
一 、Linux中的路由表
路由表可以理解为一种网络命名空间级别的资源。每个 net namespace 都会有自己独立的一套网络栈资源,包括:
- IPv4/IPv6 协议栈相关状态
- 路由表,也就是 FIB,Forwarding Information Base
- loopback 设备
- iptables/netfilter 规则
/proc/sys/net/ipv4/*这类网络内核参数
所以严格来说,不是“一台 Linux 只有一套路由表”,而是“每个网络命名空间都有一套路由相关资源”。Docker、Kubernetes、容器网络能够隔离网络视图,靠的就是这种 namespace 级别的隔离。
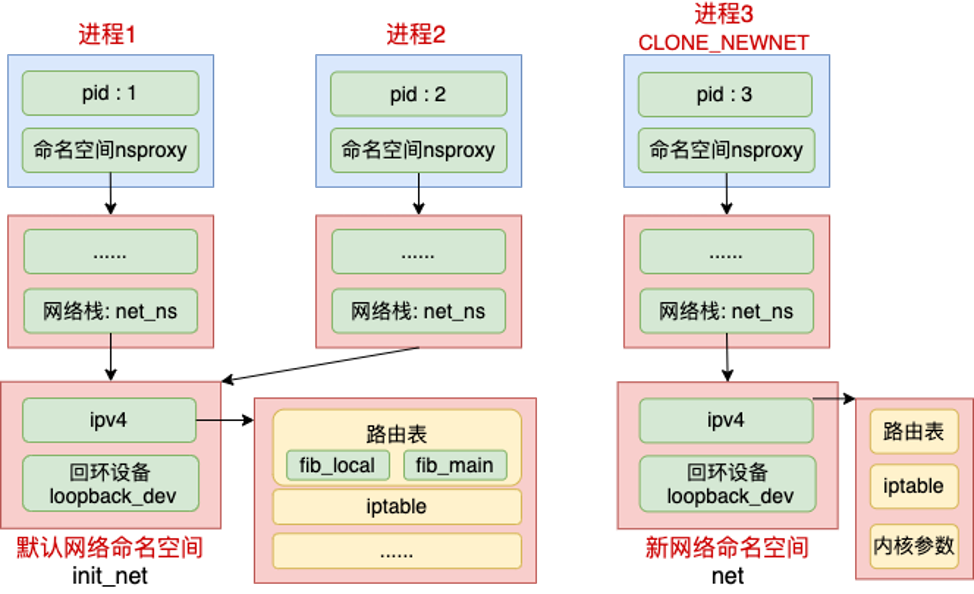
这张图表达的是:进程通过 nsproxy 引用不同类型的命名空间,其中网络命名空间对应内核里的 struct net。默认网络命名空间里有自己的 IPv4 栈、loopback 设备、路由表、iptables 等资源;通过 CLONE_NEWNET 创建新网络命名空间后,新 namespace 也会拥有独立的这套资源。
一个关键结论是:路由表不是进程私有的,而是进程所在的网络命名空间私有的。同一个网络命名空间里的多个进程看到的是同一套路由表;不同网络命名空间里的进程,看到的路由表可以完全不同。
来看下路由表在源码中定义:
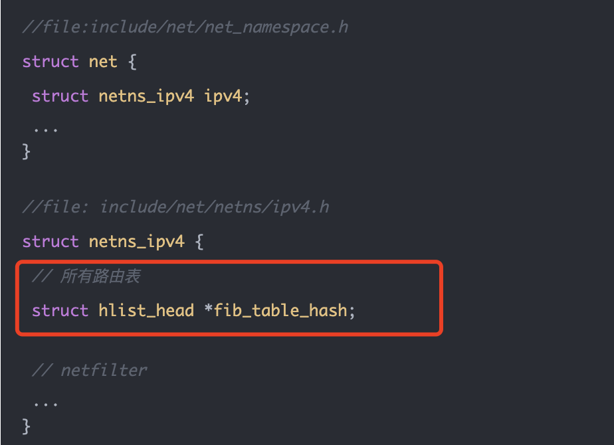
这张源码图展示了内核里的包含关系:
struct net {
struct netns_ipv4 ipv4;
}
struct netns_ipv4 {
struct hlist_head *fib_table_hash;
}
也就是说,struct net 表示一个网络命名空间;其中的 netns_ipv4 保存 IPv4 协议栈状态;fib_table_hash 指向这个 namespace 下的所有 IPv4 路由表。路由查找时,内核会从当前包所属的 struct net 出发,而不是全局找一张表。

这张图说明 Linux 可以支持多张路由表。常见表编号如下:
255 local:本地路由表,记录本机地址、广播地址等特殊路由,通常由内核自动维护。254 main:主路由表,大多数ip route add或发行版网络配置生成的普通路由都在这里。253 default:默认策略路由表,通常为空,保留给策略路由后处理。0 unspec:特殊编号,不代表日常使用的一张普通表。
如果开启 CONFIG_IP_MULTIPLE_TABLES,用户还可以在 /etc/iproute2/rt_tables 中增加自定义表名,例如图里的 200 eth0_tabl。但要注意:“有多张表”不等于“都会自动查”。真正查哪张表,还要看 ip rule 规则。

这张图用传统 route -n 命令展示默认路由表。各字段含义如下:
Destination:目的地址,可以是具体主机 IP,也可以是一个网段。Gateway:下一跳网关。0.0.0.0表示直连,不需要交给下一跳路由器。Genmask:子网掩码,和Destination一起描述匹配范围。Flags:U表示该路由可用,G表示需要经过网关。Iface:出接口,也就是最终从哪块网卡发出去。
现代 Linux 更常用 ip route 查看主路由表,例如:
ip route
ip route show table main
ip route show table local
排查“某个目的 IP 到底会怎么走”时,ip route get 比单纯看表更直观:
ip route get 192.168.2.25
它会把内核实际选出的下一跳、出接口、源地址等信息展示出来。

这张图展示了几类常见路由修改方式:
- 主机路由:只匹配一个具体 IP,例如
192.168.0.100/32。 - 网络路由:匹配一个网段,例如
192.168.1.0/24。 - 默认路由:兜底规则,目的地址没有匹配到更精确路由时使用。
路由匹配的核心规则是最长前缀匹配。比如同时存在 192.168.1.0/24 和 0.0.0.0/0,访问 192.168.1.20 会优先命中 /24,而不是默认路由。默认路由只是最后兜底,不是优先级最高。
二、网络收发过程与路由表
发送时
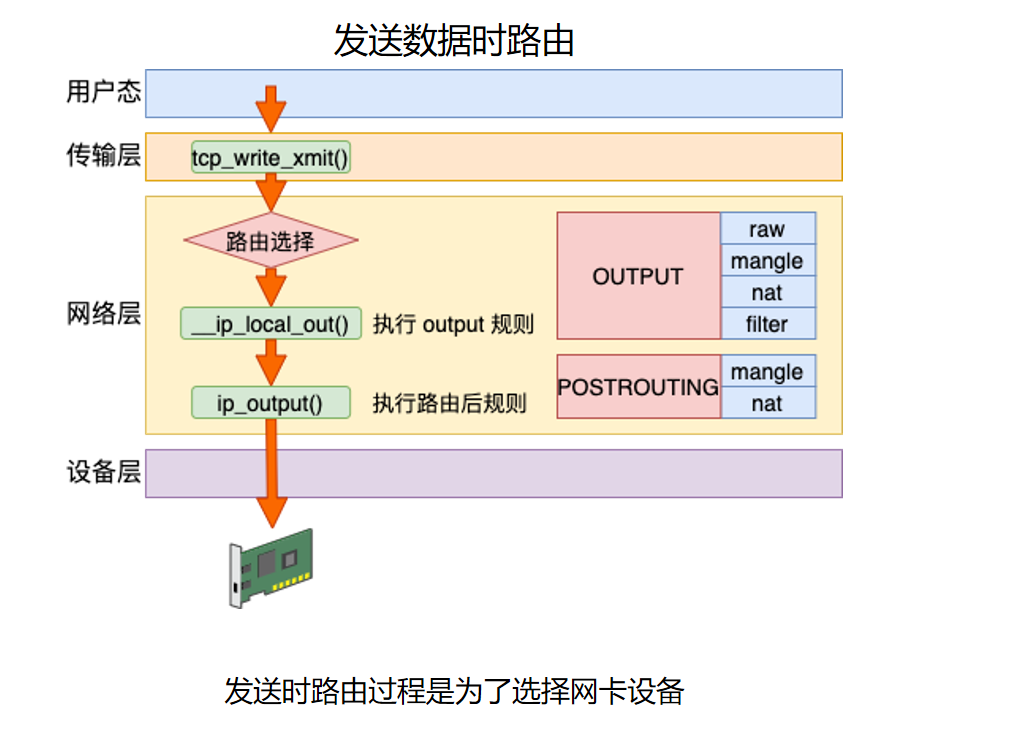
这张图说明本机主动发送数据时,路由发生在网络层。大致路径是:
用户态 send/write
-> 传输层 tcp_write_xmit()
-> 网络层 ip_queue_xmit()
-> 路由选择
-> __ip_local_out()
-> ip_output()
-> 设备层/网卡驱动
发送方向查路由的目的不是判断“是不是本机包”,而是决定:
- 该从哪块网卡发出
- 下一跳 IP 是谁
- 源 IP 该选哪个
- 这条路径的 MTU、TTL、输出函数等
dst信息是什么
图中还把 netfilter 的两个发送方向钩子标了出来:
OUTPUT:本机产生的包,在路由选择之后、真正输出之前经过。POSTROUTING:即将离开协议栈前经过,SNAT/MASQUERADE 常发生在这里。
核心源码
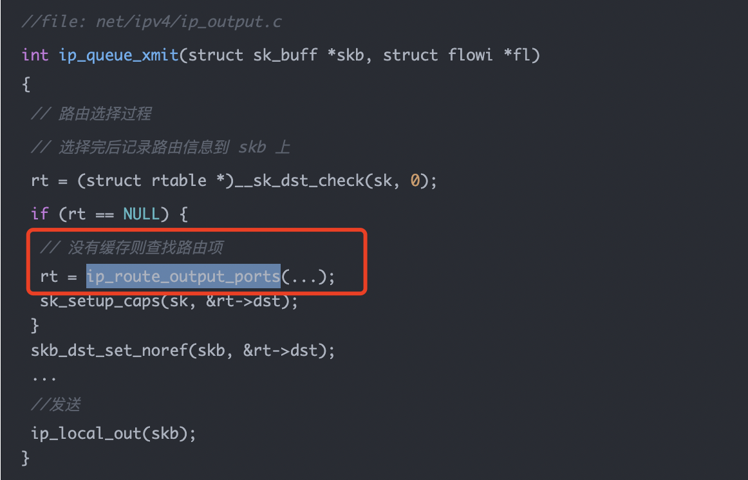
这张源码图的重点是 ip_queue_xmit()。它会先检查 socket 上有没有缓存好的路由,也就是 __sk_dst_check()。如果没有缓存,才调用:
ip_route_output_ports(...)
查到路由后,会通过 sk_setup_caps() 把路由结果缓存到 socket 上,并通过 skb_dst_set_noref() 把 dst 信息挂到当前 skb 上。这样后续 dst_output() 才知道该调用哪个输出函数、从哪个设备走。
这里有一个容易忽略的点:发送路径不是每个包都完整查一次路由。对于已经建立的 TCP 连接,路由结果可以缓存在 socket 上,后续发送可以复用,直到缓存失效。
接收过程
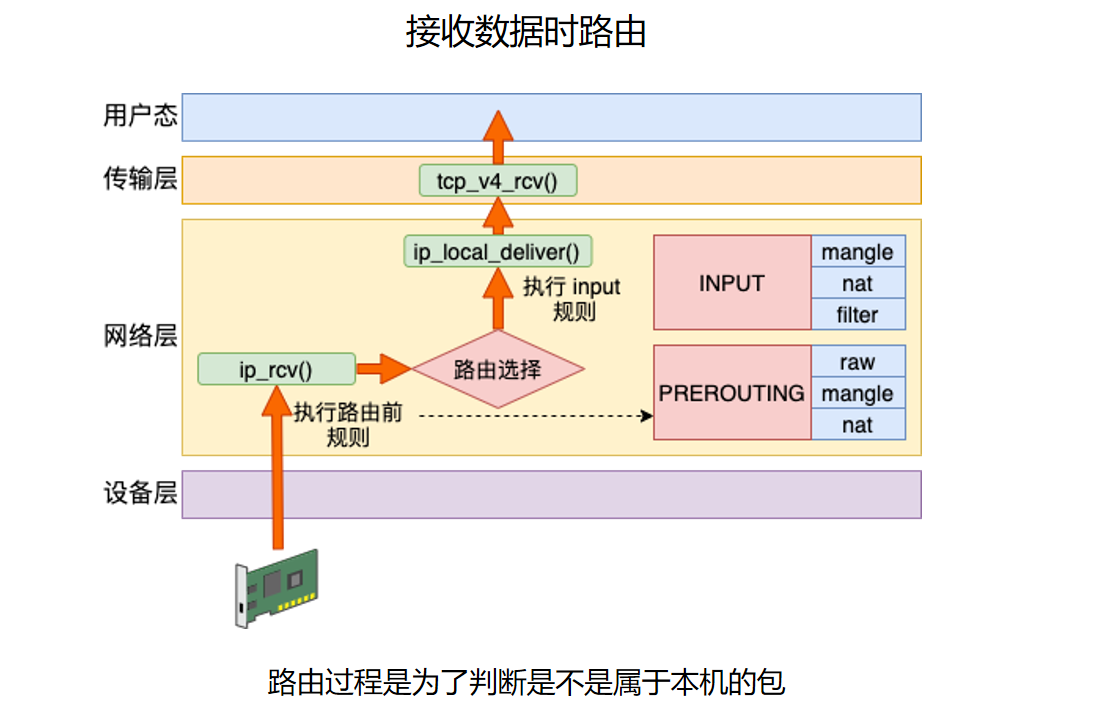
这张图说明接收方向也需要路由。大致路径是:
网卡收到包
-> 设备层
-> ip_rcv()
-> PREROUTING
-> 路由选择
-> ip_local_deliver()
-> INPUT
-> tcp_v4_rcv()
-> socket 接收缓冲区
接收方向查路由的核心目的,是判断这个包下一步该怎么处理:
- 如果目的地址属于本机,走
ip_local_deliver(),交给上层协议。 - 如果目的地址不属于本机,但允许转发,走
ip_forward()。 - 如果既不是本机包,也不允许转发,或者查不到合适路由,就丢弃。
这里的 PREROUTING 是路由前钩子,所以 DNAT 常放在这里。原因是:目的地址改完之后,再进行路由判断,内核才能把包转到新的目的地。
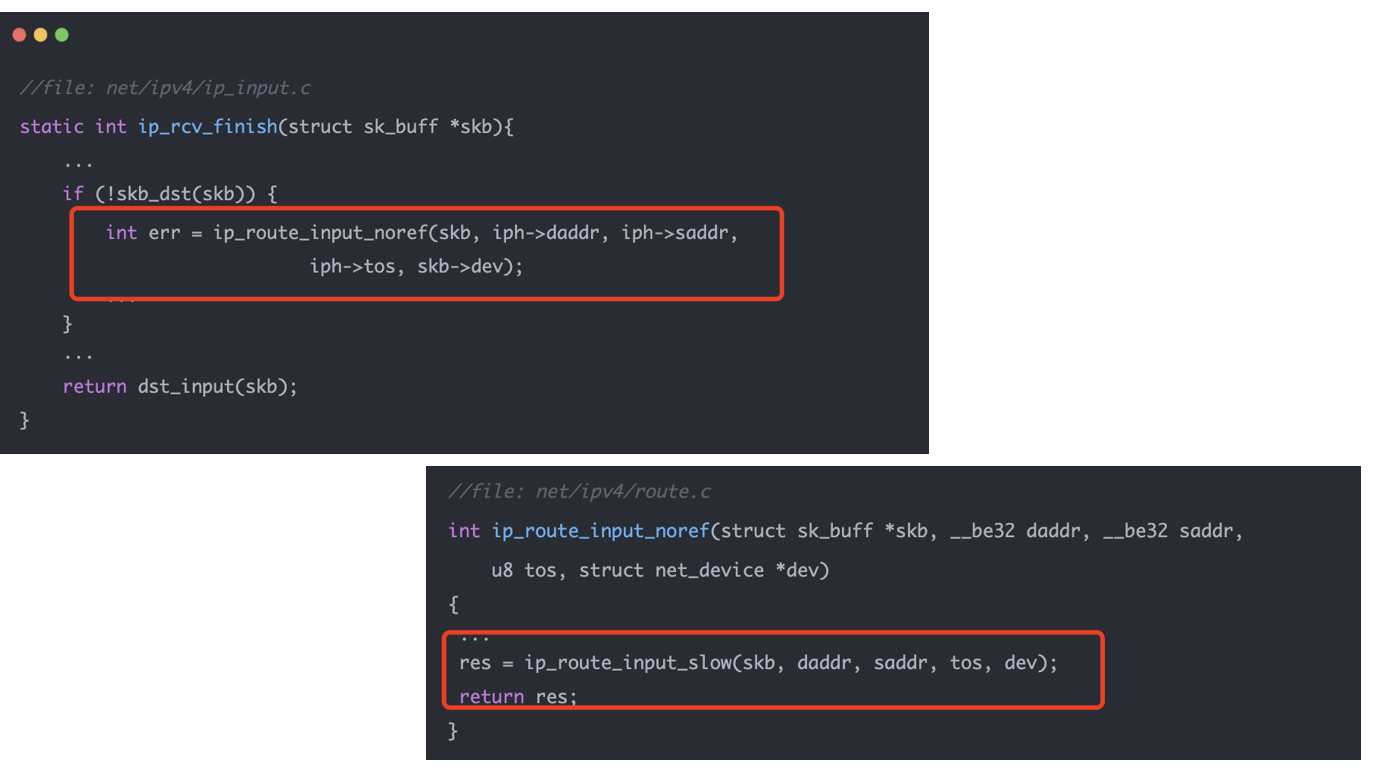
这张源码图展示了接收方向的关键入口。ip_rcv_finish() 中如果发现 skb 上还没有 dst,就会调用:
ip_route_input_noref(...)
进一步走到慢路径:
ip_route_input_slow(...)
接收方向的路由输入参数包括目的地址 daddr、源地址 saddr、TOS、入接口 dev 等。内核不仅看目的 IP,也会结合入接口、反向路径检查、是否本地地址、是否广播/组播等条件判断。
如果不是本机的包
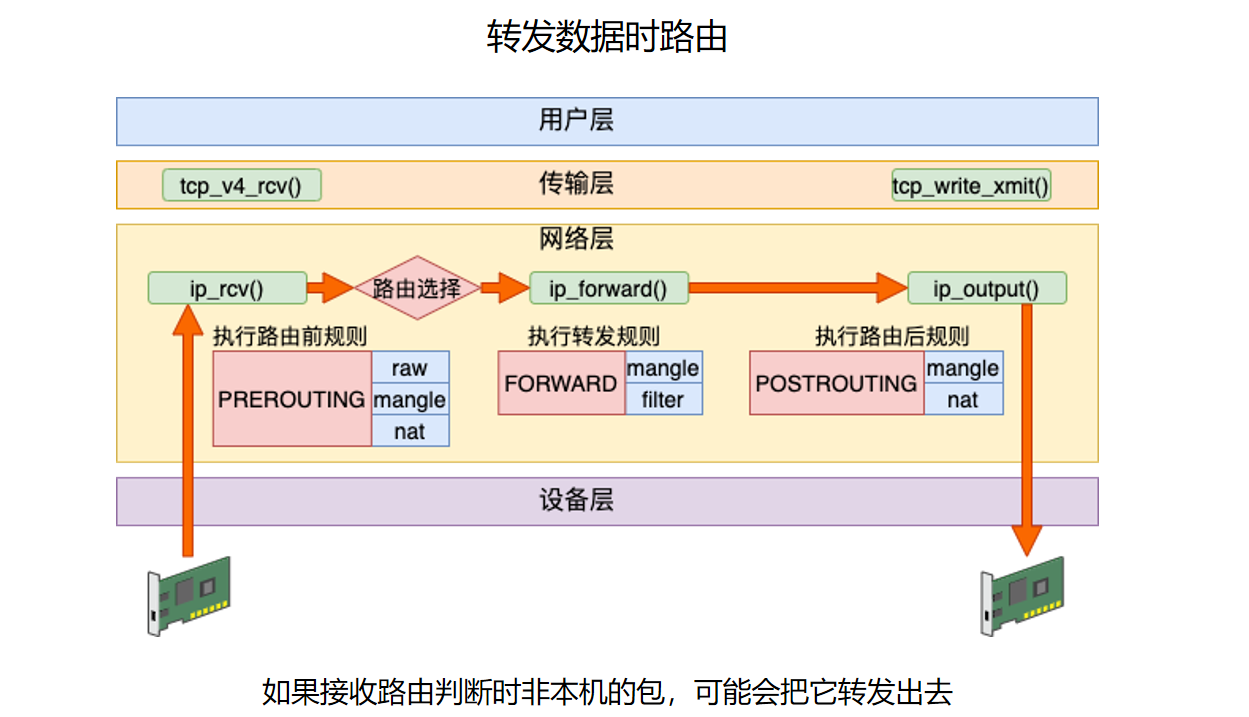
这张图展示转发路径。它不是本机应用程序收包,也不是本机应用程序发包,而是 Linux 像路由器一样把包从一个接口转到另一个接口。大致路径是:
ip_rcv()
-> PREROUTING
-> 路由判断:目的地址不是本机
-> ip_forward()
-> FORWARD
-> ip_output()
-> POSTROUTING
-> 设备层/网卡驱动
转发不是默认开启的。IPv4 转发需要打开:
sysctl -w net.ipv4.ip_forward=1
如果 ip_forward=0,即使路由表中知道下一跳,Linux 默认也不会帮别人的包做三层转发。
所以为什么需要路由:
- 发送过程需要判断用哪个网卡发送、下一跳是谁、源地址选哪个。
- 接收过程需要判断是否是发送给本机的包。
- 转发过程需要判断不是本机的包应该转发到哪里,或者应该丢弃。
三、路由查找的内核实现
首先明确:
- 发送过程调用
ip_route_output_ports来查找路由。 - 接收过程调用
ip_route_input_slow来查找路由。 - 两个方向最终都会进入 FIB 查询逻辑,核心是
fib_lookup。
没有开启多路由表的方式(若开启又是另外一种方式):
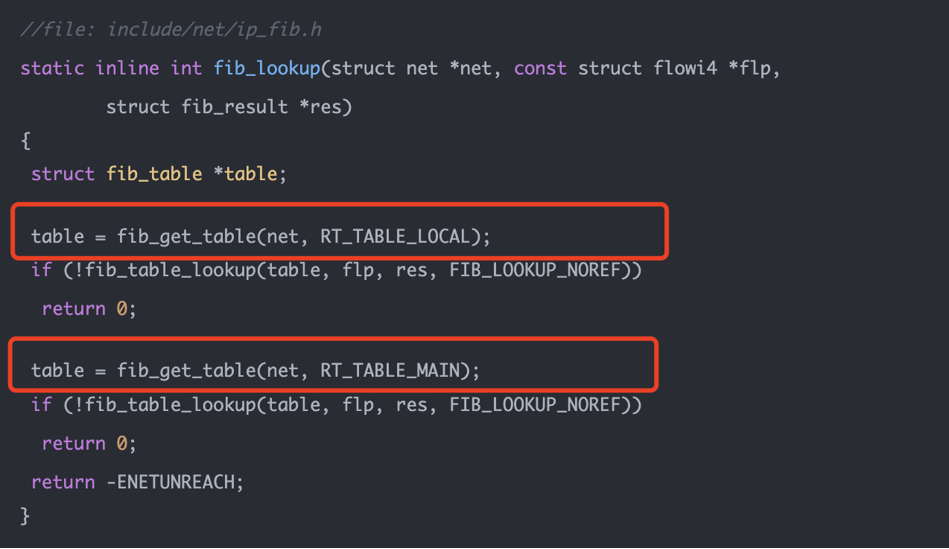
这张源码图展示的是未开启 CONFIG_IP_MULTIPLE_TABLES 时的简化逻辑:
fib_lookup()
-> 查 RT_TABLE_LOCAL
-> 命中则返回
-> 查 RT_TABLE_MAIN
-> 命中则返回
-> 返回 ENETUNREACH
也就是说:
- 先查
local表,再查main表。 - 命中后立即返回,不会继续往下查。
local表优先级高于main表。
这也是为什么访问本机 IP 往往不会真的从物理网卡出去,而是走 lo。因为本机地址会被内核自动放进 local 表,类型是 local,优先于 main 表里的普通路由。
如果开启了策略路由,也就是 CONFIG_IP_MULTIPLE_TABLES,逻辑会交给 RPDB,Routing Policy Database。此时 ip rule 决定先查哪张表。默认规则通常是:
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
这套默认规则和前面“先 local 后 main”的效果一致。区别是,开启策略路由后可以增加规则,例如按源 IP、fwmark、入接口等条件选择不同路由表。
收发缩略图
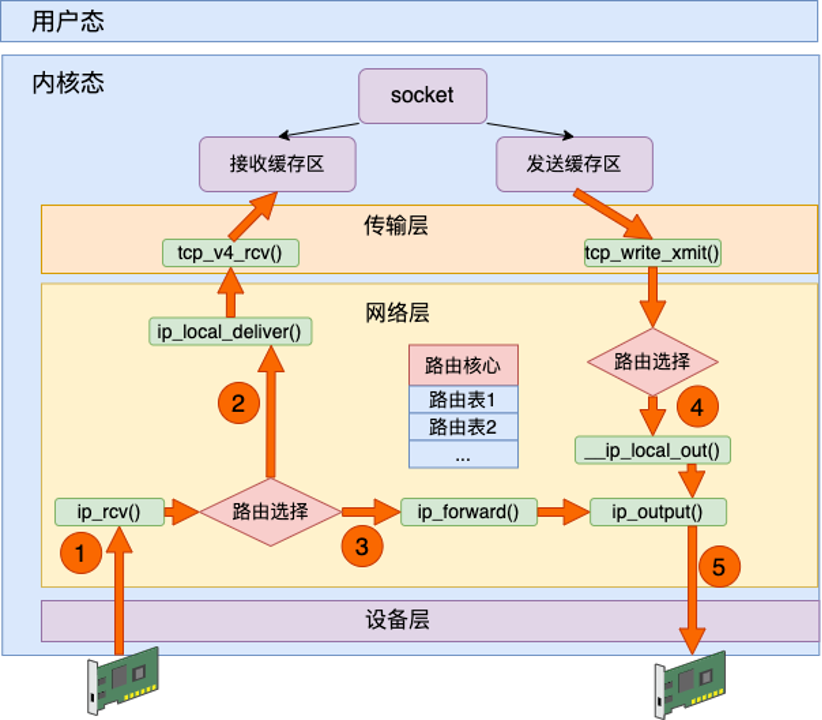
这张图把接收、本机发送、转发三条路径放在一起:
- 路径 1 和 2:接收给本机的包,经过
ip_rcv()、路由选择、ip_local_deliver(),最后进入 socket 接收缓冲区。 - 路径 3:不是本机的包,如果允许转发,则进入
ip_forward()。 - 路径 4 和 5:本机发包,传输层调用网络层,先路由选择,再从设备层发出。
图中间的“路由核心”可以理解为 FIB 查询结果。查询结果会变成 dst_entry/rtable,挂到 skb 上,也可能缓存到 socket 上。后续 dst_input() 或 dst_output() 会根据这个 dst 中的函数指针决定下一步调用 ip_local_deliver、ip_forward 还是 ip_output。
补充一个关键边界:路由表只决定三层路径,例如下一跳和出接口。真正把 IP 下一跳变成 MAC 地址,是 ARP/邻居子系统负责的。发送路径后面还会经过:
ip_finish_output2()
-> 查找或创建 neighbour
-> 必要时触发 ARP
-> 封装二层头
-> dev_queue_xmit()
所以“查到路由”并不等于“已经知道目的 MAC”。路由解决去哪儿,邻居子系统解决二层怎么送。
物理网络时代和容器网络时代
再来额外理解一个概念:
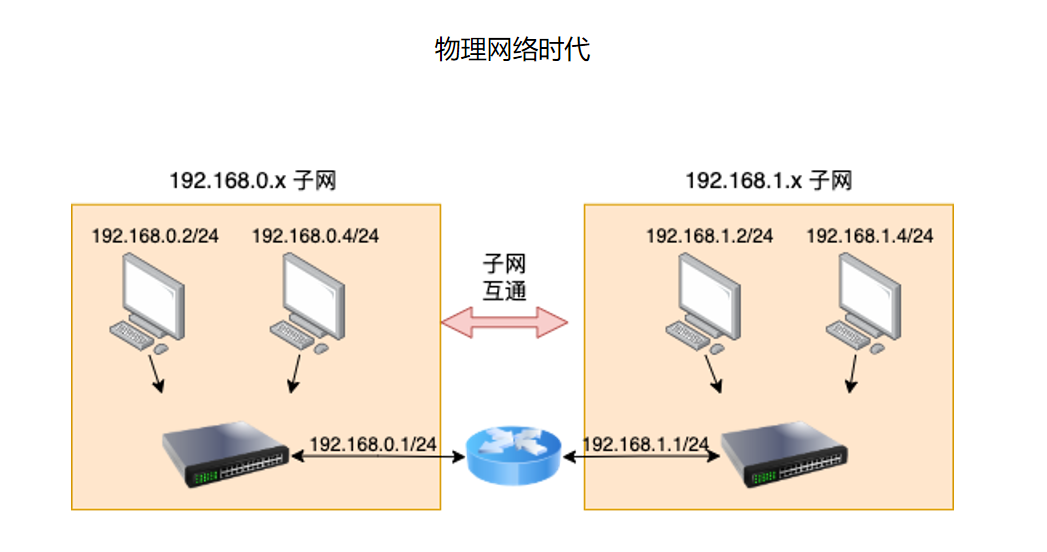
这张图是传统物理网络视角。两组不同网段的机器,例如 192.168.0.0/24 和 192.168.1.0/24,通常通过交换机和路由器互通。单台 Linux 服务器更多是终端角色,它只需要把包交给默认网关,不需要自己充当别的主机之间的路由器。
注意这里可以更准确地说:
- 同网段互通主要依赖二层交换和 ARP。
- 跨网段互通依赖三层路由器或三层交换设备。
- 普通物理服务器通常只配置本机路由和默认网关,不负责大量转发别人的包。
但是容器云时代之后:
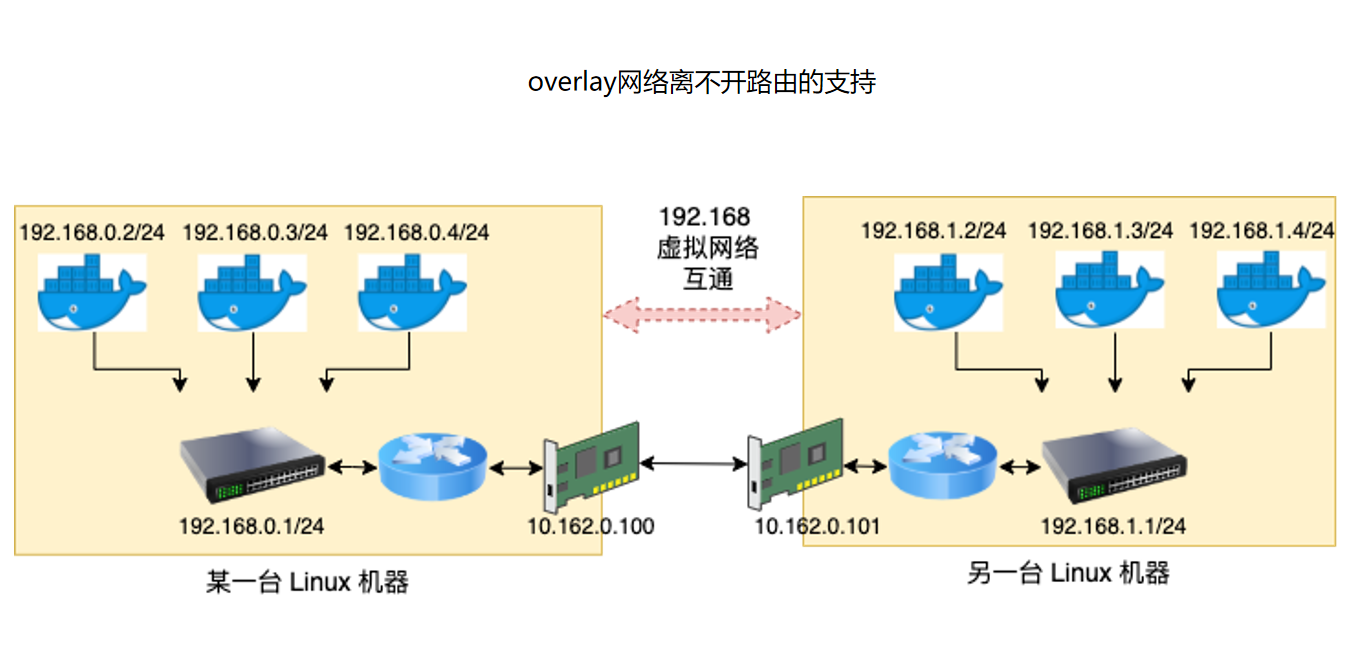
这张图展示了容器/overlay 网络下的问题。容器拥有自己的 IP,例如左侧宿主机上有 192.168.0.2/24、192.168.0.3/24,右侧宿主机上有 192.168.1.2/24、192.168.1.3/24。这些 IP 不一定在物理网络中真实可达,物理网络只认识宿主机网卡 IP,例如 10.162.0.100、10.162.0.101。
因此宿主机的 Linux 网络命名空间开始承担更重要的转发角色。常见 Docker bridge 链路是:
容器 eth0
-> veth pair
-> 宿主机 bridge,如 docker0/br0
-> 宿主机路由判断
-> eth0 物理网卡
容器访问外网时,常见做法是在宿主机上做 SNAT/MASQUERADE:
POSTROUTING -> MASQUERADE/SNAT
也就是把容器私有源地址改成宿主机地址,外部网络才知道如何回包。
外部访问容器服务时,常见做法是 DNAT:
PREROUTING -> DNAT
也就是外部请求先到宿主机 IP 和端口,再被改写到容器 IP 和端口。
overlay 网络表面上像是“跨宿主机容器处于同一张虚拟网络”,但底层仍然离不开路由和转发。它通常会把容器包封装进宿主机之间可达的物理网络包里,例如 VXLAN 这类隧道。外层包靠宿主机物理网络路由,内层包靠容器网络的转发表或路由逻辑。
所以,一切的原因就是需要建立容器的互通。而容器互通的本质,是让宿主机网络栈、路由表、iptables、bridge、veth、隧道等组件协同工作。
四、易混点总结
1. 路由表和 ARP 不是一回事
路由表回答的是:
- 目的 IP 应该往哪里走?
- 从哪个接口出去?
- 下一跳 IP 是谁?
ARP/邻居子系统回答的是:
- 下一跳 IP 对应的 MAC 地址是什么?
- 二层头应该怎么封装?
所以发包路径通常是先查路由,再查邻居。
2. iptables/netfilter 不是路由表
iptables 是基于 netfilter 钩子的规则系统。它不负责“最长前缀匹配”这种路由选择,但它可以在路由前后影响包:
PREROUTING:路由前,DNAT 常在这里改变目的地址。INPUT:确定是本机接收后进入。FORWARD:确定是转发包后进入。OUTPUT:本机发出的包会经过。POSTROUTING:发出前最后阶段,SNAT/MASQUERADE 常在这里发生。
因此 iptables 可以改变路由判断的输入,也可以在路由判断后决定是否放行,但它本身不是路由表。
3. tcpdump 和 netfilter 的先后顺序要分方向看
接收方向上,tcpdump 的抓包点在网络设备层,通常早于 IP 层的 PREROUTING。因此即使包后面被 netfilter 丢弃,tcpdump 仍然可能抓到。
发送方向上,包先经过协议栈和 netfilter,再到网络设备层的抓包点。如果包在 OUTPUT 或 POSTROUTING 被丢弃,tcpdump 可能抓不到它。
这也是排查防火墙问题时很容易误判的地方:抓不到包不一定代表应用没发,也可能是还没到抓包点就被规则处理掉了。
4. local 表通常不是手工维护的主战场
local 表记录本机地址、广播地址等特殊路由,通常由内核随着地址配置自动维护。日常添加普通路由,大多数情况下改的是 main 表。
查看时可以用:
ip route show table local
ip route show table main
ip rule show
如果看到访问本机 IP 走 lo,不要觉得奇怪,这是 local 表优先匹配的正常结果。
五、扩展阅读
- 《深入理解 Linux 网络》
- 来,今天飞哥带你理解 iptables 原理
- 图解 Linux 网络包接收过程
- 25 张图,一万字,拆解 Linux 网络包发送过程
- 用户态 tcpdump 如何实现抓到内核网络包的?
参考交叉阅读: