
本文是在做API网关项目的第13章时,需要用到Java SPI机制的思想,由于笔者以往没有了解过这一块的东西,所以在学习相关的内容后,对其做了一个梳理。
SPI机制简介
SPI 即 Service Provider Interface :字面意思就是:“服务提供者的接口”,是一种JDK内置的动态加载实现扩展点的机制。SPI将接口和接口的实现分离开来,将调用方和服务方解耦。上层代码只依赖一个服务接口(Service Interface),而真正的服务实现(Service Provider)可以在运行时被发现与装配,不用改动调用方代码、不用手动 new 指定实现。这个机制有一些类似于IOC的控制反转(将组件装配的控制权移交给了程序之外),提供了一个服务提供者,在代码运行的过程中,若要使用到调用的服务接口,只需要将接口类型交给服务提供者,服务提供者会加载出改服务接口的所有实现类的对象,最后给调用方使用。
在这里我们要区分一下SPI 与 API,IOC的区别
API:调用方直接依赖具体类或工厂,耦合更紧(接口和实现类都在实现方的包中);
SPI:调用方只依赖接口,运行时自动发现实现,零改动热插拔。(接口和实现类是不在一起的)
IoC 容器(Spring 等):更强的装配与生命周期管理;Spring 也有自己的“SPI/自动装配”机制(主要是通过 配置文件(spring2.x 时META-INF/spring.factories)+ 反射 + IOC 容器 来实现自动发现和装配。),但它和 JDK
ServiceLoader是两套体系。
而SPI的核心组成部分主要有四个部分:
服务接口(Service Interface)
定义功能契约,例如:
java.sql.Driver。
服务实现(Service Provider)
任意类库/JAR 可以提供该接口的实现,例如 MySQL JDBC 驱动。
服务加载器(ServiceLoader)
JDK 提供的工具类
java.util.ServiceLoader,用来扫描和实例化配置的实现类
配置文件
路径固定:
META-INF/services/文件名:接口的全限定名,例如
META-INF/services/java.sql.Driver文件内容:一行一个实现类的全限定名
入门案例
项目结构如下
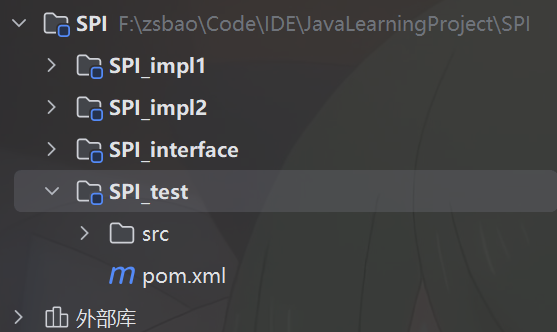
Service Interface
首先我们创建一个SPI_interface模块,在其中设置一个接口
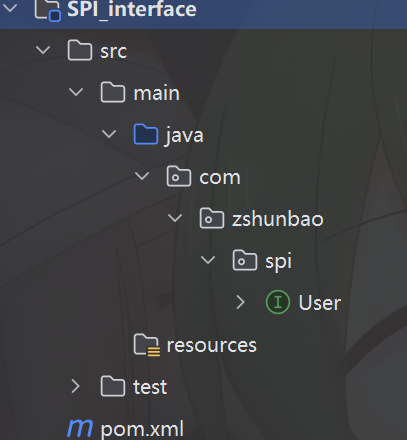
package com.zshunbao.spi;
/**
* @program: SPI
* @ClassName User
* @description: SPI 演示接口
* @author: zs宝
* @create: 2025-08-24 09:06
* @Version 1.0
**/
public interface User {
public void sayName();
}
这个就是我们后续的服务接口。
Service Provider
SPI机制中接口与其实现是分离的,解耦的。因此我们在这里再创建两个专门针对于次接口的实现模块
首先是SPI_impl1
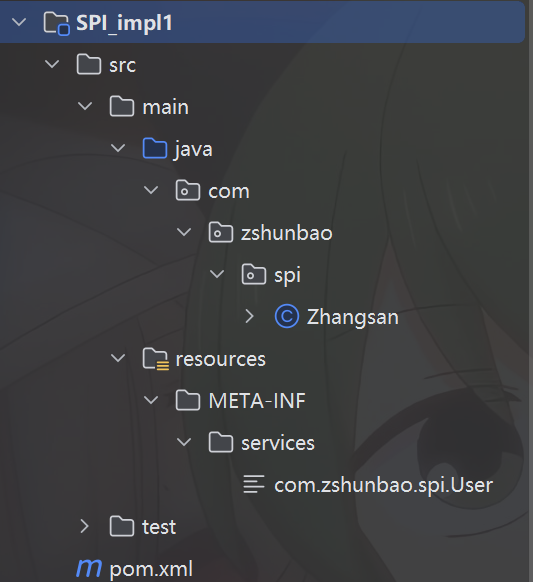
服务接口的实现类为
package com.zshunbao.spi;
/**
* @program: SPI
* @ClassName Zhangsan
* @description:
* @author: zs宝
* @create: 2025-08-24 09:08
* @Version 1.0
**/
public class Zhangsan implements User{
@Override
public void sayName() {
System.out.println("我是张三");
}
}
需要注意的是Java SPI通过 META-INF/services 下的文件来声明实现类,JDK 提供 ServiceLoader 去加载。
因此我们在resources目录下会创建 META-INF/services 目录,并创建文件com.zshunbao.spi.User(这里注意创建的文件名必须为接口的源根路径,不可更改,后续在源码分析中会看到加载时是依靠这个来确定资源的),其中写的就是有关实现类的来自源根的路径
com.zshunbao.spi.Zhangsan最后无论是哪一个实现模块都需要引入服务接口的依赖
<dependency>
<groupId>com.zshunbao.spi</groupId>
<artifactId>SPI_interface</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>同理我们创建第二个实现模块SPI_impl2
实现类为
package com.zshunbao.spi;
/**
* @program: SPI
* @ClassName Zhangsan
* @description:
* @author: zs宝
* @create: 2025-08-24 09:08
* @Version 1.0
**/
public class LIsi implements User{
@Override
public void sayName() {
System.out.println("我是李四");
}
}
`resources/META-INF/services 下创建com.zshunbao.spi.User文件
com.zshunbao.spi.LIsi测试验证
现在我们就可以基于Java SPI动态加载到接口的实现类并执行了,我们写一个简单的测试模块做验证。我们新建一个测试模块,把他当作服务调用方
pom文件中引入接口和实现模块
<dependencies>
<dependency>
<groupId>com.zshunbao.spi</groupId>
<artifactId>SPI_interface</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.zshunbao.spi</groupId>
<artifactId>SPI_impl1</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.zshunbao.spi</groupId>
<artifactId>SPI_impl2</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>测试类
package com.zshunbao.spi;
import java.util.Iterator;
import java.util.ServiceLoader;
/**
* @program: SPI
* @ClassName SPITest
* @description:
* @author: zs宝
* @create: 2025-08-24 09:16
* @Version 1.0
**/
public class SPITest {
public static void main(String[] args) {
ServiceLoader<User> userLoader = ServiceLoader.load(User.class);
Iterator<User> userIterator = userLoader.iterator();
while (userIterator.hasNext()){
User user = userIterator.next();
user.sayName();
}
}
}
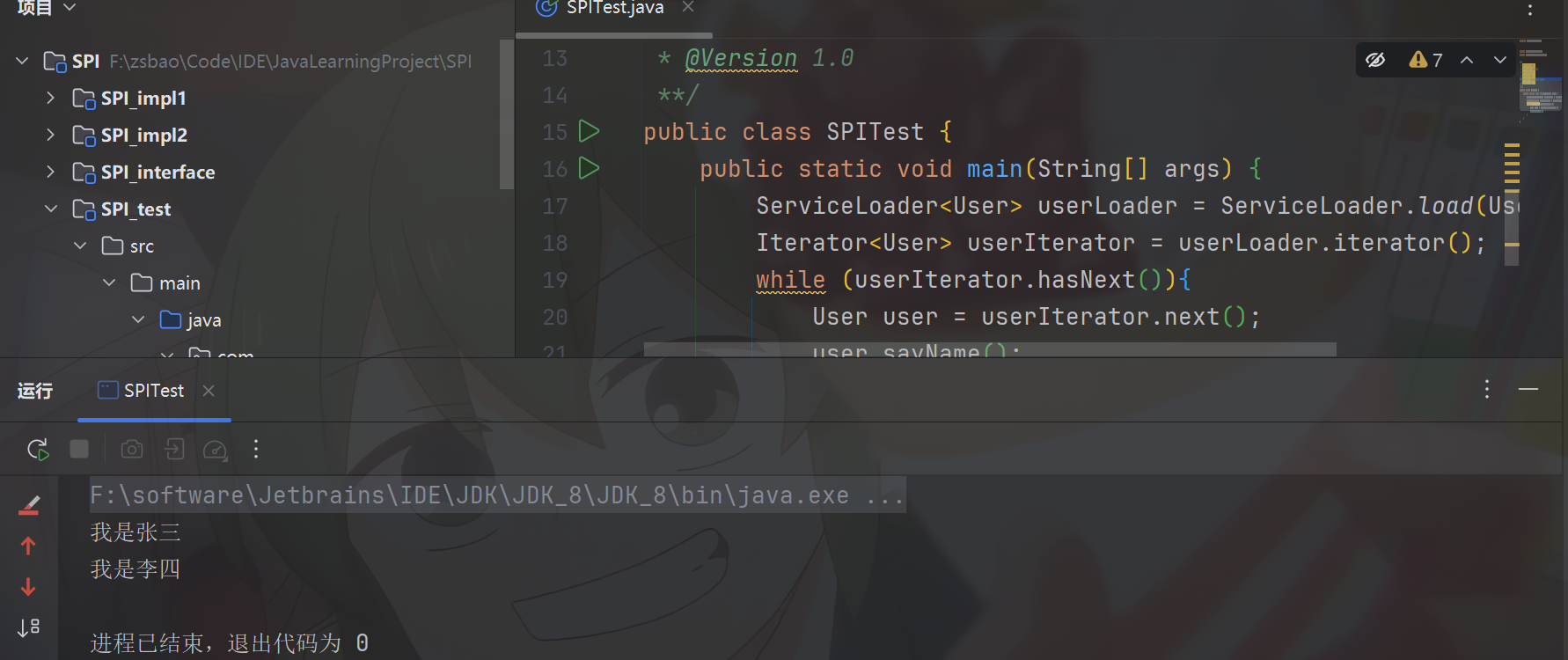
执行上述代码,ServiceLoader会加载到META-INF.services目录下的配置文件,找到对应接口全名文件,读取文件中的类名,在通过反射将实现类实例化。既然已经有了子类的实例化对象,那么就可以通过父类引用指向子类对象,从而调用到子类的对应方法。
运行结果如下
源码分析
接下来,我们就来打上断点,看一看Java SPI的源码到底是一个怎样的执行机制
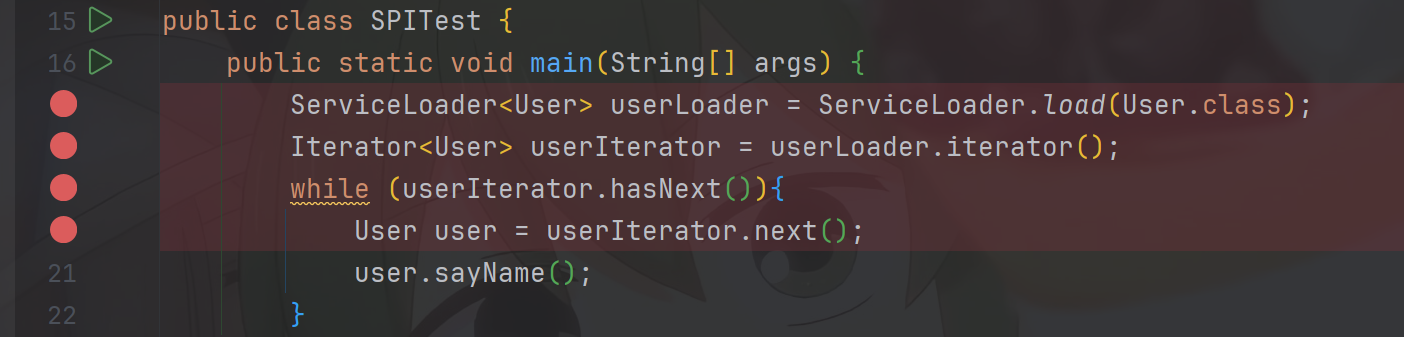
debug运行
ServiceLoader.load
我们进入这段代码
来到了ServiceLoader.java类下的
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}在这里Thread.currentThread().getContextClassLoader();加载了当前环境的上下文信息,接着我们进入ServiceLoader.load(service, cl);中去看看到底干了些什么,进入ServiceLoader#load函数
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}我们返现这里其实是在调用ServiceLoader的一个构造函数,返回了一个新的ServiceLoader对象,我们进入这个构造函数
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}我们发现,这个构造函数里面函数,我们再点击进入的时候,它并不会直接进入这个构造函数之中,而是先给了我们一个ServiceLoader的属性变量providers,这个变量在初次加载是是空的,而且源码的注解表示这是专门存储服务实例(在这里是存储User接口实现类对象)的集合
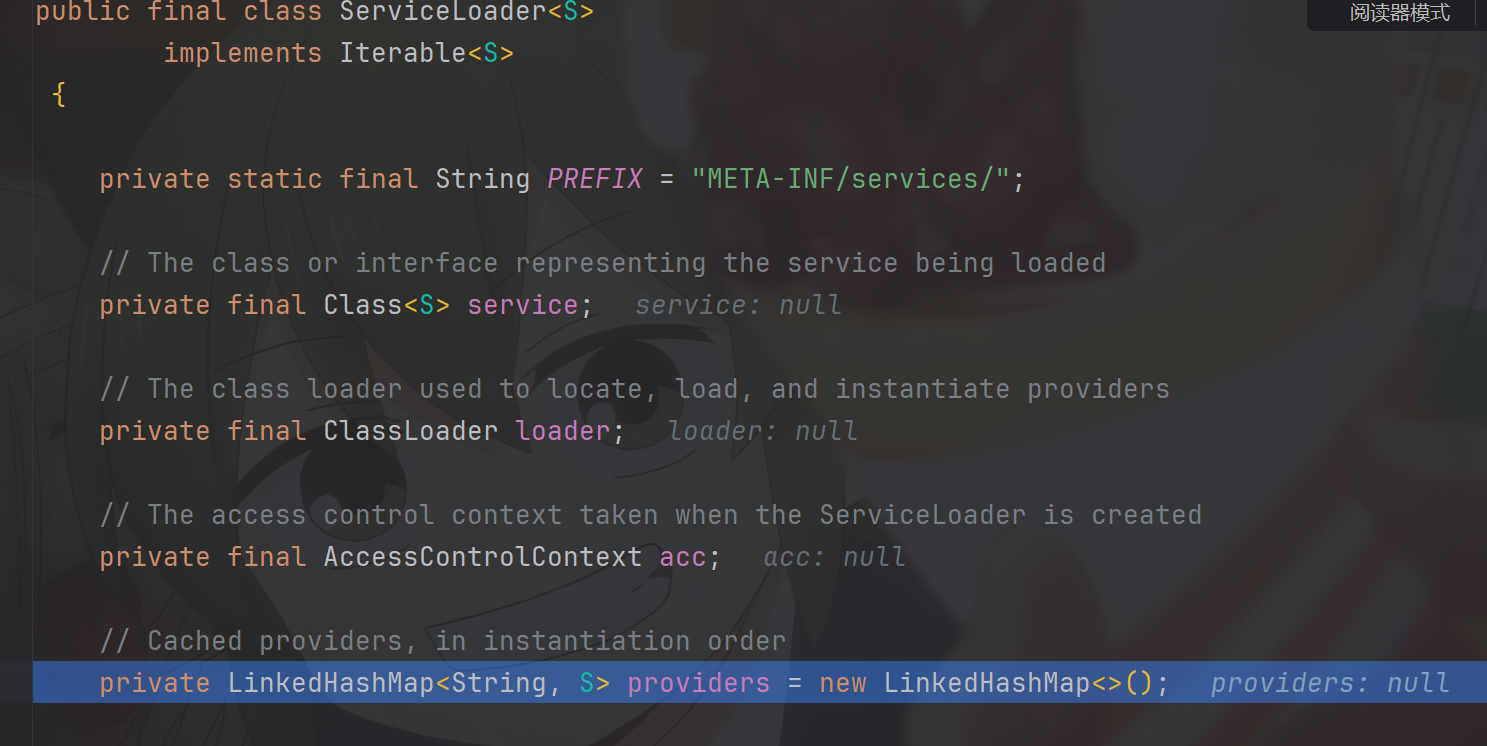
,接下来我们debug再点击下一步,正式进入private ServiceLoader(Class<S> svc, ClassLoader cl)构造函数当中
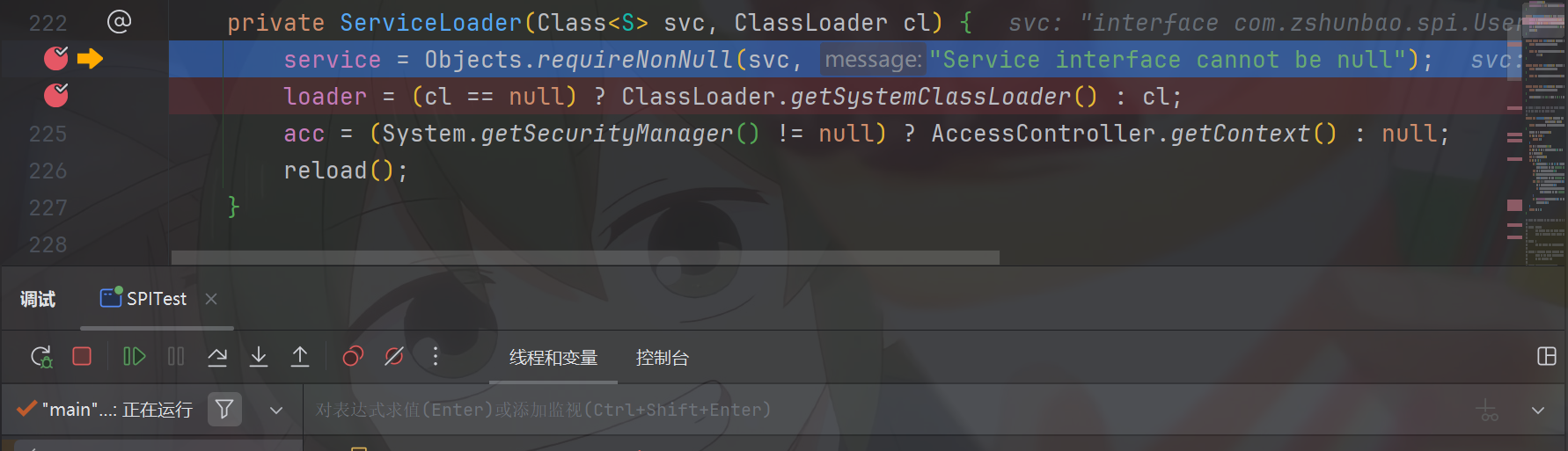
在其中判断svc,cl是否为空,然后将非空的赋值给service,loader。其中acc是专门用在服务实现类的安全权限访问方面的,我们这里没有涉及到acc,所以暂时不要考虑这个东西。
接着我们进入其中的reload方法
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}在这个里面,我们发现它将专门存储服务实例(在这里是存储User接口实现类对象)的集合providers清空,并实例化ServiceLoader.java类的lookupIterator属性,这里我们粘贴一下ServiceLoader中的属性
public final class ServiceLoader<S>
implements Iterable<S>
{
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
private final Class<S> service;
// The class loader used to locate, load, and instantiate providers
private final ClassLoader loader;
// The access control context taken when the ServiceLoader is created
private final AccessControlContext acc;
// Cached providers, in instantiation order
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// The current lazy-lookup iterator
private LazyIterator lookupIterator;
接着我们来看一下new LazyIterator(service, loader);,LazyIterator是ServiceLoader的一个内部类
private class LazyIterator
implements Iterator<S>
{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
....................LazyIterator实现了Iterator迭代器接口,根据类名可以看出,这是一个Lazy懒加载形式的迭代器。延迟加载,说明项目启动时不会立马加载,而是需要被用到的时候,才会动态去加载。实现了Iterator迭代器接口的LazyIterator对象,就具备延迟加载的功能.
所以现在来看reload方法也就是
清空providers
将ServiceLoader的属性lookupIterator初始化为一个LazyIterator
当reload函数执行完后,ServiceLoader.load(User.class)也就过完了,接下来的就是一只往会返回结果ServiceLoader
最后来总结下ServiceLoader.load(User.class)的作用吧
根据目标接口类初始化创建一个ServiceLoader实例对象
这个实例对象将拥有当前上下文语境所有信息loader,并且清空了属性字段providers,同时实例化了其属性字段的lookupIterator为一个懒加载器。(这里先写一下:这个懒加载器后续在使用时,会遍历我们的指定目录
META-INF.services下的所有文件,将文件中的类实例化,并将其按类名,示例的形式存储在providers中)
userLoader.iterator()
接下来我们就进入Iterator<User> userIterator = userLoader.iterator();看看这一句会干些什么
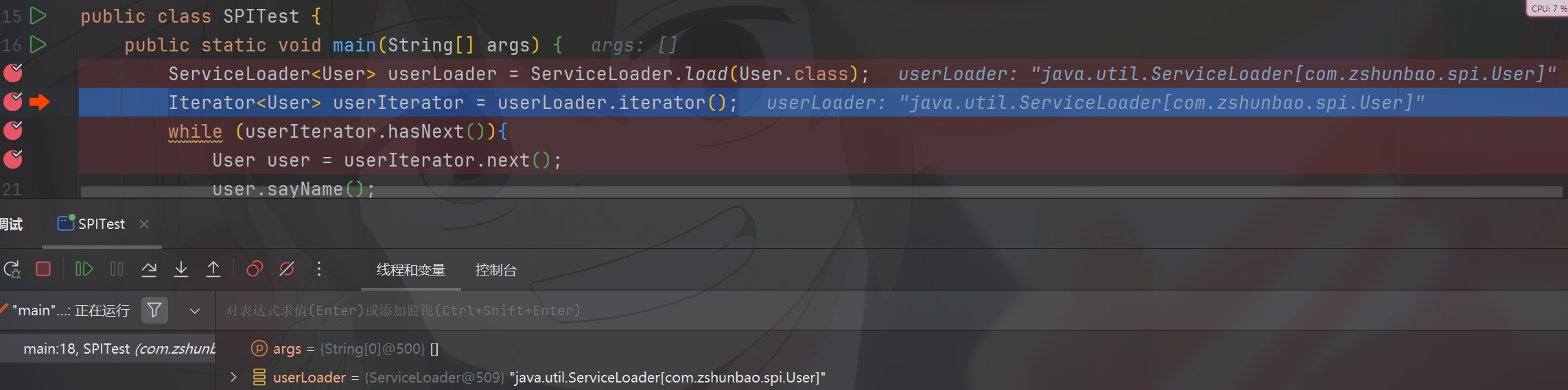
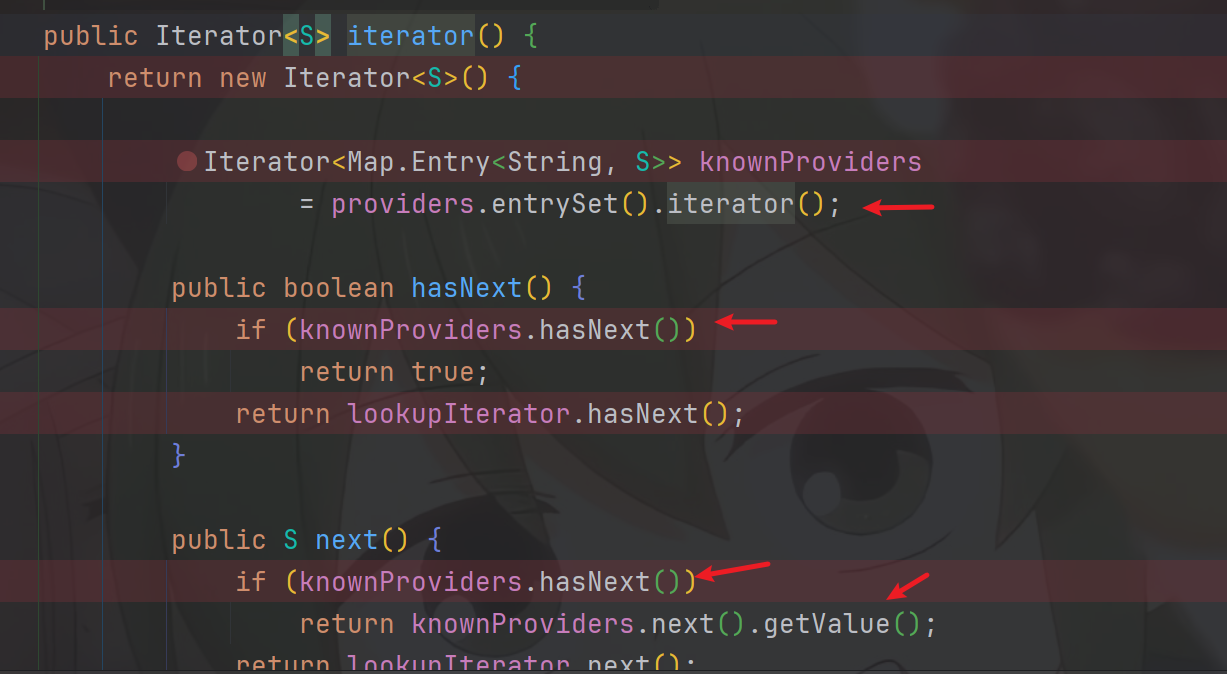
debug进入后发现他直接给我们创建了一个匿名的Iterator对象,同时为我们提供了一个knownProviders,这个knownProviders是由providers提供而来。以及提供hasNext,和函数
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}然后就将这个匿名的Iterator对象返回给我们拿到。这里其实看完后面的分析你会发现重点不在于匿名类叫什么,而在于匿名类有hasNext和next方法可以让我们调用到ServiceLoader的懒加载类变量lookupIterator中去,但是又尽量避免我们能够直接操纵到它。
接下来我们就去看入门案例中while循环中的逻辑是怎样运行的
userIterator.hasNext()
进入循环
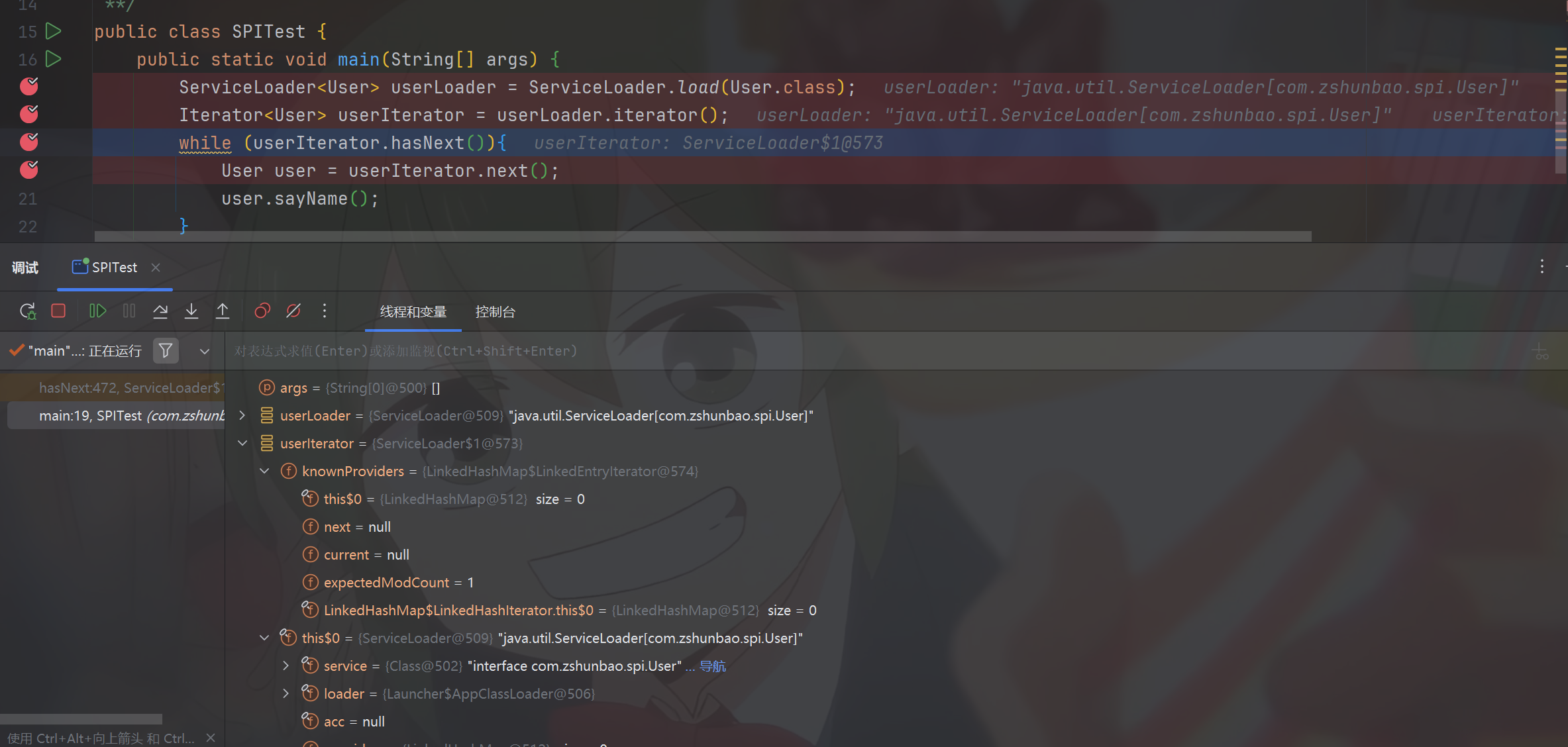
debug进入
函数来到了我们之前创建的匿名Iterator对象对象中的hasNext函数
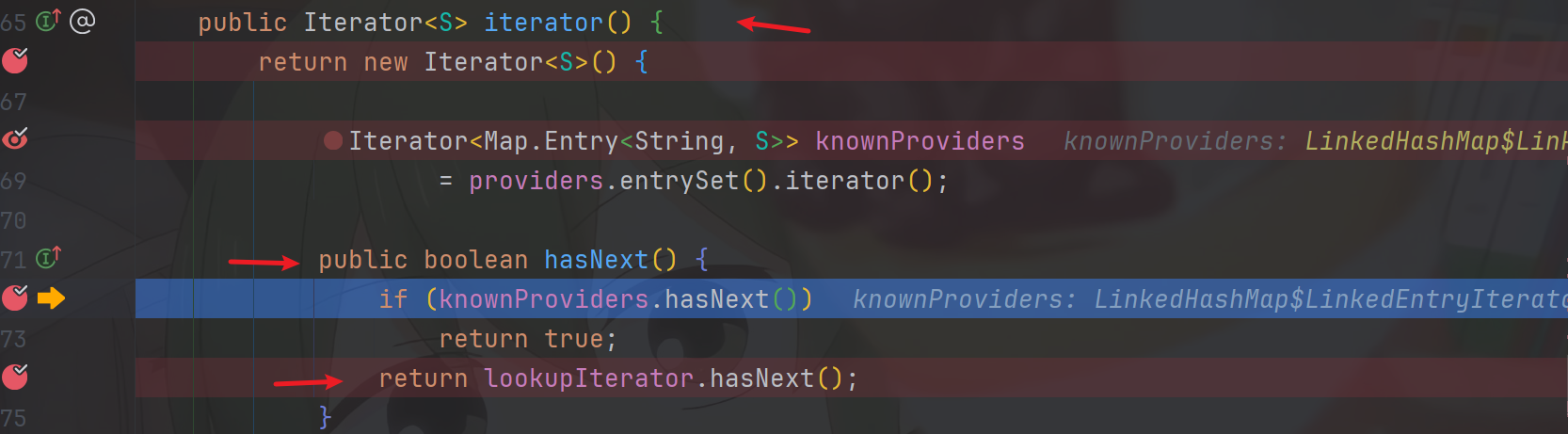
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}由于我们的providers是空的,所以knownProviders.hasNext()也是空的,因此逻辑进入ServiceLoader类的属性lookupIterator的lookupIterator.hasNext()中,即ServiceLoader类的内部私有类LazyIterator的hasNext函数中去
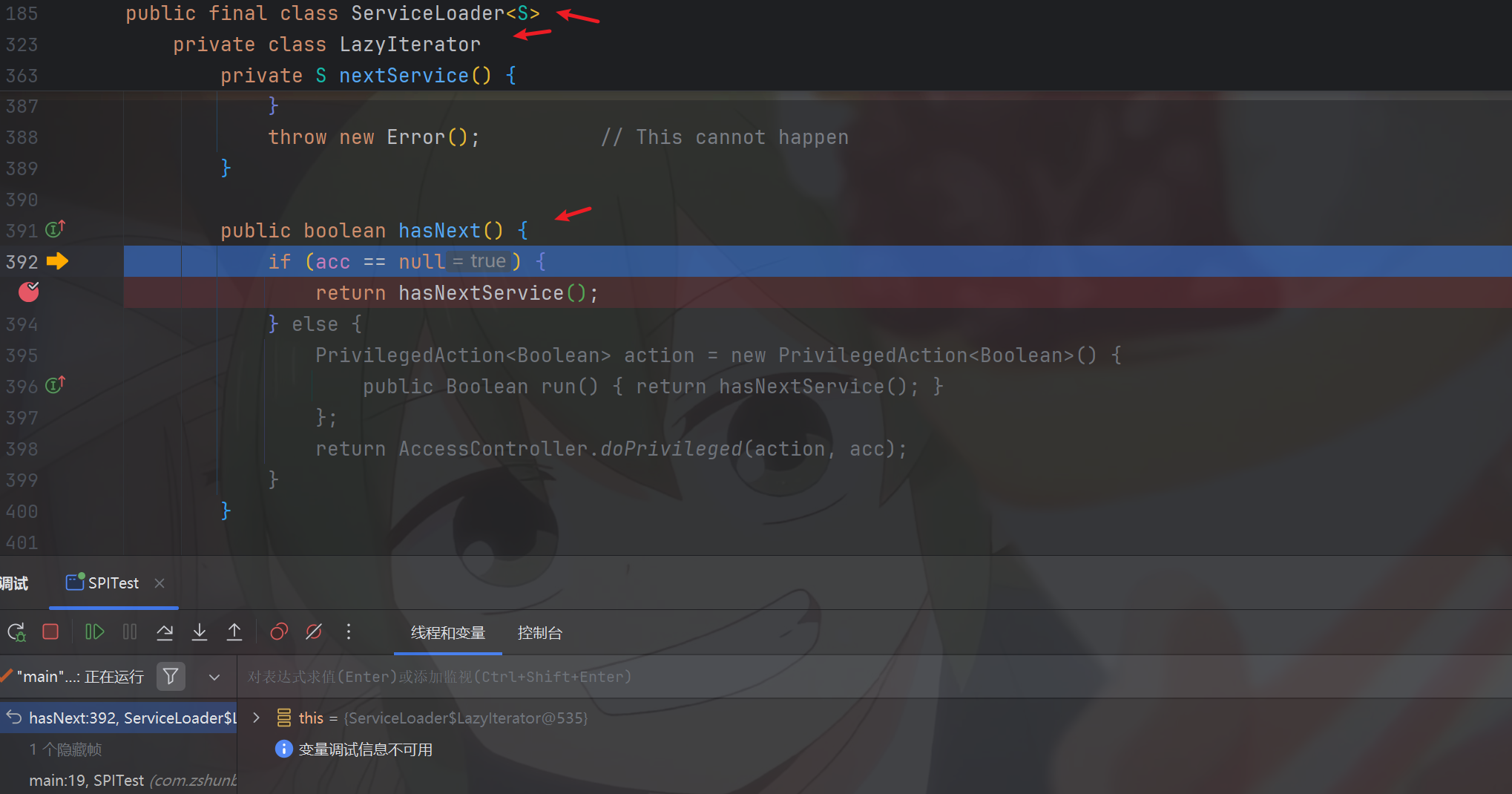
由于我们没有使用过安全相关的东西,因此acc为null,我们接着进入hasNextService()函数的逻辑

private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}我们这里会先进入configs == null的逻辑中去,在其中我们发现我们会在这个里面将扫描META-INF/services/com.zshunbao.spi.User扫描出来,并加载到对应的文件资源(注意fullName的拼接方式,它是用的PREFIX + service.getName(),其中PREFIX是写死的META-INF/services,而service是我们定义的接口的class,它在getName时用的是接口的源根路径)
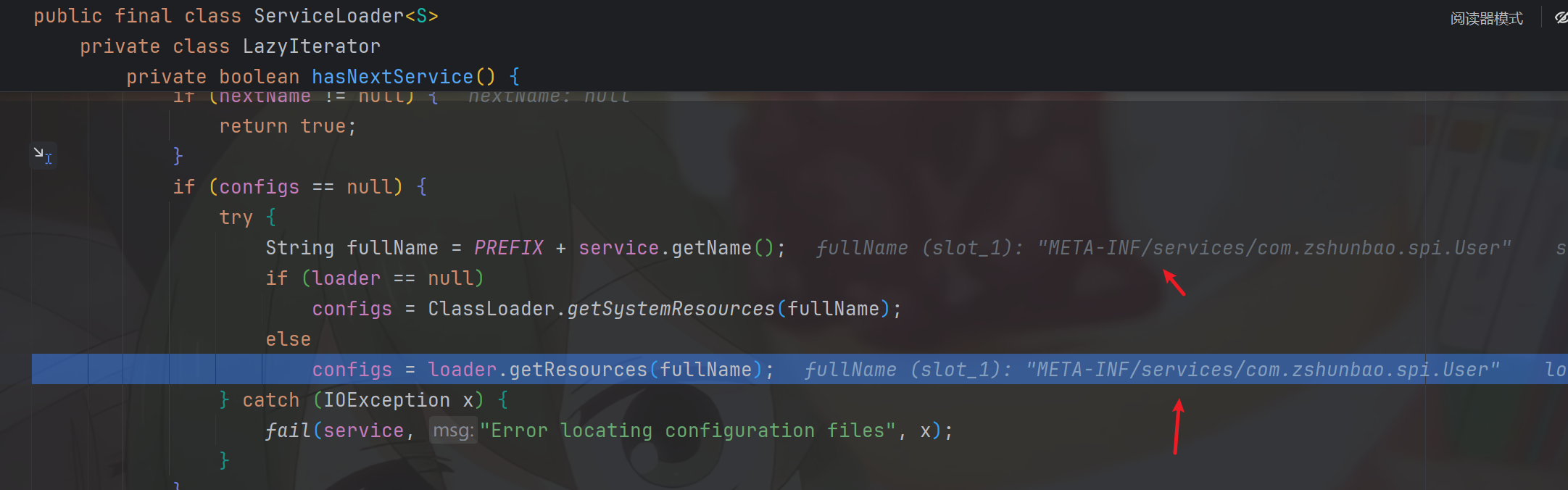
获得文件资源后,进入下面的while循环
private class LazyIterator
implements Iterator<S>
{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private boolean hasNextService() {
.............................
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
........................
然后会来到
pending = parse(service, configs.nextElement());之中
private Iterator<String> parse(Class<?> service, URL u)
throws ServiceConfigurationError
{
InputStream in = null;
BufferedReader r = null;
ArrayList<String> names = new ArrayList<>();
try {
in = u.openStream();
r = new BufferedReader(new InputStreamReader(in, "utf-8"));
int lc = 1;
while ((lc = parseLine(service, u, r, lc, names)) >= 0);
} catch (IOException x) {
fail(service, "Error reading configuration file", x);
} finally {
try {
if (r != null) r.close();
if (in != null) in.close();
} catch (IOException y) {
fail(service, "Error closing configuration file", y);
}
}
return names.iterator();
}其中的parse函数用来将文件资源中的内容依次读取(一行一行),然后返回服务实现类的源根路径集合,如下图
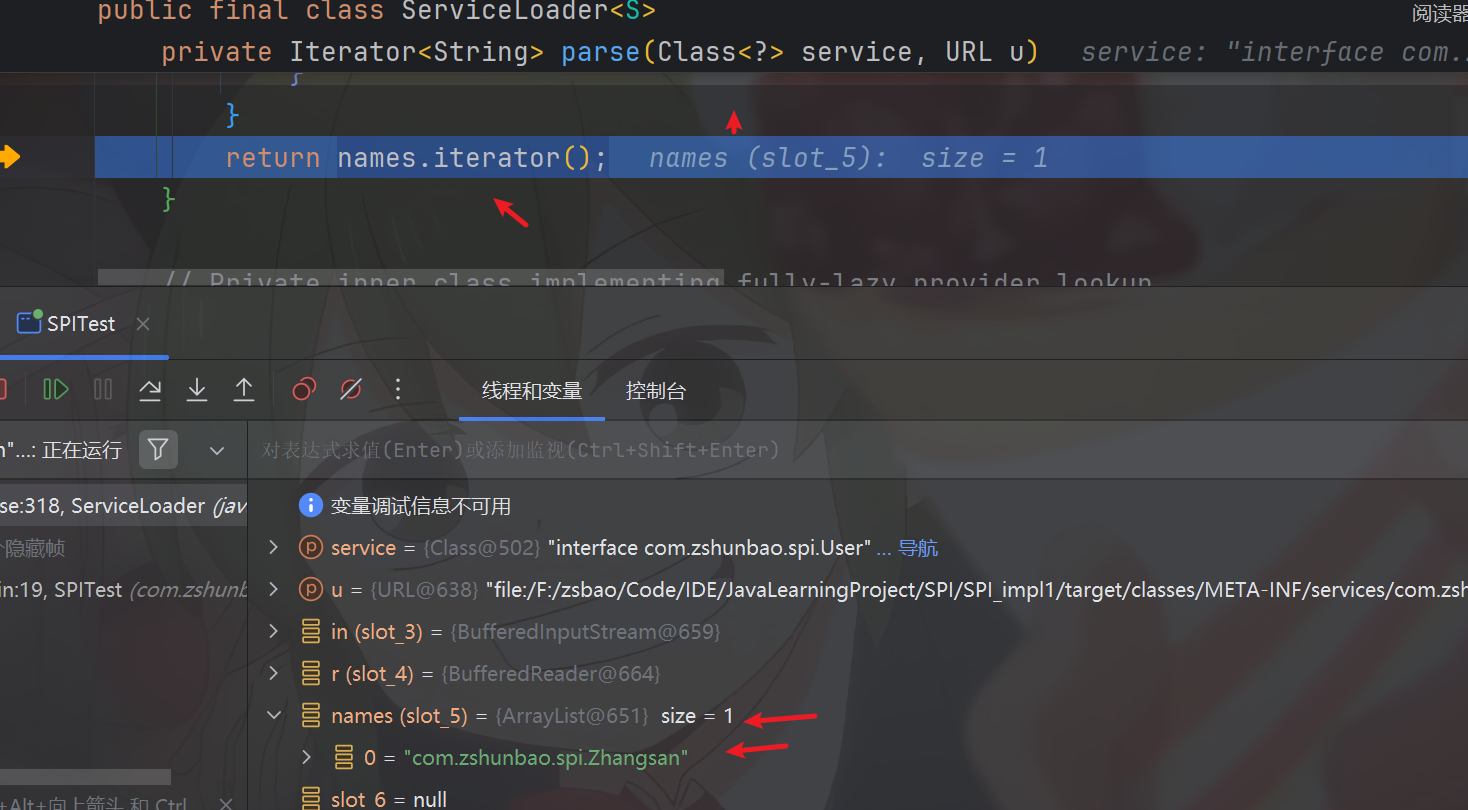
然后在集合收集完文件中的资源后,pending中也就不再为null了,所以它会按照逻辑将迭代器的下一个值赋值给懒加载器也就是lookupIterator的nextName属性字段,这就为后续取值做准备,然后返回true
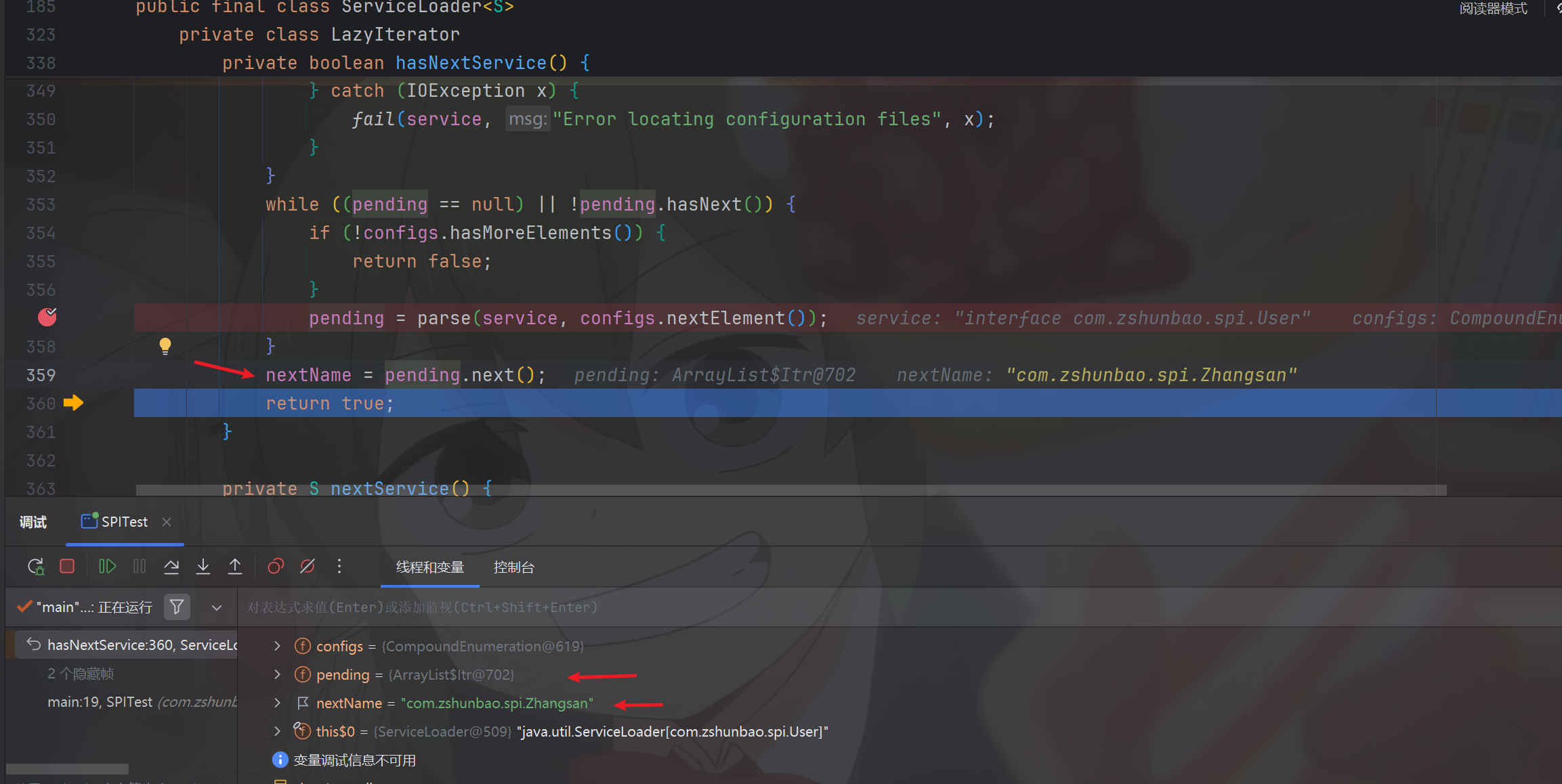
所以最终userIterator.hasNext()就会为true
所以接下来就会进入User user = userIterator.next();的逻辑
userIterator.next()
我们debug进入其中来看看具体的执行逻辑
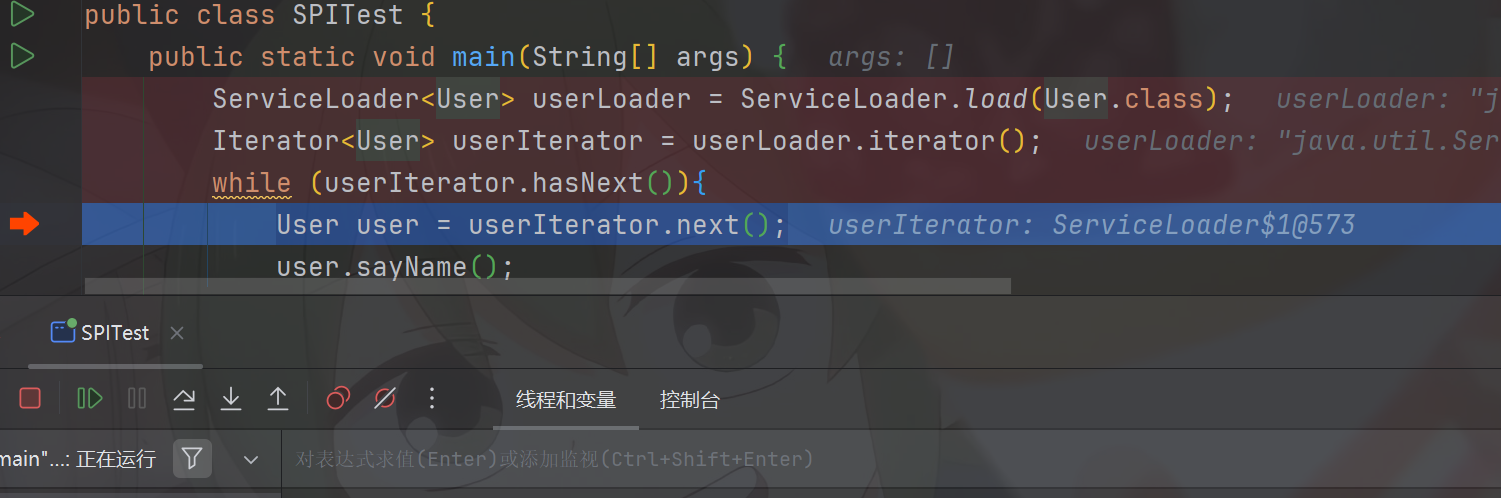
进入后我们先进入了我们在最外层拿到的匿名迭代器的next函数
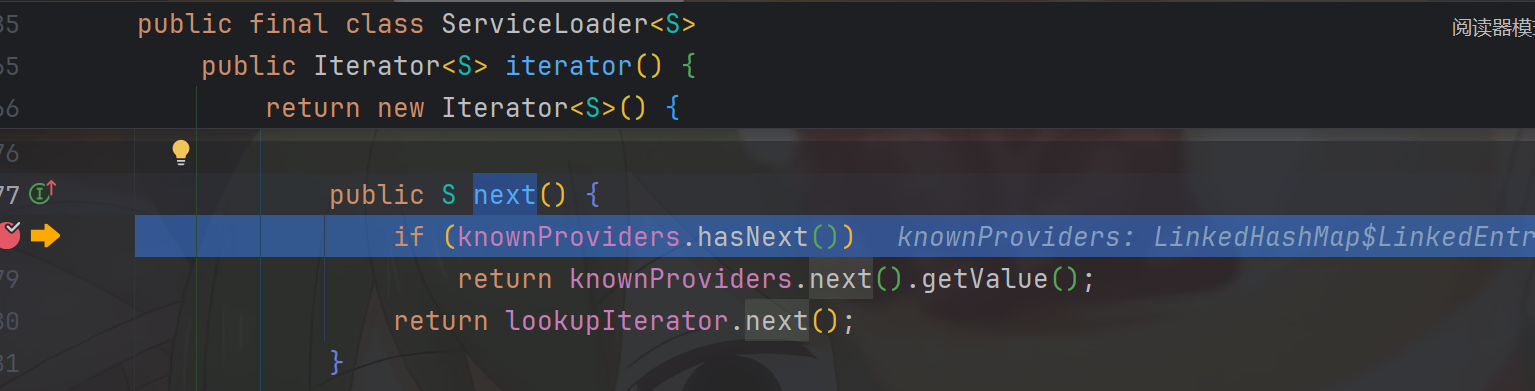
由于knownProviders依然为空,因此,我们进入lookupIterator.next()中去
debug进入后,我们进入了LazyIterator的next函数
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}由于acc为空,我们进入nextService函数
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}在这里面主要做了几个事情
将nextName的值(实现类的源根路径)赋值给了cn
然后通过cn加反射将具体的实现类拿到:
c = Class.forName(cn, false, loader);
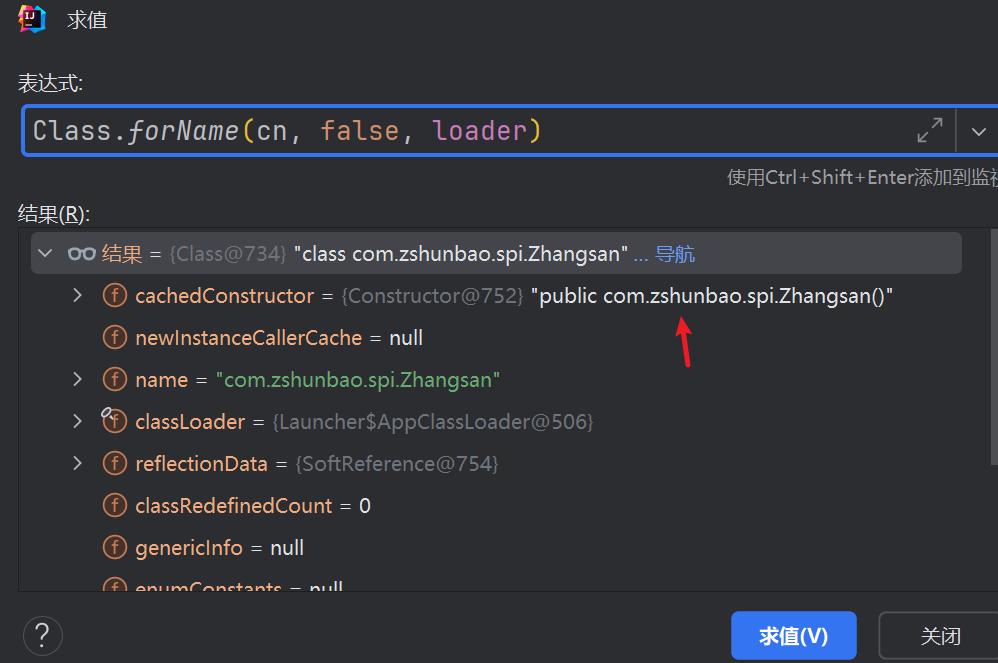
最后利用service创建一个子类的实例化对象(反射)c.newInstance(),并将实例化对象以(子类源根路径,对象)的方式存储在providers这个LinkedHashMap链表中。
这个链表的作用就是的在我们第一次调用相关的ServiceLoader.load并通过匿名迭代器遍历后,在后续的重复创建一个匿名迭代器去后去获取接口的服务对象时,可以直接从LinkedHashMap链表缓存里读取即可,无需再次去解析接口对应的配置文件,起到了查询优化的作用。
因为
返回创建的实例化对象,也就是我们拿到了子类的对象
总结
最后其实整个代码的流程无外乎在
通过 URL 工具类从 jar 包的
/META-INF/services目录下面找到对应的文件,
读取这个文件目录,在目录中找到对应的 spi 接口的源根路径命名的文件,
通过
InputStream流将文件资源里面,一行一行读取子类的源根路径名称
根据获取到的全类名,通过反射的机制构造对应的实例对象
将构造出来的实例对象添加到
Providers的列表中,让后续如果重复建造ServiceLoader#iterator()进行使用
SPI机制在不同框架中的应用
JDBC:加载数据库驱动,不需要手动
Class.forName;
日志框架:
java.util.logging、SLF4J 的适配;
JDK 内置工具:如
java.util.ServiceLoader本身就是为扩展机制设计的;
Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口
Spring中大量使用了SPI,比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等
SpringBoot 中使用(历史上
META-INF/spring.factories,新版使用基于 Import 的自动配置清单),这与 JDK SPI 不同。