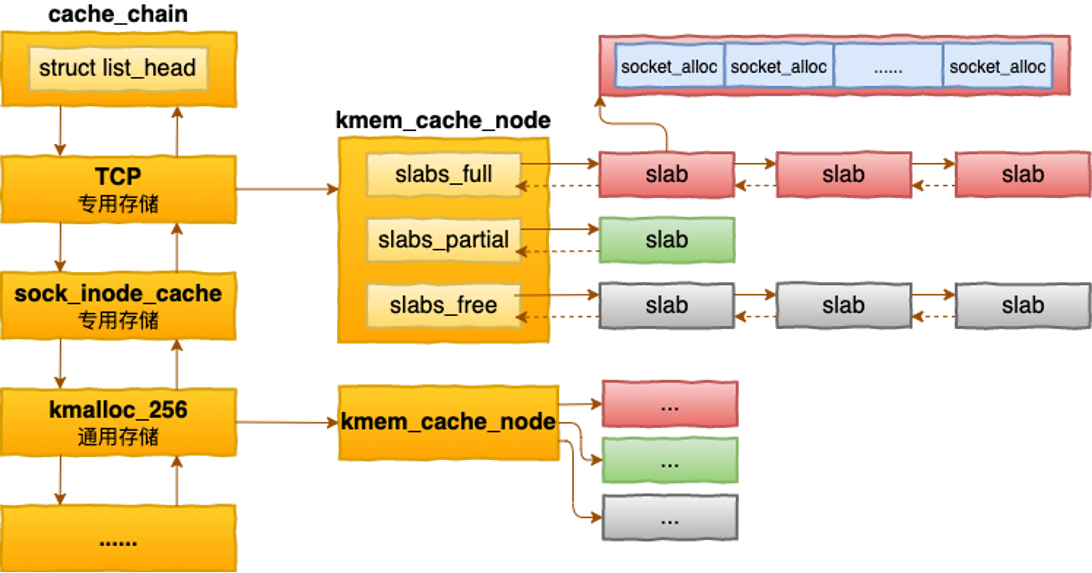
这张图展示 slab 的基本模型:
- 左侧是不同类型的 cache,例如:
TCP专用存储sock_inode_cache专用存储kmalloc-256通用小对象存储
- 每个 cache 下面有多个 slab。
- 每个 slab 又由一个或多个 page 组成。
- 一个 slab 内切成多个同类型对象槽位,例如多个
socket_alloc。
为什么需要 slab?
- 内核对象会频繁创建和销毁,直接每次找 buddy system 分配页太重。
- 同类对象大小固定,复用同一类对象池可以减少碎片。
- 对象释放后,下次创建同类对象可以直接复用,不必重新初始化全部元数据。
可以把它理解为:buddy 管页,slab 管对象。
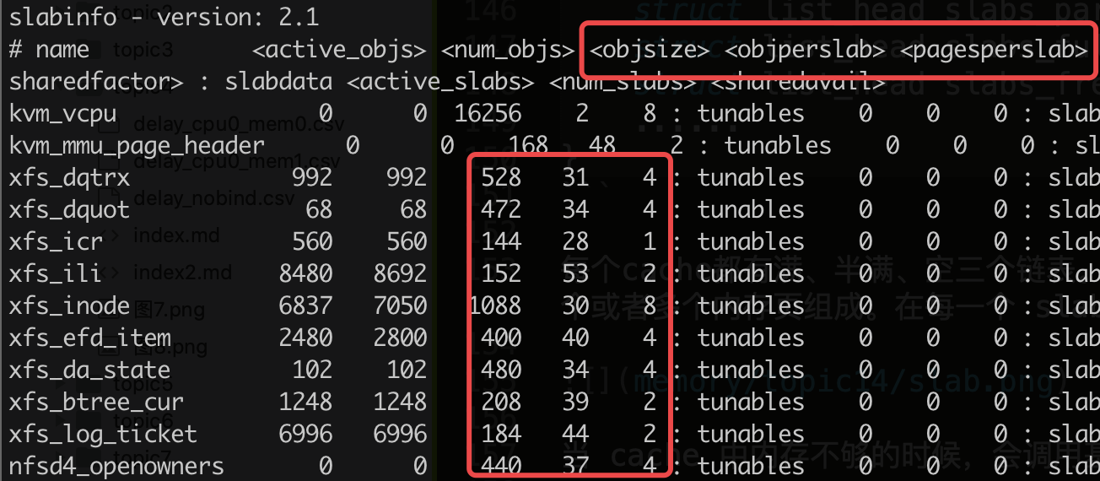
这张图展示 /proc/slabinfo 的关键列:
cat /proc/slabinfo
常用列含义:
active_objs:当前正在使用的对象数。num_objs:该 cache 已经分配出来的总对象数,包括正在使用和空闲可复用的对象。objsize:每个对象的大小,单位字节。objperslab:每个 slab 可以放多少个对象。pagesperslab:每个 slab 占多少个 page。
Linux manual 对 /proc/slabinfo 的解释也是:常用的内核对象会有自己的 cache,/proc/slabinfo 给出这些 cache 的统计信息。2
排查网络连接内存时,更常用交互工具:
slabtop
slabtop -o
关注名字里和连接相关的 cache,例如 TCP、sock_inode_cache、filp、dentry、tcp_bind_bucket、tw_sock_TCP 等。不同内核版本、不同 allocator,名字和大小可能略有差异。
四、TCP 连接对应哪些内核对象
一条 TCP 连接不是只有“一个 socket”这么简单。应用层看到的是一个文件描述符 fd;内核里会牵出一组对象。简化理解如下:
用户进程 fd
-> struct file # Linux 一切皆文件,socket 也通过 file 暴露给进程
-> socket / socket_alloc # socket 层对象
-> inode / sock_inode_cache # socket 文件系统相关对象
-> struct sock / tcp_sock # 协议栈里的 TCP 控制块
-> 发送队列、接收队列、定时器、状态字段等
因此,高并发连接的内存不是只看 TCP cache,还要看文件对象、socket inode、目录项等对象是否随连接数线性增长。视频里的百万连接实验,正是通过 slabtop 观察这些 cache 的数量变化。
五、网络连接内存开销实验
实验方法:创建约 100 万条 TCP 连接,然后观察 ss、/proc/meminfo 和 slabtop。
5.1 服务端空连接实验
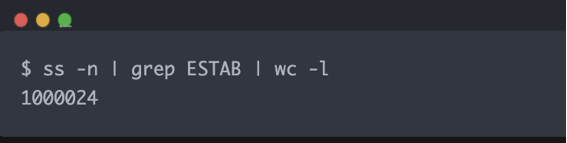
这张图用命令统计服务端 ESTABLISHED 连接数:
ss -n | grep ESTAB | wc -l
结果约为:
1000024
说明服务端已经维护了约 100 万条已建立连接。
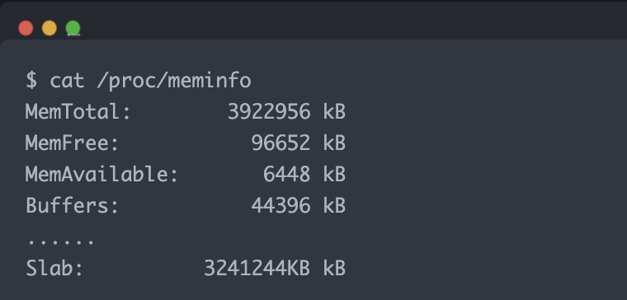
这张图看 /proc/meminfo:
cat /proc/meminfo
重点字段是:
Slab: 3241244 kB
Slab 占到了约 3.2GB,说明百万连接把大量内核对象池撑起来了。粗略除以 100 万,单连接平均约 3.2KB。视频中按实验前后差值和相关对象估算,服务端空连接平均约 3.27KB/连接。
5.2 用 slabtop 看钱花在哪了
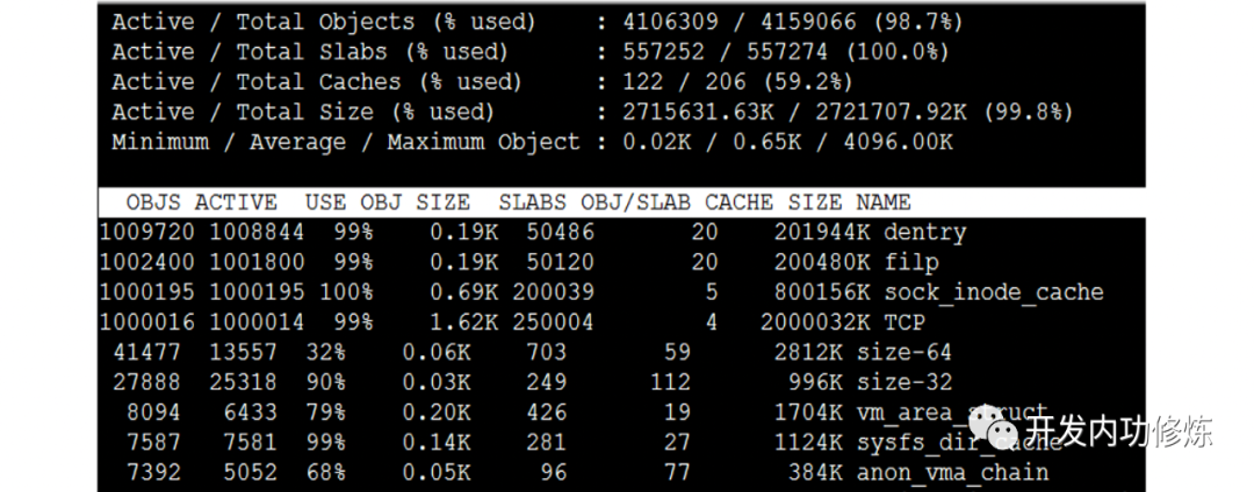
这张图是服务端的 slabtop。最关键的几行是:
dentry:约 100 万对象,单对象约 0.19KB。filp:约 100 万对象,单对象约 0.19KB,对应打开文件对象。sock_inode_cache:约 100 万对象,单对象约 0.69KB。TCP:约 100 万对象,单对象约 1.62KB。
这些对象大致解释了为什么空连接也要 3KB 多:
dentry 约 0.19KB
filp 约 0.19KB
sock_inode_cache 约 0.69KB
TCP 约 1.62KB
其他对齐、slab 内部碎片、辅助对象
--------------------------------
合计约 3.2KB ~ 3.3KB/连接
这里的重点不是背具体数字,而是理解口径:空连接的基础开销主要来自“维持连接身份和状态”的内核对象,而不是收发缓冲区。
5.3 客户端空连接实验
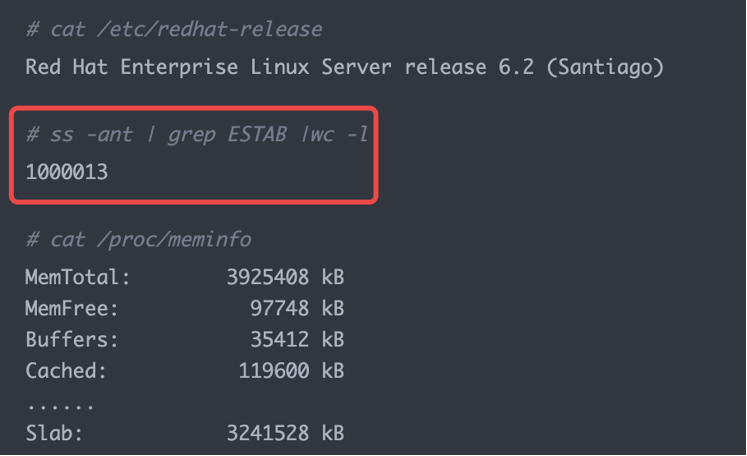
这张图是客户端侧实验,同样建立了约 100 万条 ESTABLISHED 连接,并观察 /proc/meminfo。视频里的结论是:客户端平均每条连接约 3.4KB。
客户端和服务端数字略有差异是正常的,原因包括:
- 主动发起连接的一侧和被动接受连接的一侧,连接建立路径不同。
- 不同内核版本对象大小不同。
- slab cache 有内部空闲对象和对齐损耗。
- 统计时如果按
Slab总量差值计算,会包含一部分非 TCP 连接对象的扰动。
5.4 客户端 slabtop
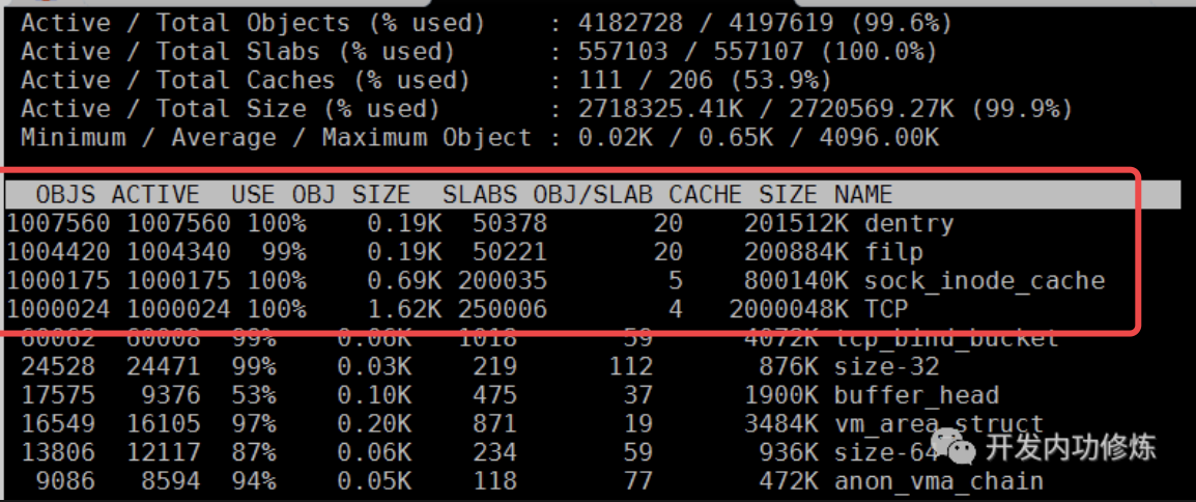
这张图和服务端类似,仍然能看到 dentry、filp、sock_inode_cache、TCP 这些对象数量都接近 100 万。
这说明:**一条完整的 TCP 连接,在客户端和服务端都会各自维护一套内核对象。**不是只有服务端才消耗内存,客户端大量并发访问 Redis、MySQL、HTTP 服务时,也会承担同样的问题。
六、不同连接状态和收发行为的内存差异
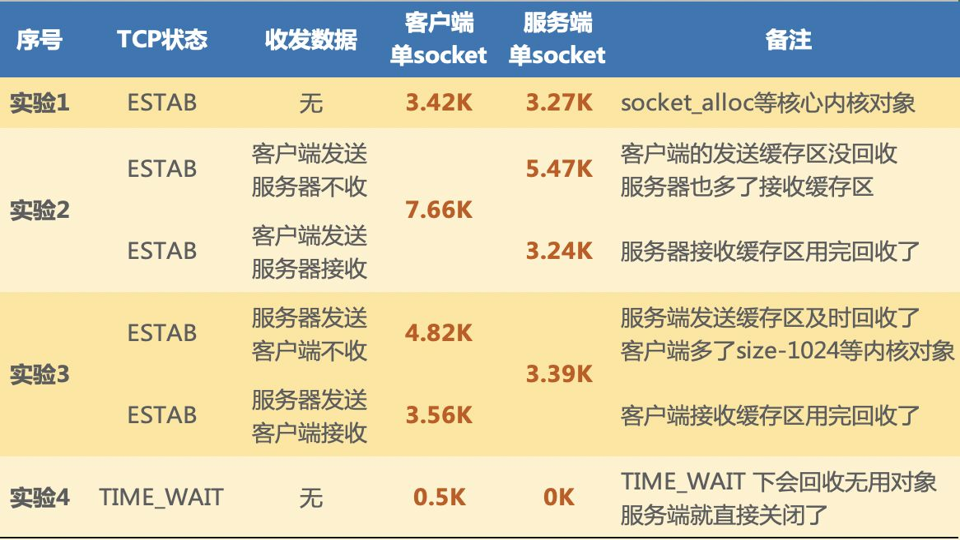
这张表是整个实验最有价值的总结。它说明:
- 空
ESTABLISHED连接:客户端约 3.42KB,服务端约 3.27KB。 - 客户端发送、服务端不读:客户端内存上升到约 7.66KB,服务端约 5.47KB。
- 客户端发送、服务端读完:服务端回到约 3.24KB 左右。
- 服务端发送、客户端不读:两端也会因为发送/接收缓冲区产生额外开销。
TIME_WAIT:客户端约 0.5KB,服务端约 0KB,因为完整 socket 对象已经被回收,只保留轻量 time-wait 对象。
这里的“服务端约 0KB”不是说服务端进入 TIME_WAIT 永远不占内存,而是这次实验里的 TIME_WAIT 留在客户端这一侧。一般来说,主动关闭连接的一方更容易进入 TIME_WAIT,内存也主要由这一侧承担。
理解这张表要抓住一条主线:
6.1 空连接只需要“连接状态对象”
空连接没有未读数据、未发送数据,因此主要是:
- fd/file 相关对象
- socket inode 相关对象
- TCP 控制块
- 少量辅助对象
所以约 3KB 多。
6.2 有数据堆积时,会多出缓冲区开销
如果一端发送数据,而对端迟迟不读:
- 发送方可能积累发送缓冲区。
- 接收方可能积累接收缓冲区。
- 数据在内核中通常不是裸字节数组,还会挂在
sk_buff等结构上,因此实际占用可能大于用户写入的数据大小。
所以“连接数相同”,内存可能完全不同。100 万条空连接和 100 万条每条都有未读数据的连接,不是一个量级。
6.3 TIME_WAIT 为什么更省内存
TIME_WAIT 的作用是让 TCP 在主动关闭后还能处理迟到报文,避免旧连接报文污染新连接。进入 TIME_WAIT 后,内核不再需要完整的 struct sock/tcp_sock、文件对象、socket 对象等,只保留较小的 time-wait 结构和定时信息。
所以表里 TIME_WAIT 只有约 0.5KB。它比空 ESTABLISHED 轻很多,但如果数量达到几十万、几百万,仍然会消耗可观内存和哈希表资源。
七、TCP 收发缓冲区到底由谁控制
除了连接本身的内核对象,如果有数据收发,还需要接收缓冲区和发送缓冲区。缓冲区越大,越容易把高带宽、高 RTT 链路跑满;但连接数很大时,也越容易浪费内存。
7.1 内核自动调节
接收缓冲区相关:
sysctl net.ipv4.tcp_rmem
sysctl net.core.rmem_default
sysctl net.core.rmem_max
发送缓冲区相关:
sysctl net.ipv4.tcp_wmem
sysctl net.core.wmem_default
sysctl net.core.wmem_max
tcp_rmem 和 tcp_wmem 都是三个值:
最小值 默认值 最大值
Red Hat 文档也说明,net.ipv4.tcp_rmem 用于 read buffer,net.ipv4.tcp_wmem 用于 write buffer,三个值分别代表 minimum、default、maximum,并且单位是字节。3
注意:**这些值不是说每条连接一建立就立刻预分配 default 或 max 大小。**Linux 会根据实际收发、拥塞窗口、接收窗口、内存压力等情况动态增长和回收。
7.2 应用通过 setsockopt 控制
应用可以主动设置:
setsockopt(sockfd, SOL_SOCKET, SO_RCVBUF, ...)
setsockopt(sockfd, SOL_SOCKET, SO_SNDBUF, ...)
需要注意两个细节:
- 这会影响每个 socket 的缓冲区上限。
- Linux 通常会把应用设置值加倍,用于包含内核 bookkeeping 开销;过大的默认值在高连接数场景下会非常危险。
Red Hat 文档给了一个很直观的例子:如果应用为每个 socket 请求 256KiB 缓冲区,内核加倍后,100 万 socket 可能仅潜在缓冲区就需要 512GB 内存。4
所以高并发场景调参要谨慎:
- 长连接很多、单连接流量很小:不要盲目调大默认缓冲区。
- 高吞吐、长 RTT 链路:可以按带宽时延积 BDP 评估最大缓冲区。
- 业务主动设置
SO_RCVBUF/SO_SNDBUF时,要按连接数估算总内存上限。
八、一台机器最多能支撑多少 TCP 连接
这个问题没有单一答案,要分理论上限和实践瓶颈。
8.1 理论上看四元组
TCP 连接由四元组唯一确定:
源 IP、源端口、目的 IP、目的端口
服务端监听固定 IP 和端口时,主要变化来自客户端源 IP 和源端口。理论空间很大,不是简单的 65535。
客户端也不是绝对只能发起 65535 条连接:
- 如果目标服务端 IP/端口不同,同一个本地端口也可以参与不同四元组。
- 如果本机配置多个源 IP,可用四元组空间进一步扩大。
8.2 实践上先看这些瓶颈
真正的瓶颈通常是:
- 文件描述符限制:
fs.file-maxfs.nr_openulimit -n/etc/security/limits.conf
- 内存:
- 空连接约 3KB 多/端,百万连接就是数 GB 级别。
- 有数据堆积时,缓冲区会把内存迅速放大。
- 端口范围:
net.ipv4.ip_local_port_range
- conntrack、防火墙、代理层等额外状态:
- 如果经过 NAT、iptables conntrack,还会有额外内核状态。
- 应用层能力:
- 事件循环、线程模型、GC、业务处理速度。
推荐文章中的百万连接教程也强调:实验前需要调整文件描述符、端口范围,并准备合适的客户端方案。
九、排查和实验时的常用命令
连接数量:
ss -s
ss -ant state established | wc -l
ss -ant state time-wait | wc -l
内存概览:
cat /proc/meminfo
free -h
slab 对象:
slabtop
cat /proc/slabinfo | egrep 'TCP|sock|filp|dentry|tw_sock'
页分配与碎片:
cat /proc/buddyinfo
cat /proc/pagetypeinfo
socket 缓冲区:
sysctl net.ipv4.tcp_rmem
sysctl net.ipv4.tcp_wmem
sysctl net.core.rmem_default
sysctl net.core.rmem_max
sysctl net.core.wmem_default
sysctl net.core.wmem_max
文件描述符限制:
ulimit -n
sysctl fs.file-max
sysctl fs.nr_open
cat /proc/$(pidof your_process)/limits
十、推荐阅读的阅读顺序
原扩展阅读链接都保留在下面。建议按这个顺序读:
- 先读《一台 Linux 服务器最多能支撑多少个 TCP 连接?》:建立四元组、文件描述符、内存瓶颈的整体认识。
- 再读《花了七天时间测试,我彻底搞明白了 TCP 的这些内存开销》:重点看空连接、收发数据、
TIME_WAIT的内存差异。 - 然后读《动手测试单机百万连接的保姆级教程》:把理论落到实验参数和命令。
- 最后读客户端并发和 127.0.0.1 相关文章:补齐客户端角色、本机网络 IO 的认知。
本节的一个重要收获是:高并发连接数问题,不是单独的 TCP 问题,而是 TCP + 文件描述符 + slab 内核对象 + socket buffer + 应用模型共同决定的系统问题。
十一、扩展阅读
- 《深入理解 Linux 网络》第七章、第八章
- 漫画 | 花了七天时间测试,我彻底搞明白了 TCP 的这些内存开销!
- 漫画 | 一台Linux服务器最多能支撑多少个TCP连接?
- 漫画 | 理解了TCP连接的实现以后,客户端的并发也爆发了!
- 百看不如一练,动手测试单机百万连接的保姆级教程!
- 127.0.0.1 之本机网络通信过程知多少 ?
联网补充资料:
- Linux Kernel 文档:/proc 文件系统,含 buddyinfo/pagetypeinfo/slabinfo
- Linux manual:slabinfo(5)
- Red Hat 文档:system-wide TCP socket buffer settings
- Red Hat 文档:Increasing the system-wide TCP socket buffers
- Linux Foundation Wiki:TCP memory documentation
- 腾讯云镜像:花了七天时间测试 TCP 内存开销
- 腾讯云镜像:单机百万连接保姆级教程
- 腾讯云镜像:127.0.0.1 本机网络通信过程
Linux Kernel 文档中说明
buddyinfo可帮助诊断外部碎片,每一列代表某个 order 的可用页块数量,并且pagetypeinfo提供更多 page allocator 信息。 ↩︎slabinfo(5)描述了/proc/slabinfo的字段含义,包括active_objs、num_objs、objsize、objperslab、pagesperslab。 ↩︎Red Hat 文档说明
tcp_rmem和tcp_wmem分别用于 TCP 读/写 socket buffer,三个值分别是 minimum、default、maximum。 ↩︎Red Hat 文档提醒,过大的 socket buffer 会浪费内存;应用请求 256KiB buffer 且打开 100 万 socket 时,潜在内存可达到 512GB。 ↩︎