
业务流程
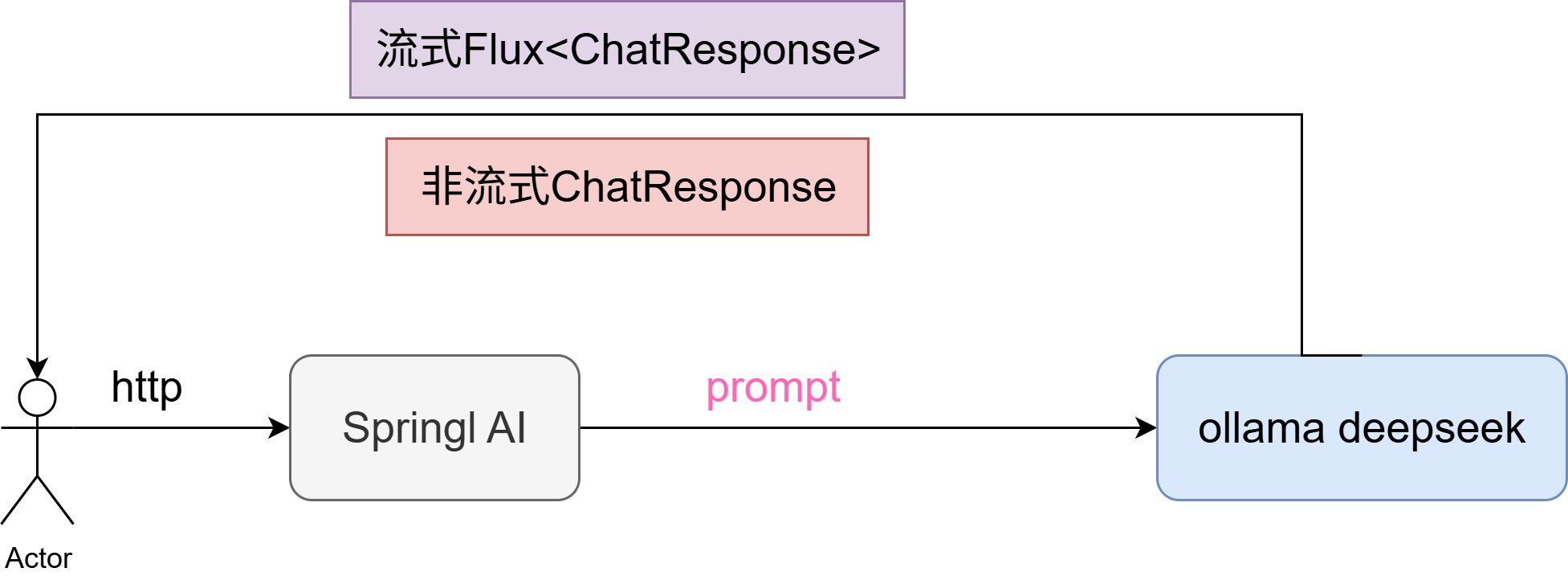
在后端项目中引入AI的能力,首先要做的第一个事情,就是能够使用项目与AI模型建立连接,针对我们的输入,可以得到AI的输出。这是最简单也是其中最基础的一步。
上一章节,我们已经利用ollama在本地部署好了deepseek的最小模型,本章节我们的主要目的就在于引入 Spring AI 框架组件,对接 Ollama DeepSeek 提供服务接口,做一个最基础的普通应答接口和流式接口。其实就是如何调用模型进行一次对话。
本章的代码不难,代码量极少,主要是去阅读官方文档,了解一些基本的概念较为重要
知识补充
Spring AI核心概念
下述内容摘录自 Spring AI官方文档
Spring AI 项目旨在简化包含人工智能功能的应用程序的开发,避免不必要的复杂性。
该项目的灵感源自一些著名的 Python 项目,例如 LangChain 和 LlamaIndex,但 Spring AI 并非这些项目的直接移植。该项目的创立基于这样一种信念:下一波生成式 AI 应用将不仅面向 Python 开发人员,还将遍及多种编程语言。
Spring AI 解决了 AI 集成的基本挑战: Connecting your enterprise Data and APIs with AI Models 。
更多的Spring AI支持的内容请阅读官方文档
本章内容的我们主要涉及到
一个核心的概念:Prompts,Stream
几个核心的封装:ChatClient、ChatResponse、Options
Prompts
基础概念
提示是基于语言的输入的基础,引导 AI 模型生成特定的输出。对于熟悉 ChatGPT 的人来说,提示可能看起来仅仅是在对话框中输入并发送到 API 的文本。然而,它包含的内容远不止于此。在许多 AI 模型中,提示的文本不仅仅是一个简单的字符串。
ChatGPT 的 API 在一个提示中包含多个文本输入,每个文本输入都被分配一个角色。例如,有一个系统角色,它告诉模型如何操作并设置交互的上下文。此外,还有一个用户角色,通常是来自用户的输入。
制作有效的提示既是一门艺术,也是一门科学。ChatGPT 是为人类对话而设计的。这与使用 SQL 之类的语言“提问”截然不同。与 AI 模型的交流必须类似于与人交谈。
这种交互方式如此重要,以至于“提示工程”一词已发展成为一门独立的学科。目前,有越来越多的技术可以提高提示的有效性。投入时间精心设计提示可以显著提升最终效果。
分享提示已成为一种公共实践,学术界也正在积极开展这方面的研究。为了说明创建有效提示(例如,与 SQL 对比)是多么违反直觉, 最近的一篇研究论文发现,最有效的提示之一以“深呼吸,一步一步来”这句话开头。这应该能让你明白语言为何如此重要。我们尚未完全了解如何最有效地利用这项技术的早期版本,例如 ChatGPT 3.5,更不用说正在开发的新版本了。
提示模板
创建有效的提示涉及建立请求的上下文,并用特定于用户输入的值替换请求的部分内容。
此过程使用传统的基于文本的模板引擎来创建和管理提示。Spring AI 为此使用了 OSS 库 StringTemplate 。
例如,考虑简单的提示模板:
Tell me a {adjective} joke about {content}.在 Spring AI 中,提示模板可以比作 Spring MVC 架构中的“视图”。它提供了一个模型对象(通常是 java.util.Map ),用于填充模板中的占位符。“渲染”后的字符串将成为提供给 AI 模型的提示内容。
发送给模型的提示的具体数据格式存在相当大的差异。提示最初只是一些简单的字符串,后来逐渐演变为包含多条消息,每条消息中的每个字符串都代表着模型的不同角色。
Prompt API---Prompt class,以下内容由阅读官方文档而来,写的属于个人理解,任何问题,请以官方文档为准
官方文档中,对于Prompt是这样描述的:Prompt 类充当一系列有序的 Message 对象和一个 ChatOptions 请求的容器。每条 Message 在提示中都体现出一个独特的角色,其内容和意图各不相同。这些角色可以涵盖各种元素,从用户查询到 AI 生成的响应,再到相关的背景信息。这种安排使得与 AI 模型进行复杂而细致的交互成为可能,因为提示由多条消息构成,每条消息在对话中都被赋予了特定的角色。
这里面在我看来有两个非常重要的点,message对象,独特的角色。既然每条message都会体现一种独特的角色,有哪些角色?message如何体现不同的角色?Prompt中如何表示?
官方文档中给了Prompt类的截断,如下
public class Prompt implements ModelRequest<List<Message>> {
private final List<Message> messages;
private ChatOptions chatOptions;
}然后我们去Idea中,ctrl+p查看Prompt类的构造参数,如下图
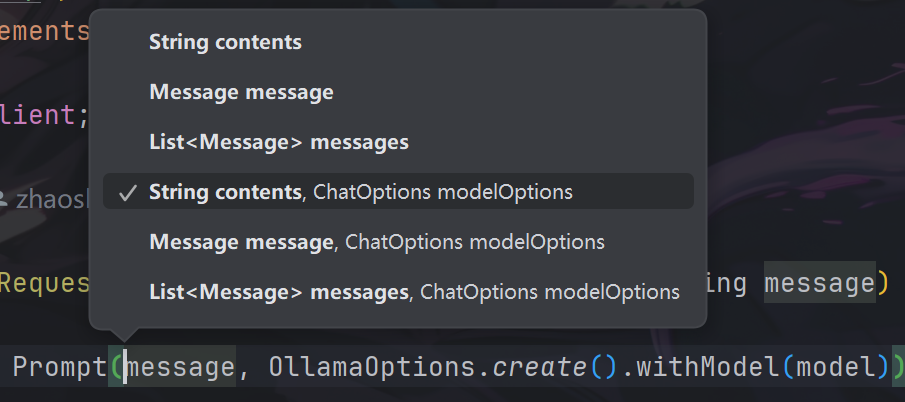
这两者说明,Prompt中的构造参数主要是Message和ChatOptions。但是官方文档给的主要截断并不能解答我们上面的几个问题。
有于是,接着看后续官方文档,有给出了如下说明:
每条消息都被赋予了特定的角色。这些角色对消息进行分类,为 AI 模型明确提示中每个部分的背景和目的。这种结构化方法增强了与 AI 沟通的细微差别和有效性,因为提示的每个部分在交互中都扮演着独特而明确的角色。
主要角色是:
系统角色:指导 AI 的行为和响应方式,设置 AI 如何解释和回复输入的参数或规则。这类似于在发起对话之前向 AI 提供指令。
用户角色:代表用户的输入——他们向 AI 提出的问题、命令或语句。这个角色至关重要,因为它构成了 AI 响应的基础。
助手角色:AI 对用户输入的响应。它不仅仅是一个答案或反应,对于维持对话的流畅性至关重要。通过追踪 AI 之前的响应(其“助手角色”消息),系统可以确保交互连贯且与上下文相关。助手消息也可能包含功能工具调用请求信息。它就像 AI 中的一项特殊功能,在需要执行特定功能(例如计算、获取数据或其他不仅仅是对话的任务)时使用。
工具/功能角色:工具/功能角色专注于响应工具调用助手消息返回附加信息。
读到这里,我们大致明白了,在Spring AI框架中定义了,系统角色,用户角色,助手角色,工具/功能角色,这几大类,角色将消息进行分类,明确提示的背景与目的。这个类似于我们在使用GPT的过程中,经常指定GPT身份,我们的身份。
现在你是一个xxx领域的专家,我是一个xx学生,我现在在做xxx,我遇到了xx问题,请你帮我解答但是在这里message如何体现不同的角色?Spring AI对于Message类做了如下介绍,Message 接口的各种实现对应于 AI 模型可以处理的不同类别的消息。模型根据对话角色来区分消息类别。如下图
仔细看这章图的继承关系,在抽象类AbstractMessage处里面定义了四种角色类型,并以此为基础,创建四种角色类型的子类Message。
在这里我们就可以根据不同类的Message来体现不同的角色。现在还有最后一个问题,Prompt中如何表示?
这里就需要观察Prompt的构造函数了,在构造函数中,如下
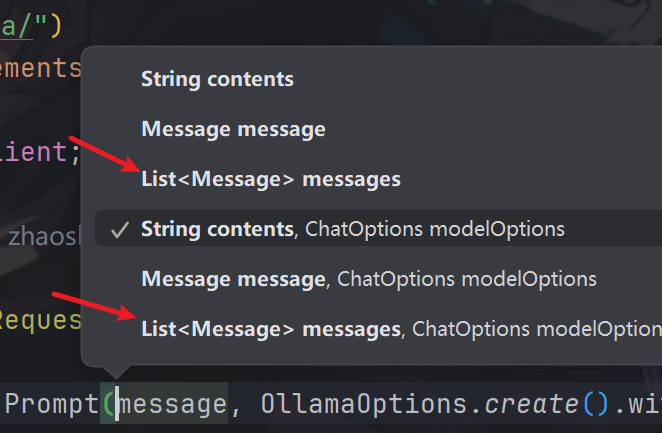
其中我们可以输入List<Message>,即我们可以将不同角色的消息合为一个List列表,传输给Prompt,由此在开发中指明各种角色信息,以便模型回答更符合我们的需求。
最后对于Message部分,还需要补充一下官网给定的Message中的代码信息
该接口定义如下:
public interface Content {
String getContent();
Map<String, Object> getMetadata();
}
public interface Message extends Content {
MessageType getMessageType();
}多模式消息类型还实现了 MediaContent 接口,提供了 Media 内容对象的列表。
public interface MediaContent extends Content {
Collection<Media> getMedia();
}示例代码
Prompt prompt = new Prompt(
List.of(
new SystemMessage("你是一位资深Java开发专家。"),
new UserMessage("请帮我写一个Spring Boot的Controller示例。")
),
OllamaOptions.create().withModel("deepseek-r1:1.5b")
);提示模版-PromptTemplate
最后关于Prompt部分我们还需要了解官网的有关Prompt的一个重要内容提示模版-PromptTemplate
提示模版其实就是:一个带变量的提示模板,你可以往里面填数据,生成最终要发给大模型的 Prompt,例如
“请帮我总结以下文章:{text}”其中{text}就是用户输入的东西,在用户输入后,会插入模版中,假定用户输入的是“小猫”,最终发送给大模型的便会是
“请帮我总结以下文章:小猫”然后我么来看看官方文档的定义: Spring AI 中提示模板的一个关键组件是
PromptTemplate类,旨在促进结构化提示的创建,然后将其发送到 AI 模型进行处理
官方文档给出了PromptTemplate类的实现
public class PromptTemplate implements PromptTemplateActions, PromptTemplateMessageActions {
// Other methods to be discussed later
}官方文档在其中很大篇幅的描述了PromptTemplateActions, PromptTemplateMessageActions的方法,意义,如下
PromptTemplateStringActions专注于创建和渲染提示字符串,代表最基本的提示生成形式。
PromptTemplateMessageActions专门用于通过生成和操作Message对象来创建提示。
PromptTemplateActions旨在返回Prompt对象,该对象可以传递给ChatModel以生成响应。实现的接口是
public interface PromptTemplateStringActions { String render(); String render(Map<String, Object> model); }方法
String render():将提示模板渲染为最终字符串格式,无需外部输入,适用于没有占位符或动态内容的模板。方法
String render(Map<String, Object> model):增强了渲染功能以包含动态内容。它使用Map<String, Object>其中映射键是提示模板中的占位符名称,值是要插入的动态内容。public interface PromptTemplateMessageActions { Message createMessage(); Message createMessage(List<Media> mediaList); Message createMessage(Map<String, Object> model); }方法
Message createMessage():创建一个没有附加数据的Message对象,用于静态或预定义的消息内容。方法
Message createMessage(List<Media> mediaList):创建具有静态文本和媒体内容的Message对象。方法
Message createMessage(Map<String, Object> model):扩展消息创建以集成动态内容,接受Map<String, Object>其中每个条目代表消息模板中的占位符及其对应的动态值。public interface PromptTemplateActions extends PromptTemplateStringActions { Prompt create(); Prompt create(ChatOptions modelOptions); Prompt create(Map<String, Object> model); Prompt create(Map<String, Object> model, ChatOptions modelOptions); }方法
Prompt create():生成无需外部数据输入的Prompt对象,非常适合静态或预定义提示。方法
Prompt create(ChatOptions modelOptions):生成一个无需外部数据输入但具有聊天请求特定选项的Prompt对象。方法
Prompt create(Map<String, Object> model):扩展提示创建功能以包含动态内容,采用Map<String, Object>其中每个映射条目都是提示模板及其关联动态值中的占位符。方法
Prompt create(Map<String, Object> model, ChatOptions modelOptions):扩展提示创建功能以包含动态内容,采用Map<String, Object>其中每个映射条目都是提示模板中的占位符及其关联的动态值,以及聊天请求的特定选项。
但是,在我阅读下感受,由于PromptTemplate实现了这些接口,那么我们主要只需要明白一些方法的作用就行,将结合示例如下
render函数,用用户输入替换掉模版中的动态变量,如下
PromptTemplate template = new PromptTemplate("Hello {name}!");
String rendered = template.render(Map.of("name", "Zs宝"));
System.out.println(rendered);输出:Hello Zs宝!
create函数,生成一个Prompt对象
Prompt prompt = template.create(Map.of("name", "Zs宝"));
ChatResponse response = chatClient.call(prompt);
//也可以加上生成参数
Prompt prompt = template.create(
Map.of("name", "Zs宝"),
OllamaOptions.create().withModel("deepseek-r1:1.5b").withTemperature(0.7)
);
createMessage函数,生成一个message对象
PromptTemplate template = new PromptTemplate(
"你好,我是{name},我想了解关于{topic}的知识。"
);
Message message = template.createMessage(Map.of(
"name", "Zs宝",
"topic", "Spring AI"
));
System.out.println(message.getContent());输出:你好,我是Zs宝,我想了解关于Spring AI的知识。
这里有一个总结
最终示例
// 定义 system 模板
PromptTemplate sysTpl = new PromptTemplate("你是一位{role},回答必须使用{language}。");
// 定义 user 模板
PromptTemplate userTpl = new PromptTemplate("请用一句话解释:{topic}");
Message systemMsg = sysTpl.createMessage(Map.of(
"role", "资深Java开发专家",
"language", "中文"
));
Message userMsg = userTpl.createMessage(Map.of(
"topic", "依赖注入(DI)"
));
Prompt prompt = new Prompt(
List.of(systemMsg, userMsg),
OllamaOptions.create().withModel("deepseek-r1:1.5b")
);
System.out.println(chatClient.call(prompt));输出:好的,我现在要解释什么是依赖注入(DI)。我应该先从基本概念开始讲起。DI是一种通过配置的方式来管理应用程序中的对象,而不是直接指定它们的行为。这有助于减少代码的复杂性,特别是当需要在代码中动态添加或移除对象时。
然后,我需要说明它如何工作。通常,一个项目会将依赖注入配置存放在一个配置文件中,比如项目根目录下的 DI 库置。一旦配置完成,就可以使用简单的JavaScript代码来创建项目所需的类和对象。这使得代码更容易维护和扩展,因为它可以随项目需求动态变化。
接下来,我应该提到它与其他方法的区别。例如,静态初始化方法或 constructor 是用固定的行为定义的,而 DI 允许根据不同的场景自动生成新的行为,这减少了重复代码,提升了代码质量。
另外,我可以举一个例子来说明DI的优势,比如创建一个简单的React项目时,只需要配置一个 DI 库置文件,然后在JavaScript中只需调用某些函数,就能得到一个灵活的组件。这种灵活性大大简化了开发过程。
最后,我应该强调使用依赖注入有助于提高代码的可扩展性和可维护性,是现代Java编程中的重要趋势之一。 </think>
依赖注入(DI)是一种通过配置管理应用程序对象的方法,通过将对象的定义放在代码中而不是行为上,从而减少了重复代码并增加了灵活性。它允许动态生成复杂的行为,帮助开发人员在需要时灵活调整应用的结构和功能。"
最后,文档中有这样一段
Spring AI 使用
TemplateRenderer接口来处理将变量实际替换到模板字符串中。默认实现使用 [StringTemplate] 。如果需要自定义逻辑,可以提供自己的TemplateRenderer实现。对于不需要模板渲染的场景(例如,模板字符串已经完成),可以使用提供的NoOpTemplateRenderer。使用带有“<”和“>”分隔符的自定义 StringTemplate 渲染器的示例
PromptTemplate promptTemplate = PromptTemplate.builder() .renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build()) .template(""" Tell me the names of 5 movies whose soundtrack was composed by <composer>. """) .build(); String prompt = promptTemplate.render(Map.of("composer", "John Williams"));
实际就是再讲,默认占位符是 {变量名},但有的时候,比如模版中我们使用JSON,如
{"input": "{text}"}会和模板引擎的 {} 冲突。所以官方文档提示可以修改分割符,比如改为 < 和 >:
PromptTemplate template = PromptTemplate.builder()
.renderer(StTemplateRenderer.builder()
.startDelimiterToken("<")
.endDelimiterToken(">")
.build())
.template("请总结以下内容:<text>")
.build();
这样占位符就变成 <text> 了。
Stream、ChatClient、ChatResponse、Options
这里简单解释下上述几个名词的概念,详细的请看官方文档聊天客户端API
ChatClient 是 Spring AI 提供的用于“聊天”(对话式生成模型)交互的客户端接口/类。它封装了与聊天模型(比如 GPT 类模型)交互的流程,提供了一个流畅(fluent)API,开发者可以通过它发起对话请求、设置上下文消息、接收返回结果。 它支持两种模式:同步调用(一次发送、一次接收)以及流式调用(Streaming,模型边生成边返回结果)
用途/特点
封装聊天提示(Prompt)构建:包括系统消息、用户消息、(有时也包括助手消息或工具调用)等。
提供链式调用方式,比如
.prompt().user(...).call()或.prompt().user(...).stream()等。支持设置默认参数(比如系统提示、默认模型选项)通过
ChatClient.Builder来构建。支持多模型/多配置场景:你可以使用不同的 ChatModel 创建不同的 ChatClient。
ChatResponse 是 ChatClient 调用后得到的响应类型(同步或流式都可能返回它或其流形式)。它不仅包含了模型生成的内容,还包含元数据(metadata)、多条 “generation” 的可能结果、令牌(token) 使用情况等。
具体来说,根据文档:
“AI 模型的响应是由类型
ChatResponse定义的丰富结构。它包含有关响应如何生成的元数据,并且还可以包含多个响应,称为 Generations,每个响应都有自己的元数据。元数据包括用于创建响应的 token 数量。 ”
用途/特点
当你需要更多-than-文本的控制/观察,比如查看用了多少 token、结束原因、多个候选生成结果,就可以使用
chatResponse()方法获取ChatResponse对象。支持实体映射(将返回文本映射为 Java实体)或结构化输出。虽然这个功能有时直接用
.entity()提供,但ChatResponse是承载这些内容的基础结构。在流式模式下,还可以通过
Flux<ChatResponse>获得响应流,每一个 generation 或中间段可能成为一个ChatResponse
Options 是一个接口/抽象,用来表示“聊天请求时可选的、与模型生成行为相关的参数配置”。例如温度 (temperature)、top-p、maxTokens、模型选择(model) 等。
在具体的模型实现中,会有 OpenAiChatOptions、AnthropicChatOptions、AzureOpenAiChatOptions 等,它们实现了 Options 接口,加入各自模型特有的参数。
用途/特点
允许你在调用
ChatClient前,设置或覆盖模型生成行为,比如:“我要更创意一点 (higher temperature)”、“我要结果尽量确定 (lower temperature)”、“使用模型 X 而不是默认模型” 等。支持在全局(在
ChatClient.Builder中设置默认ChatOptions)和请求级别(在.prompt().options(...)中覆盖)两种层次。 Spring AI Alibaba官网+1为“提示模板 +配置 +执行”提供灵活性,使得同一个 ChatClient 可以应对不同需求场景(例如对话 vs 代码生成 vs摘要)。
从文档可看到 :
temperature: 控制输出随机性/创造性。越高越随机。topP: 核采样(nucleus sampling)参数。maxCompletionTokens: 输出的最大 token 数。frequencyPenalty,presencePenalty: 控制重复内容或新话题倾向。model: 选择具体用哪个模型(例如gpt-4o,gpt-3.5‐turbo
Reactive Streams 响应式编程模型
在 Spring AI(或其他大语言模型接口)中,“流式输出” (Streaming Output) 和 “非流式输出” (Non-Streaming Output) 是2种主要的输出方式,其中
非流式输出指——模型在生成完整的回答后一次性返回结果。应用端在调用接口后,要等模型生成完所有文本,才会收到完整的响应。Spring AI具体体现在chatClient.call
流式输出指——模型边生成边发送结果。 也就是说,它不会等到整个回答生成完,而是“一边生成、一边推送给客户端”。显示中就是我们看到各种大模型对话窗口一个字一个字的蹦出返回给我们的结果。Spring AI中具体体现在chatClient.stream
但是根据官方文档
在
ChatClient上指定stream()方法后,响应类型有以下几种选项:
Flux<String> content():返回由 AI 模型生成的字符串的Flux。
Flux<ChatResponse> chatResponse():返回ChatResponse对象的Flux,其中包含有关响应的其他元数据。
Flux<ChatClientResponse> chatClientResponse():返回包含ChatResponse对象和 ChatClient 执行上下文的ChatClientResponse对象的Flux,使您能够访问顾问执行期间使用的其他数据(例如,在 RAG 流中检索到的相关文档)。而非流式输出只需要
在
ChatClient上指定call()方法后,响应类型有几种不同的选项。
String content():返回响应的字符串内容
ChatResponse chatResponse():返回包含多个代以及有关响应的元数据的ChatResponse对象,例如,使用了多少个令牌来创建响应。
ChatClientResponse chatClientResponse():返回一个ChatClientResponse对象,该对象包含ChatResponse对象和 ChatClient 执行上下文,使您可以访问顾问执行期间使用的其他数据(例如,在 RAG 流中检索到的相关文档)。
ResponseEntity<?> responseEntity():返回包含完整 HTTP 响应(包括状态码、标头和正文)的ResponseEntity。当您需要访问响应的底层 HTTP 详细信息时,此功能非常有用。
entity()返回 Java 类型
entity(ParameterizedTypeReference<T> type):用于返回实体类型的Collection。
entity(Class<T> type):用于返回特定的实体类型。
entity(StructuredOutputConverter<T> structuredOutputConverter):用于指定StructuredOutputConverter的实例,以将String转换为实体类型。
这个流式输出的Flux究竟是什么呢?
Flux这个概念来自于响应式编程,具体可以去参考官方文档
Flux:一个包含 0-N 个元素的异步序列。正如我们的流式输出,是一边生成,一边推送给客户端,输出就是拥有 0-N 个元素的异步序列。
下图展示了 Flux 如何转换item
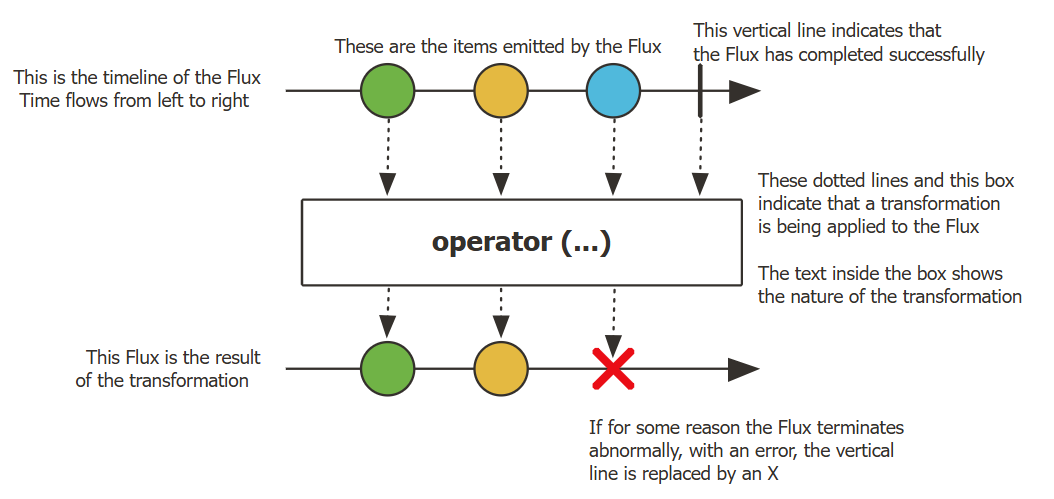
可以看到结果是一点一点的输出出来,并且按时间顺序发送,如果某一个节点出现问题,输出结束
Flux<T> 是一个标准的 Publisher<T> ,它表示一个异步序列,包含 0 到 N 个已发出的数据项,并可选择以完成信号或错误终止。与 Reactive Streams 规范中所述一样,这三种类型的信号会转换为对下游 Subscriber 的 onNext 、 onComplete 和 onError 方法的调用。
由于信号种类繁多, Flux 是通用的响应式类型。需要注意的是,所有事件,即使是终止事件,都是可选的:没有 onNext 事件,但有一个 onComplete 事件代表一个空的有限序列,但移除 onComplete 事件后,你将得到一个无限的空序列(除了用于取消相关的测试外,没什么用)。同样,无限序列也不一定为空。例如, Flux.interval(Duration) 产生一个无限的 Flux<Long> ,并从时钟发出规则的滴答声。
与Flux相对应的还有一个叫做Mono,异步的 0-1 结果的概念,表示最多发出 1 个元素(或为空)。
Flux 是 Reactor 中的“多元素异步流”,它让程序能像处理集合一样优雅地处理连续、异步的数据流, 同时又能用于实现实时、流式、响应式的系统(如 Spring AI 的 Streaming Chat)。
有关Flux的更多内容,请阅读Reactor官方文档
有了上述相关知识,我们就可以完成本章节的代码
业务实现
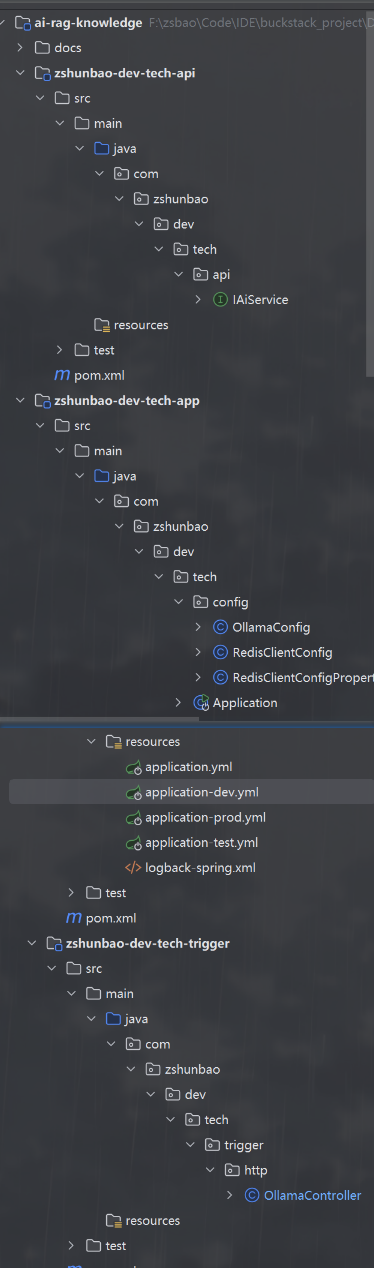
本章节的项目结构如下
基础配置类
这部分内容置于
zshunbao-dev-tech-app模块下
有关redis的配置如下
package com.zshunbao.dev.tech.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* @author zs宝
* Redis 连接配置 <a href="https://github.com/redisson/redisson/tree/master/redisson-spring-boot-starter">redisson-spring-boot-starter</a>
*/
@Data
@ConfigurationProperties(prefix = "redis.sdk.config", ignoreInvalidFields = true)
public class RedisClientConfigProperties {
/** host:ip */
private String host;
/** 端口 */
private int port;
/** 账密 */
private String password;
/** 设置连接池的大小,默认为64 */
private int poolSize = 64;
/** 设置连接池的最小空闲连接数,默认为10 */
private int minIdleSize = 10;
/** 设置连接的最大空闲时间(单位:毫秒),超过该时间的空闲连接将被关闭,默认为10000 */
private int idleTimeout = 10000;
/** 设置连接超时时间(单位:毫秒),默认为10000 */
private int connectTimeout = 10000;
/** 设置连接重试次数,默认为3 */
private int retryAttempts = 3;
/** 设置连接重试的间隔时间(单位:毫秒),默认为1000 */
private int retryInterval = 1000;
/** 设置定期检查连接是否可用的时间间隔(单位:毫秒),默认为0,表示不进行定期检查 */
private int pingInterval = 0;
/** 设置是否保持长连接,默认为true */
private boolean keepAlive = true;
}
package com.zshunbao.dev.tech.config;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.codec.JsonJacksonCodec;
import org.redisson.config.Config;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Redis 客户端,使用 Redisson <a href="https://github.com/redisson/redisson">Redisson</a>
*
*/
@Configuration
@EnableConfigurationProperties(RedisClientConfigProperties.class)
public class RedisClientConfig {
@Bean("redissonClient")
public RedissonClient redissonClient(ConfigurableApplicationContext applicationContext, RedisClientConfigProperties properties) {
Config config = new Config();
// 根据需要可以设定编解码器;https://github.com/redisson/redisson/wiki/4.-%E6%95%B0%E6%8D%AE%E5%BA%8F%E5%88%97%E5%8C%96
config.setCodec(JsonJacksonCodec.INSTANCE);
config.useSingleServer()
.setAddress("redis://" + properties.getHost() + ":" + properties.getPort())
// .setPassword(properties.getPassword())
.setConnectionPoolSize(properties.getPoolSize())
.setConnectionMinimumIdleSize(properties.getMinIdleSize())
.setIdleConnectionTimeout(properties.getIdleTimeout())
.setConnectTimeout(properties.getConnectTimeout())
.setRetryAttempts(properties.getRetryAttempts())
.setRetryInterval(properties.getRetryInterval())
.setPingConnectionInterval(properties.getPingInterval())
.setKeepAlive(properties.isKeepAlive())
;
return Redisson.create(config);
}
}
有关调用ollama的配置类
package com.zshunbao.dev.tech.config;
import org.springframework.ai.ollama.OllamaChatClient;
import org.springframework.ai.ollama.api.OllamaApi;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @program: ai-rag-knowledge
* @ClassName OllamaConfig
* @description: OllamaConfig配置类
* @author: zs宝
* @create: 2025-10-18 19:57
* @Version 1.0
**/
@Configuration
public class OllamaConfig {
@Bean
public OllamaApi ollamaApi(@Value("${spring.ai.ollama.base-url}") String baseUrl){
return new OllamaApi(baseUrl);
}
@Bean
public OllamaChatClient ollamaChatClient(OllamaApi ollamaApi){
return new OllamaChatClient(ollamaApi);
}
}
接着是一些yml文件配置
application.yml
spring:
application:
name: ai-rag-knowledge
profiles:
active: dev
application-dev.yml
server:
port: 8090
spring:
ai:
ollama:
base-url: http://127.0.0.1:11434
# Redis
redis:
sdk:
config:
host: 127.0.0.1
port: 16379
pool-size: 10
min-idle-size: 5
idle-timeout: 30000
connect-timeout: 5000
retry-attempts: 3
retry-interval: 1000
ping-interval: 60000
keep-alive: true
logging:
level:
root: info
config: classpath:logback-spring.xml
应答接口实现
首先我们先在zshunbao-dev-tech-api模块下定义全局的接口
package com.zshunbao.dev.tech.api;
import org.springframework.ai.chat.ChatResponse;
import reactor.core.publisher.Flux;
/**
* @program: ai-rag-knowledge
* @ClassName IAiService
* @description: 定义AI服务的总接口
* @author: zs宝
* @create: 2025-10-18 20:01
* @Version 1.0
**/
public interface IAiService {
/**
* 调用模型进行非流式输出
* @param model 模型
* @param message 提示词
* @return
*/
ChatResponse generate(String model,String message);
/**
* 调用模型进行流式输出
* @param model 模型
* @param message 提示词
* @return
*/
Flux<ChatResponse> generateStream(String model,String message);
}
对应的对外http实现我们放在zshunbao-dev-tech-trigger模块下
package com.zshunbao.dev.tech.trigger.http;
import com.zshunbao.dev.tech.api.IAiService;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.ollama.OllamaChatClient;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
/**
* @program: ai-rag-knowledge
* @ClassName OllamaController
* @description: 调用ollama访问配置的模型,通过http访问
* @author: zs宝
* @create: 2025-10-18 20:05
* @Version 1.0
**/
@RestController
@CrossOrigin("*")
@RequestMapping("/api/v1/ollama/")
public class OllamaController implements IAiService {
@Resource
private OllamaChatClient chatClient;
@GetMapping("generate")
@Override
public ChatResponse generate(@RequestParam String model, @RequestParam String message) {
return chatClient.call(new Prompt(message, OllamaOptions.create().withModel(model)));
}
@GetMapping("generate_stream")
@Override
public Flux<ChatResponse> generateStream(@RequestParam String model, @RequestParam String message) {
return chatClient.stream(new Prompt(message, OllamaOptions.create().withModel(model)));
}
}
至此,我们的项目便已经可以和部署的模型进行应答响应
测试
输出结果(JSON)的展示被浏览器插件 JSON-handle美化了,更易于观看查询
非流式输出调用结果
http://localhost:8090/api/v1/ollama/generate?model=deepseek-r1:1.5b&message=你是什么模型
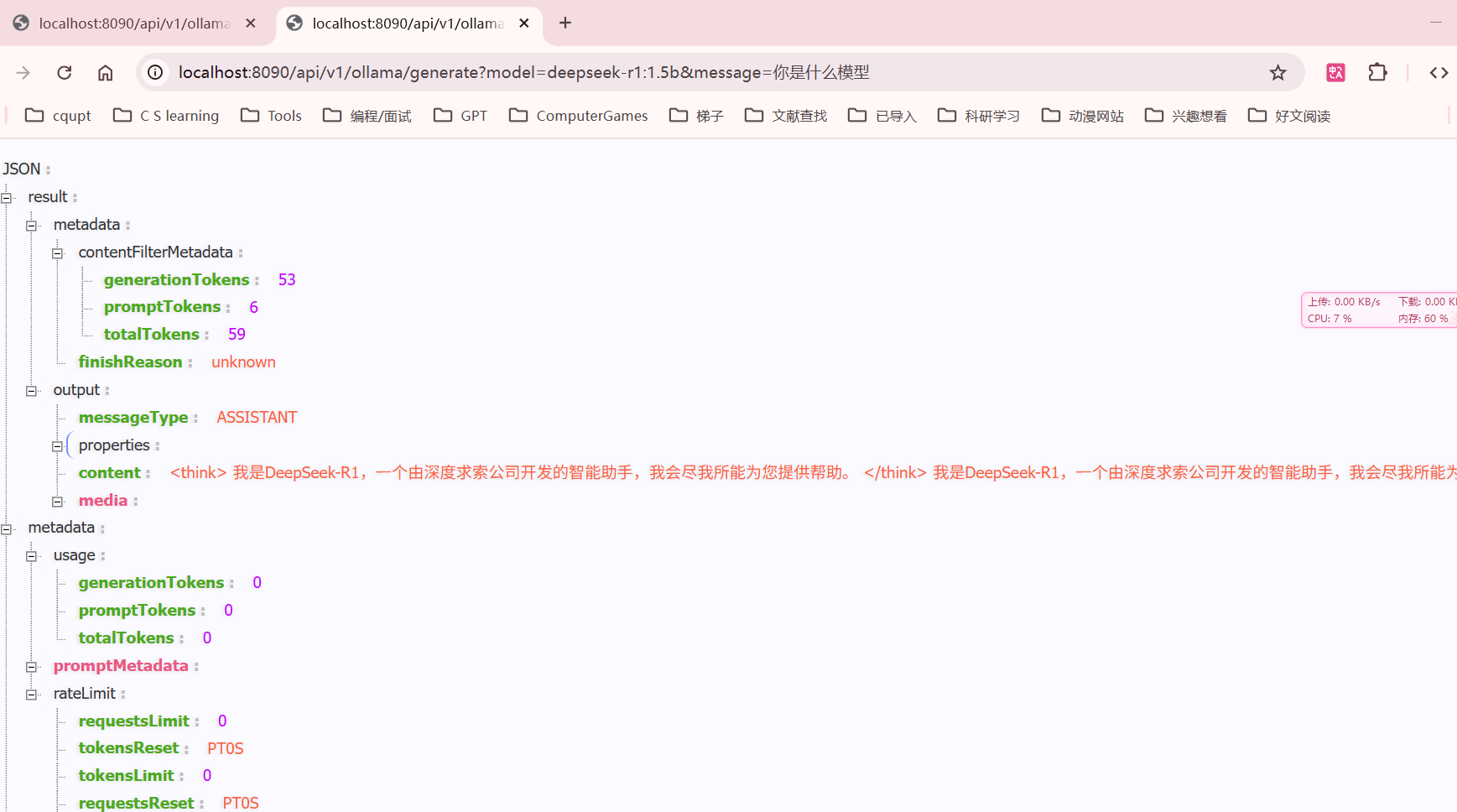
具体内容如下
{
"result": {
"metadata": {
"contentFilterMetadata": {
"generationTokens": 53,
"promptTokens": 6,
"totalTokens": 59
},
"finishReason": "unknown"
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "<think>\n我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。\n</think>\n\n我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。",
"media": []
}
},
"metadata": {
"usage": {
"generationTokens": 0,
"promptTokens": 0,
"totalTokens": 0
},
"promptMetadata": [],
"rateLimit": {
"requestsLimit": 0,
"tokensReset": "PT0S",
"tokensLimit": 0,
"requestsReset": "PT0S",
"tokensRemaining": 0,
"requestsRemaining": 0
}
},
"results": [
{
"metadata": {
"contentFilterMetadata": {
"generationTokens": 53,
"promptTokens": 6,
"totalTokens": 59
},
"finishReason": "unknown"
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "<think>\n我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。\n</think>\n\n我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。",
"media": []
}
}
]
}流式输出:http://localhost:8090/api/v1/ollama/generate_stream?model=deepseek-r1:1.5b&message=你是什么模型
输出显示的json非常多
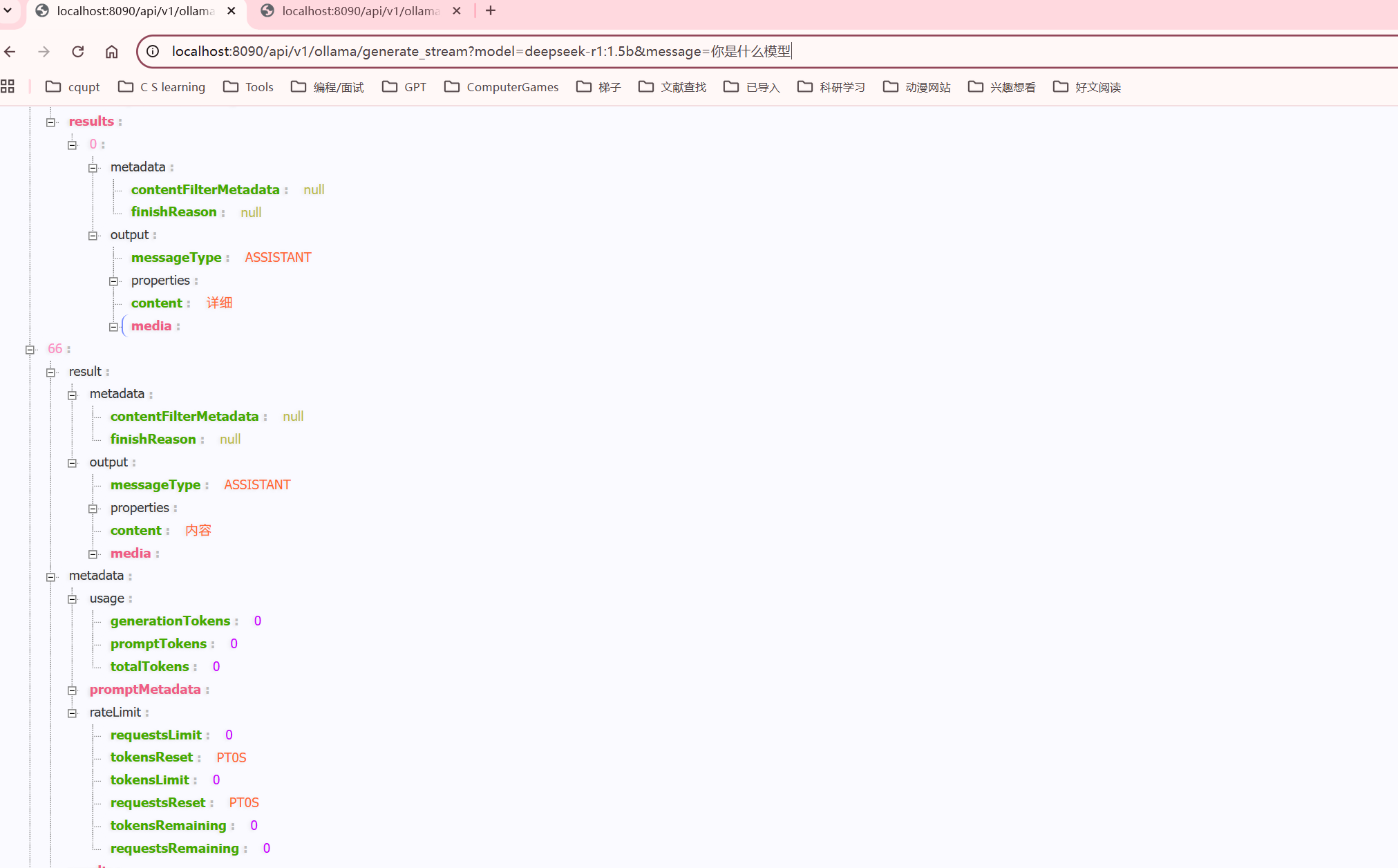
具体内容如下,可以看到流式输出的特点
[
{
"result": {
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "<think>",
"media": []
}
},
"metadata": {
"usage": {
"generationTokens": 0,
"promptTokens": 0,
"totalTokens": 0
},
"promptMetadata": [],
"rateLimit": {
"requestsLimit": 0,
"tokensReset": "PT0S",
"tokensLimit": 0,
"requestsReset": "PT0S",
"tokensRemaining": 0,
"requestsRemaining": 0
}
},
"results": [
{
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "<think>",
"media": []
}
}
]
},
{
"result": {
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "\n",
"media": []
}
},
"metadata": {
"usage": {
"generationTokens": 0,
"promptTokens": 0,
"totalTokens": 0
},
"promptMetadata": [],
"rateLimit": {
"requestsLimit": 0,
"tokensReset": "PT0S",
"tokensLimit": 0,
"requestsReset": "PT0S",
"tokensRemaining": 0,
"requestsRemaining": 0
}
},
"results": [
{
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "\n",
"media": []
}
}
]
},
{
"result": {
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "您好",
"media": []
}
},
"metadata": {
"usage": {
"generationTokens": 0,
"promptTokens": 0,
"totalTokens": 0
},
"promptMetadata": [],
"rateLimit": {
"requestsLimit": 0,
"tokensReset": "PT0S",
"tokensLimit": 0,
"requestsReset": "PT0S",
"tokensRemaining": 0,
"requestsRemaining": 0
}
},
"results": [
{
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "您好",
"media": []
}
}
]
},
{
"result": {
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "!",
"media": []
}
},
"metadata": {
"usage": {
"generationTokens": 0,
"promptTokens": 0,
"totalTokens": 0
},
"promptMetadata": [],
"rateLimit": {
"requestsLimit": 0,
"tokensReset": "PT0S",
"tokensLimit": 0,
"requestsReset": "PT0S",
"tokensRemaining": 0,
"requestsRemaining": 0
}
},
"results": [
{
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "!",
"media": []
}
}
]
},
{
"result": {
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "我是",
"media": []
}
},
"metadata": {
"usage": {
"generationTokens": 0,
"promptTokens": 0,
"totalTokens": 0
},
"promptMetadata": [],
"rateLimit": {
"requestsLimit": 0,
"tokensReset": "PT0S",
"tokensLimit": 0,
"requestsReset": "PT0S",
"tokensRemaining": 0,
"requestsRemaining": 0
}
},
"results": [
{
"metadata": {
"contentFilterMetadata": null,
"finishReason": null
},
"output": {
"messageType": "ASSISTANT",
"properties": {},
"content": "我是",
"media": []
}
}
]
},
.......................................................接近3000行
]