
内核是如何接收网络包的
本文详细介绍Linux内核接收网络包的完整流程,从系统启动准备到网络包的接收处理,再到内核与用户进程的协作机制,最后介绍性能优化的各种方法。通过本文,你将深入理解Linux网络子系统的运作原理。
目录
0、小故事
想象你开了一家超级快递公司(Linux内核),专门处理来自世界各地的快递(网络包)。
在开门营业前,你需要做一系列准备工作:
开店前的准备(系统启动)
1. 招聘员工
- 根据店面大小招聘员工——有几个工作间(CPU核心)就招几个员工
- 每个员工都有自己的工牌:
ksoftirqd/0、ksoftirqd/1…… - 这些员工是"隐形后勤",从不下班,一直在公司待命
2. 制定工作手册
- 写清楚收到快递后该按什么步骤处理
- 不同类型的快递(TCP、UDP)有不同的处理方式
- 员工遇到什么情况就翻到手册哪一页
3. 登记快递类型
- 普通快递(UDP):快点送到就行
- 挂号快递(TCP):必须送到,还要对方签收确认
- 加急快递(HTTP):特别紧急的,优先处理
4. 安装接收窗口
- 在店面门口安装一个接收窗口(你的网卡,比如 eth0)
- 在窗口旁边放几排架子(Ring Buffer)
- 一排架子用来放收到的快递(RX队列)
- 一排架子用来放要发出的快递(TX队列)
快递到达处理流程(网络包接收)
现在,快递真的来了!让我们一起看看完整的处理过程:
场景:一个从远方寄来的包裹(网络包)到达你的快递公司
第1步:快递到达门口(网卡接收)
- 快递员(远程服务器)把包裹送到你的接收窗口
- 窗口的员工(网卡硬件)签收包裹
- 把包裹放到旁边的架子上(通过DMA写入Ring Buffer)
为什么先放架子上?
快递员放下包裹就可以走了,不用等你们处理,可以继续送下一个包裹
第2步:按门铃通知(硬中断)
- 包裹放到架子后,员工按一下门铃(触发硬件中断)
- 门铃响了!正在办公室工作的你(CPU)听到铃声
- 你放下手头的工作,快速跑到门口看一眼
- 只做一个动作:看到架子上有包裹,关掉门铃,喊一声:“员工去处理!”
- 然后赶紧回办公室继续做之前的工作
为什么这么快?
如果每个包裹都要你亲自处理,你就别做别的事了。所以你只确认一下,让员工去慢慢处理
第3步:员工处理包裹(软中断)
- 听到你喊的员工(ksoftirqd线程)放下手中的活
- 来到架子旁,开始处理包裹
- 一次处理多个:员工不会来一个包裹就跑一趟,而是把架子上的包裹都拿进来处理
- 这样效率更高,不用来回跑
NAPI机制:
- 快递少的时候:每来一个包裹按一次门铃(中断模式),响应快
- 快递多的时候:员工直接去架子拿(轮询模式),效率高
第4步:拆包裹分类(协议栈处理)
员工把包裹拿到工作台上,开始层层拆开:
【最外层】纸箱包装
↓ 员工拆开
【中间层】气泡膜
↓ 员工拆开
【内层】礼品包装纸
↓ 员工拆开
【最后】里面的小礼物 + 一张卡片
卡片上写着:"送给:张三,收件地址:北京市朝阳区..."
每一层由不同的员工负责:
- 拆纸箱的(链路层):去掉最外层的包装,看是什么类型
- 看地址的(网络层):确认这是不是送给我们的,要送到哪个部门
- 登记的(传输层):在登记本上记录下来,方便以后查找
- 放信箱的(Socket层):根据卡片上的名字,放到对应客户的信箱里
你如何拿到快递(内核与用户进程协作)
包裹处理完了,现在在你的信箱里。你怎么知道有快递?怎么取出来?
方式1:一直守在信箱旁(同步阻塞IO)
- 你来到信箱前
- 打开看看:空的
- 那就一直等着(阻塞),哪里也不去
- 终于,员工把包裹放进了信箱
- 你马上拿走,开心地回家
- 然后再来守下一个包裹
优点:简单,不用动脑子
缺点:一个人只能守一个信箱,多了就来不及
适合:个人电脑,连接不多的场景
方式2:一个人看多个信箱(IO多路复用)
- 你负责看管100个信箱
- 你走到所有信箱前看一圈
- 都没快递?那就找个椅子坐一会(阻塞等待)
- 哪个信箱有快递了,系统会通知你
- 你去拿那个信箱的快递
- 拿完了,再回去看其他的信箱
epoll的秘密:
- 系统有个专门的通知员
- 哪个信箱有快递,通知员就告诉你
- 你不用一个个去查看,效率超高
- 一个人可以轻松管理成千上万个信箱!
这就是为什么一个网站服务器能同时服务成千上万用户!
让生意更红火(性能优化)
如果快递公司生意特别好,怎么优化才能不忙乱?
优化1:买更大的架子(扩大Ring Buffer)
问题:快递太多,小架子不够用,新来的快递没地方放,只能扔掉
解决:买个更大的架子,可以暂存更多快递
# 查看当前架子大小
ethtool -g eth0
# 买个更大的架子
sudo ethtool -G eth0 rx 4096 tx 4096
bash
优化2:多开几个接收窗口(RSS多队列)
问题:只有一个接收窗口,快递员排队卸货,太慢了
解决:
- 开多个接收窗口(多队列网卡)
- 不同地方的快递去不同的窗口
- 多个员工同时处理
- 快很多!
效果:单窗口处理100个包裹/小时 → 多窗口处理800个包裹/小时
优化3:快递批量通知(中断合并)
问题:每个包裹都按一次门铃,门铃响个不停,打扰你工作
解决:
- 等10个包裹到了再按一次门铃
- 或者等10秒钟到了再按一次门铃
- 门铃响的次数少了,你被打断的次数也少了
# 设置批量通知
sudo ethtool -C eth0 rx-usecs 50 rx-frames 32
bash
优化4:员工一次处理更多包裹(软中断合并)
问题:员工一次只拿几个包裹,要来回跑很多次
解决:
- 让员工一次拿更多包裹
- 一次拿50个,而不是5个
- 减少来回跑的次数
# 告诉员工一次可以处理更多
echo 600 > /proc/sys/net/core/netdev_budget
完整流程如下
┌─────────────────────────────────────────────────────────────┐
│ 你的快递公司(Linux内核) │
└─────────────────────────────────────────────────────────────┘
【开店前准备】
1. 招聘员工(ksoftirqd线程)
2. 制定工作手册(注册软中断处理函数)
3. 登记快递类型(注册网络协议)
4. 安装窗口和架子(网卡驱动初始化 + Ring Buffer)
【快递到达处理】
快递到达 → 放到架子上 → 按门铃 → 你确认 → 员工处理 → 拆包裹分类 → 放信箱
(网卡) (Ring Buffer) (硬中断) (CPU) (软中断) (协议栈) (Socket)
【你拿快递】
方式1:守在信箱旁(同步阻塞)
方式2:看管多个信箱,有快递通知你(epoll多路复用)
【提高效率】
买大架子 → 多开窗口 → 批量通知 → 员工一次处理更多
一、系统启动准备
在Linux内核能够接收网络包之前,系统启动时需要进行一系列准备工作。这些准备包括创建软中断内核线程、注册软中断处理函数、注册网络协议、初始化网卡驱动以及分配和配置接收/发送队列。
1.1 创建软中断内核线程
Linux系统启动时,会为每个CPU核心创建一个软中断内核线程ksoftirqd。
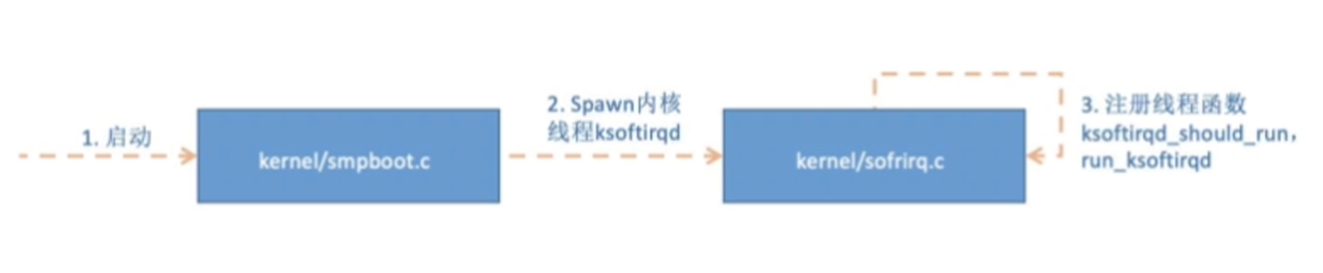
图片解析:
- 图中展示了从内核启动入口(
start_kernel)到软中断线程创建的完整调用链 - 核心函数调用:
spawn_ksoftirqd()→smpboot_register_percpu_thread()→ksoftirqd()线程函数 - 每个CPU核心都会创建一个对应的
ksoftirqd/n线程(n为CPU编号)
流程说明:
- Linux系统启动时,检测当前CPU核心数
- 为每个CPU核心创建一个对应的
ksoftirqd内核线程 - 每个线程的核心是一个无限循环,持续检查是否有待处理的软中断
- 当检测到软中断请求(
pending标志位)时,调用do_softirq()执行软中断处理函数 - 这种设计确保了软中断处理能够在合适的时机被调度执行
补充知识:
可以通过
ps -ef | grep ksoftirqd命令查看系统中的软中断线程,每个CPU核心对应一个线程。
1.2 注册软中断处理函数
系统启动时,需要注册各种类型的软中断及其处理函数。
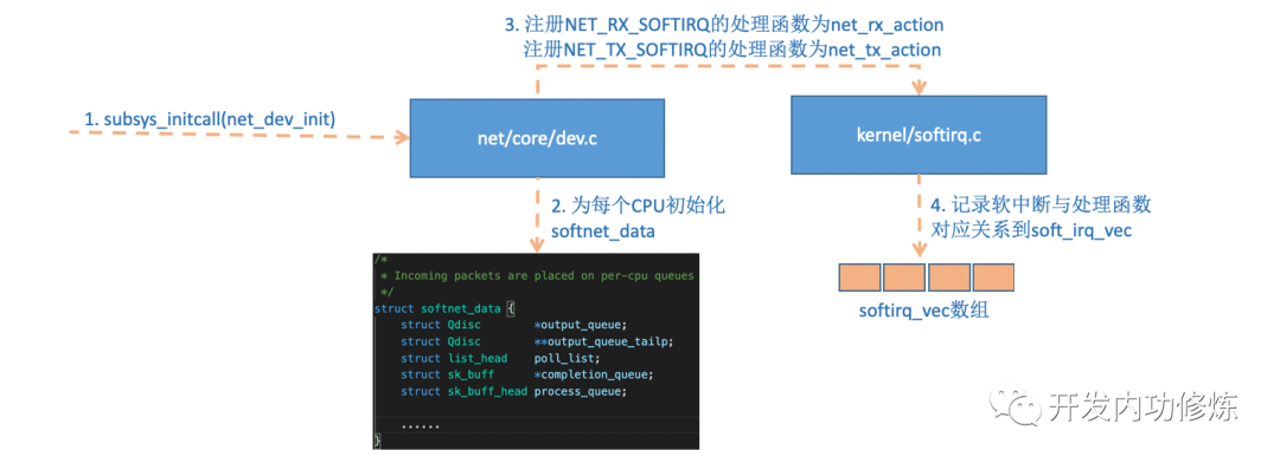
图片解析:
- 图中展示了软中断类型(
softirq_vec数组)及其对应处理函数的注册机制 - 网络相关的软中断类型:
NET_RX_SOFTIRQ:网络接收软中断,处理函数为net_rx_action()NET_TX_SOFTIRQ:网络发送软中断,处理函数为net_tx_action()
- 其他软中断类型还包括:
HI_SOFTIRQ(高优先级)、TIMER_SOFTIRQ(定时器)、TASKLET_SOFTIRQ(小任务)等
流程说明:
- 系统通过
open_softirq()函数注册软中断处理函数 - 每种软中断类型都有独立的优先级和对应的处理函数
- 网络包到达时,触发
NET_RX_SOFTIRQ,最终调用net_rx_action() - 网络包发送时,触发
NET_TX_SOFTIRQ,最终调用net_tx_action()
补充知识:
软中断是在编译时静态定义的,最多支持32种类型。网络收发占用两种类型,体现了网络处理在内核中的重要地位。
1.3 注册网络协议
内核需要注册各种网络协议,以便在数据包到达时能够找到对应的处理函数。
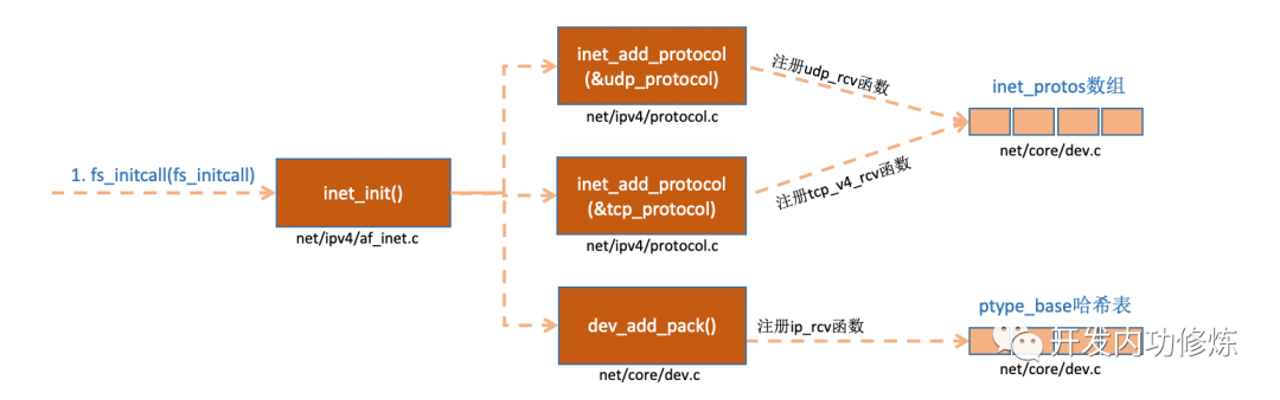
图片解析:
- 图中展示了网络协议的注册机制,使用
inet_add_protocol()函数注册各层协议 - 传输层协议注册到
inet_protos哈希表中,包括:- TCP协议:
tcp_protocol,处理函数tcp_v4_rcv() - UDP协议:
udp_protocol,处理函数udp_rcv() - ICMP协议:
icmp_protocol,处理函数icmp_rcv()
- TCP协议:
流程说明:
- 协议注册通过
inet_add_protocol(&proto, protocol)函数完成 - 第一个参数是
net_protocol结构体,包含协议号和回调函数 - 第二个参数是协议类型(如
IPPROTO_TCP、IPPROTO_UDP) - 当数据包到达协议栈时,根据IP头中的协议号查找对应的处理函数
- 这种设计使得内核可以动态支持多种网络协议,扩展性强
补充知识:
可以通过
cat /proc/net/protocols查看系统当前支持的所有网络协议及其状态。
1.4 网卡驱动初始化
每种网卡驱动加载时,都需要向内核注册网络设备。
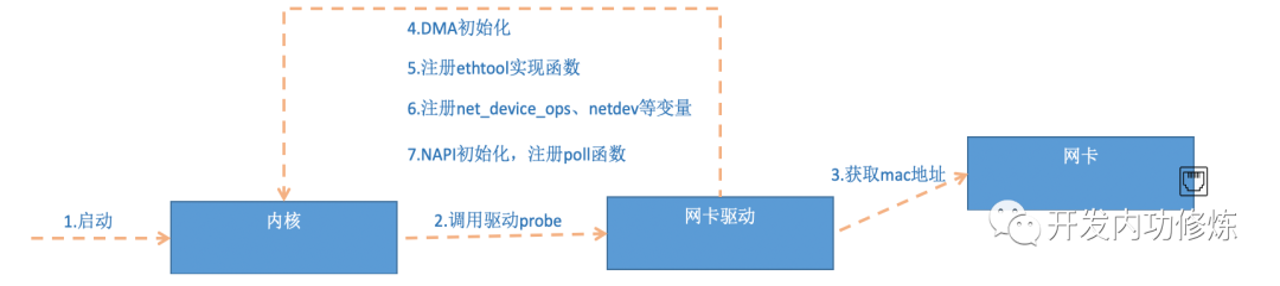
图片解析:
- 图中展示了网卡驱动初始化时向内核注册网络设备的过程
- 核心函数调用链:
driver_register()→register_netdev()→register_netdevice() - 驱动程序分配并初始化
net_device结构体
流程说明:
- 网卡驱动加载时,首先调用
alloc_etherdev()分配net_device结构 - 设置设备属性:name、mac、mtu、tx_queue_len等
- 注册设备操作函数:
ndo_open、ndo_stop、ndo_start_xmit、ndo_do_ioctl等 - 调用
register_netdev()向内核注册设备 - 内核创建
sysfs入口和proc接口,方便用户空间查询
补充知识:
可以通过
ethtool -i eth0查看网卡驱动信息,包括驱动版本、固件版本、总线信息等。
1.5 网卡启动与队列分配
当用户执行ifconfig eth0 up或ip link set eth0 up时,网卡正式启动并开始工作。

图片解析:
- 图中展示了网卡启动后的初始化流程
- 核心调用链:
dev_open()→ndo_open()→request_irq() ndo_open()是驱动实现的回调函数,负责:- 分配RX(接收)和TX(发送)队列的Ring Buffer
- 注册硬中断处理函数
- 使能网卡的DMA和中断功能
- 启动网卡队列
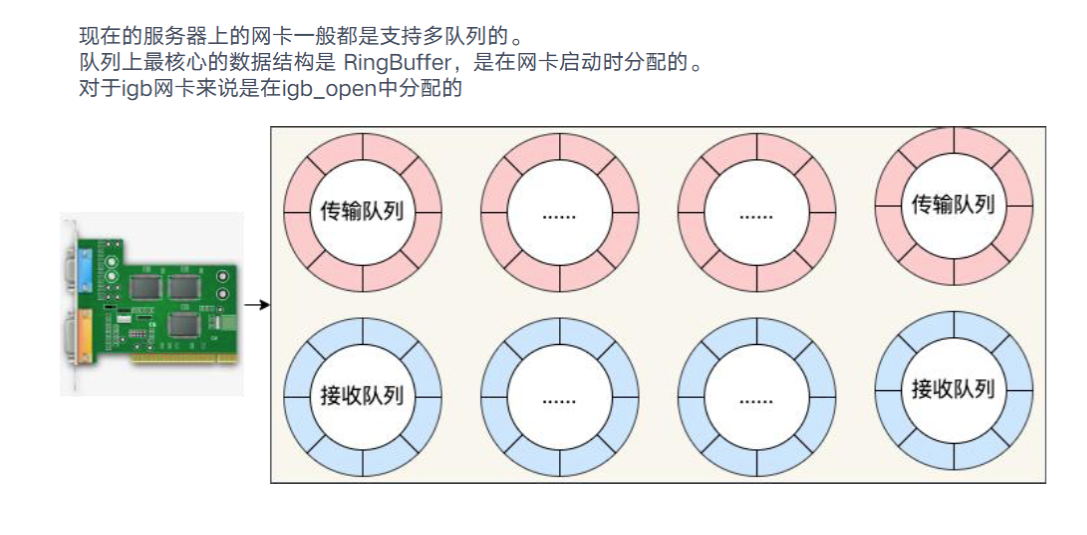
图片解析:
- 图中展示了Ring Buffer(环形缓冲区)的结构和工作原理
- Ring Buffer是网卡和内核之间传递数据包的内存队列
- 分为RX队列(接收队列)和TX队列(发送队列)
- 每个队列由一系列描述符(descriptor)组成,每个描述符指向一个sk_buff
- 采用环形结构,头尾指针循环移动,实现高效的数据传递
流程说明:
- 网卡驱动在启动时分配固定大小的Ring Buffer
- RX队列:网卡接收到数据包后,通过DMA将数据写入Ring Buffer,然后通知内核
- TX队列:内核将待发送的数据包放入Ring Buffer,网卡从中读取并通过DMA发送
- 当队列满时,新数据包会被丢弃(RX丢包)或阻塞(TX阻塞)
补充知识:
Ring Buffer大小直接影响网络性能。队列过小会导致丢包,过大会增加延迟。可以通过
ethtool -g eth0查看和调整。
二、网络包接收完整流程
当准备工作完成后,Linux内核就可以开始接收网络包了。一个网络包从网卡硬件到达应用程序,需要经历多个阶段。
2.1 总体流程概览
首先,让我们从宏观上看一下整个网络包接收流程。
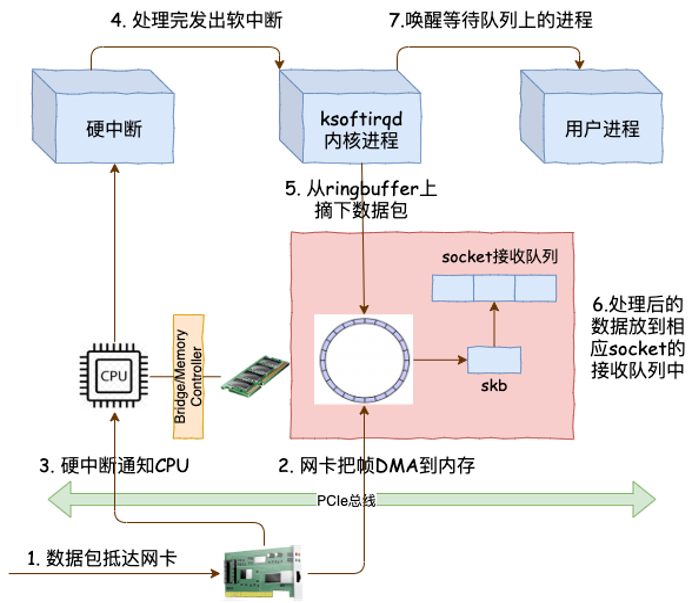
图片解析:
- 图中展示了从网卡接收到应用程序的完整数据包流程
- 主要分为4个阶段:
- 硬件接收:网卡通过DMA将数据包写入RX Ring Buffer
- 硬中断处理:网卡向CPU发起硬中断,CPU执行中断处理函数
- 软中断处理:
ksoftirqd线程调用net_rx_action()处理数据包 - 协议栈处理:数据包经过IP层、传输层,最终放入socket接收队列
流程说明:
- 网络包到达网卡硬件
- 网卡通过DMA直接将数据写入内核内存(Ring Buffer)
- 网卡完成DMA后向CPU发起硬中断(IRQ)
- CPU暂停当前任务,执行网卡驱动的中断处理函数
- 中断处理函数禁用网卡中断,触发
NET_RX_SOFTIRQ软中断 ksoftirqd线程被唤醒,执行软中断处理函数net_rx_action()net_rx_action()从Ring Buffer中取出数据包,交由协议栈处理- 协议栈解析数据包,最终将数据放入socket的接收队列
- 应用程序通过系统调用(如
recv())读取数据
补充知识:
整个过程从硬件到应用通常需要经过多次内存拷贝和协议解析,是网络性能优化的重点区域。
2.1 硬中断处理
当网卡接收到数据包后,会向CPU发起硬中断。硬中断处理要求快速完成,因此只做最必要的操作。
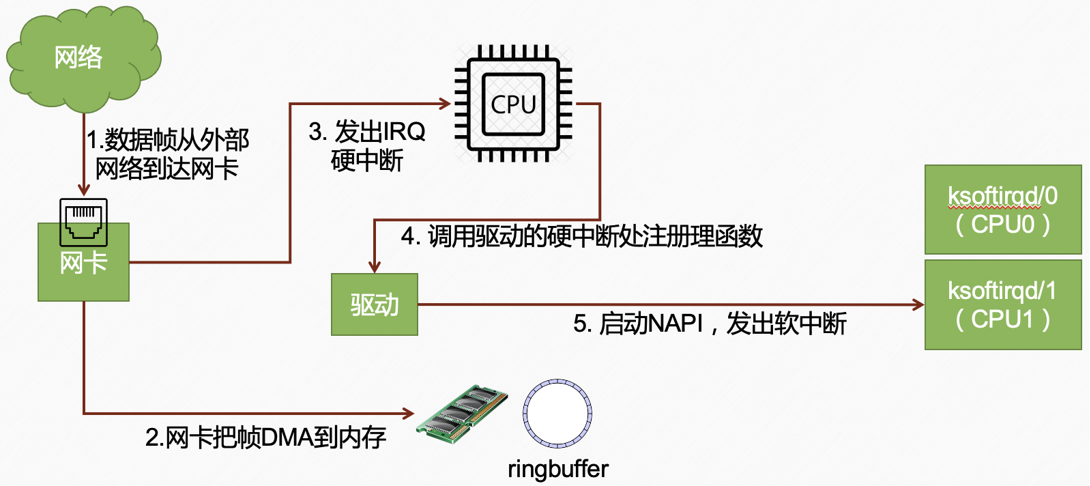
图片解析:
- 图中详细展示了硬中断处理的完整流程和时间线
- 硬中断处理的三个关键阶段:
- 中断响应:CPU收到中断信号,保存当前上下文
- 中断执行:执行中断处理函数(ISR)
- 中断返回:恢复上下文,继续执行之前的任务
流程说明:
- 网卡接收到数据包,通过DMA将数据写入内存
- 网卡向CPU发送硬件中断信号
- CPU完成当前指令后,响应中断
- 保存寄存器和程序计数器到内核栈
- 调用网卡驱动注册的中断处理函数
- 中断处理函数快速处理:
- 禁用网卡中断(NAPI模式)
- 记录接收的数据包
- 标记软中断待处理
- 中断处理函数返回,恢复上下文
- CPU继续执行之前的任务
为什么要分出硬中断和软中断?
硬中断优先级非常高,如果所有处理都在硬中断中完成:
- 在高流量场景下,CPU会一直处理网络包中断
- 用户进程无法得到CPU时间,系统响应变差
- 用户体验会严重下降
因此,Linux采用了硬中断+软中断的两阶段设计:
- 硬中断:快速响应硬件事件,做最小化的处理
- 软中断:在合适的时机处理剩余工作
CPU亲和性:
硬中断发生在哪个CPU核心上,软中断就在哪个核心上处理。这种设计可以利用CPU缓存,提高性能。
补充知识:
硬中断处理函数必须快速执行,通常要求在微秒级完成。这就是为什么复杂的处理被推迟到软中断中执行。
2.2 软中断处理
软中断是网络包接收的核心处理阶段,大部分工作都在这里完成。
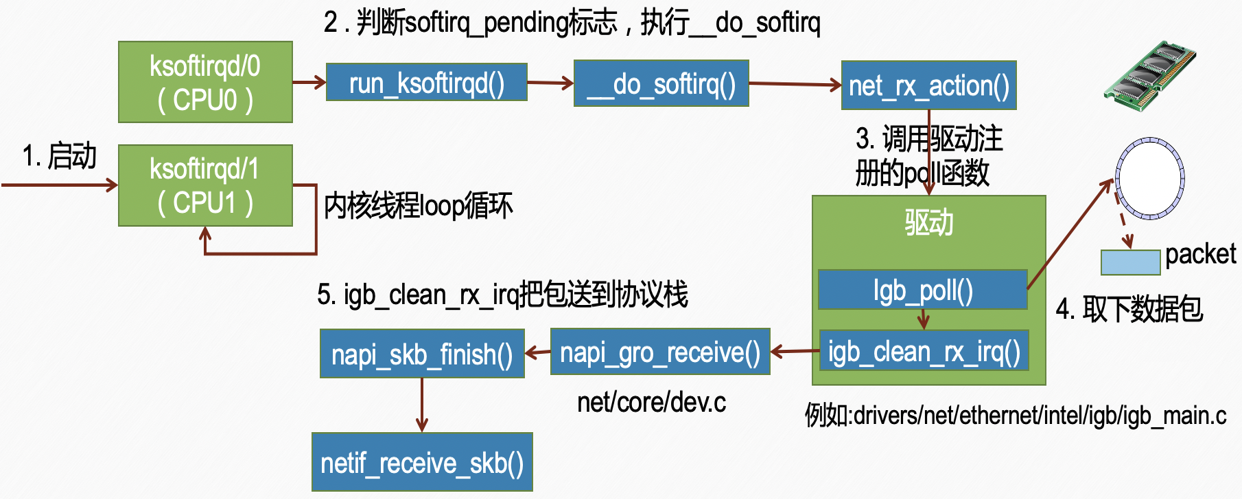
图片解析:
- 图中展示了软中断处理函数
net_rx_action()的执行流程 - 核心功能是从Ring Buffer中批量处理数据包
- 处理流程包括:
- 轮询网卡驱动的poll方法
- 从Ring Buffer中取出sk_buff
- 调用
netif_receive_skb()将数据包送入协议栈 - 处理权重(budget)控制,避免占用过多CPU时间
流程说明:
- 内核检测到
NET_RX_SOFTIRQ待处理 - 调用
net_rx_action()软中断处理函数 - 遍历所有待处理的网络设备
- 对每个设备调用其poll方法(通常为驱动实现的
xxx_poll()) - poll方法从RX Ring Buffer中取出数据包
- 将每个sk_buff传递给
netif_receive_skb() netif_receive_skb()根据数据包类型分发:- 如果是Packet Socket,直接交付
- 否则根据以太网类型分发到IP层或其他协议层
- 处理完budget个数据包(默认64)或队列为空后退出
- 如果还有数据包待处理,重新调度软中断
NAPI机制:
NAPI(New API)是现代网卡驱动采用的核心机制。其核心思想是中断和轮询结合:
- 低负载时:使用中断,降低延迟
- 高负载时:使用轮询,提高效率
这种设计在高流量场景下能够显著减少中断开销。
补充知识:
ksoftirqd线程在每个CPU核心上运行,处理该核心上的软中断任务。可以通过cat /proc/softirqs | grep NET查看各CPU的网络软中断统计。
2.3 协议栈处理
当数据包通过软中断处理后,接下来进入协议栈进行分层处理。
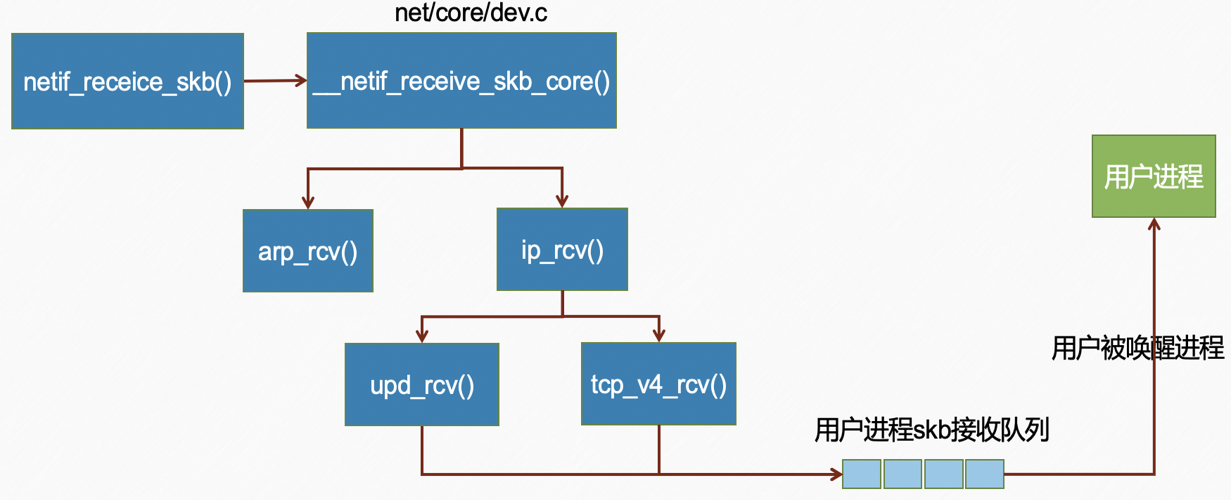
图片解析:
- 图中展示了网络协议栈各层处理数据包的详细流程
- 协议栈分层处理(从下到上):
- 链路层:处理以太网帧,解析以太网头
- 网络层:处理IP数据报,解析IP头,路由查找
- 传输层:处理TCP/UDP段,解析传输层头
- Socket层:将数据放入对应socket的接收队列
流程说明:
链路层处理:
- 剥离以太网帧头
- 根据以太网类型字段(0x0800表示IPv4)分发
网络层处理(ip_rcv()):
- 检查IP头部校验和
- 处理IP选项
- 查找路由表确定数据包去向
- 根据IP协议字段分发到传输层
传输层处理:
- TCP:
tcp_v4_rcv()→ 查找socket → 处理TCP状态机 → 放入接收队列 - UDP:
udp_rcv()→ 查找socket → 放入接收队列
Socket层:
- 数据被添加到socket的
sk_receive_queue队列 - 唤醒等待的进程(如果有)
补充知识:
协议栈处理是CPU密集型操作。在高性能场景下,可以通过零拷贝、DPDK等技术绕过内核协议栈以提升性能。
三、内核与用户进程协作
当网络数据到达socket接收队列后,内核需要通知用户进程,用户进程通过系统调用读取数据。Linux提供了多种IO模型来实现内核和用户进程的协作。
同步阻塞也好,多路复用也好,本质上都是内核和用户进程之间的一种协作机制。
3.1 同步阻塞IO模型
同步阻塞是最传统、最简单的IO模型。
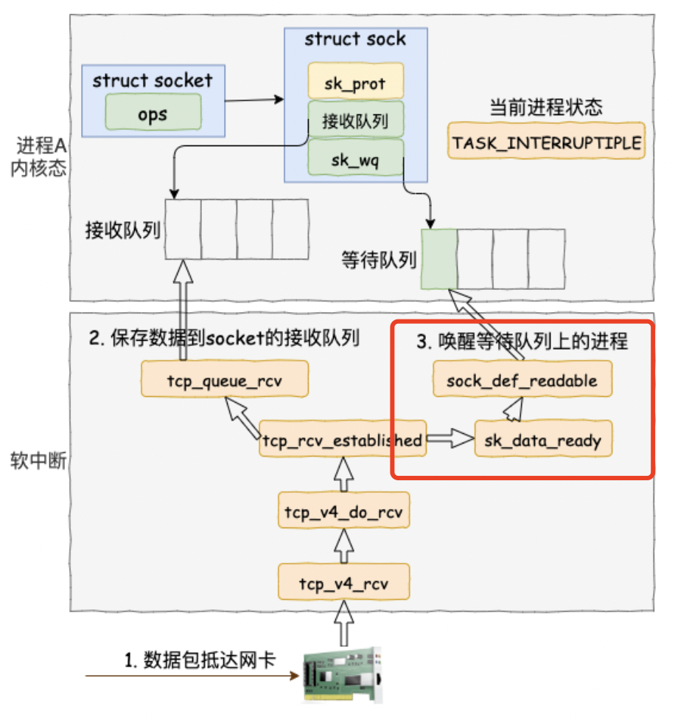
图片解析:
- 图中展示了同步阻塞IO模型的工作原理和数据流向
- 应用程序调用
recv()系统调用后的流程:- 应用程序进入内核态
- 检查socket接收队列是否有数据
- 如果没有数据,进程进入睡眠状态(阻塞)
- 当数据到达时,内核唤醒进程
- 进程将数据从内核空间复制到用户空间
- 返回用户态继续执行
流程说明:
- 应用程序发起系统调用(如
recv()、read()) - 内核检查socket接收队列
- 如果队列为空,进程状态设为
TASK_INTERRUPTIBLE,进程被移出CPU运行队列 - 当网络包到达时,协议栈将数据放入接收队列,内核唤醒阻塞在socket上的进程
- 进程被调度器选中后继续执行
- 将数据从内核空间复制到用户空间
- 系统调用返回,应用程序处理数据
优点和缺点:
- ✅ 优点1:实现简单,编程模型直观
- ✅ 优点2:不会浪费CPU时间空转
- ❌ 缺点1:一个线程只能处理一个连接,并发能力差
- ❌ 缺点2:需要为每个连接创建线程,资源消耗大
适用场景:
同步阻塞IO适用于连接数较少的场景。现代高并发服务器很少使用这种模型。
3.2 IO多路复用模型
IO多路复用是现代高并发服务器的主流选择,它允许一个线程同时管理多个连接。
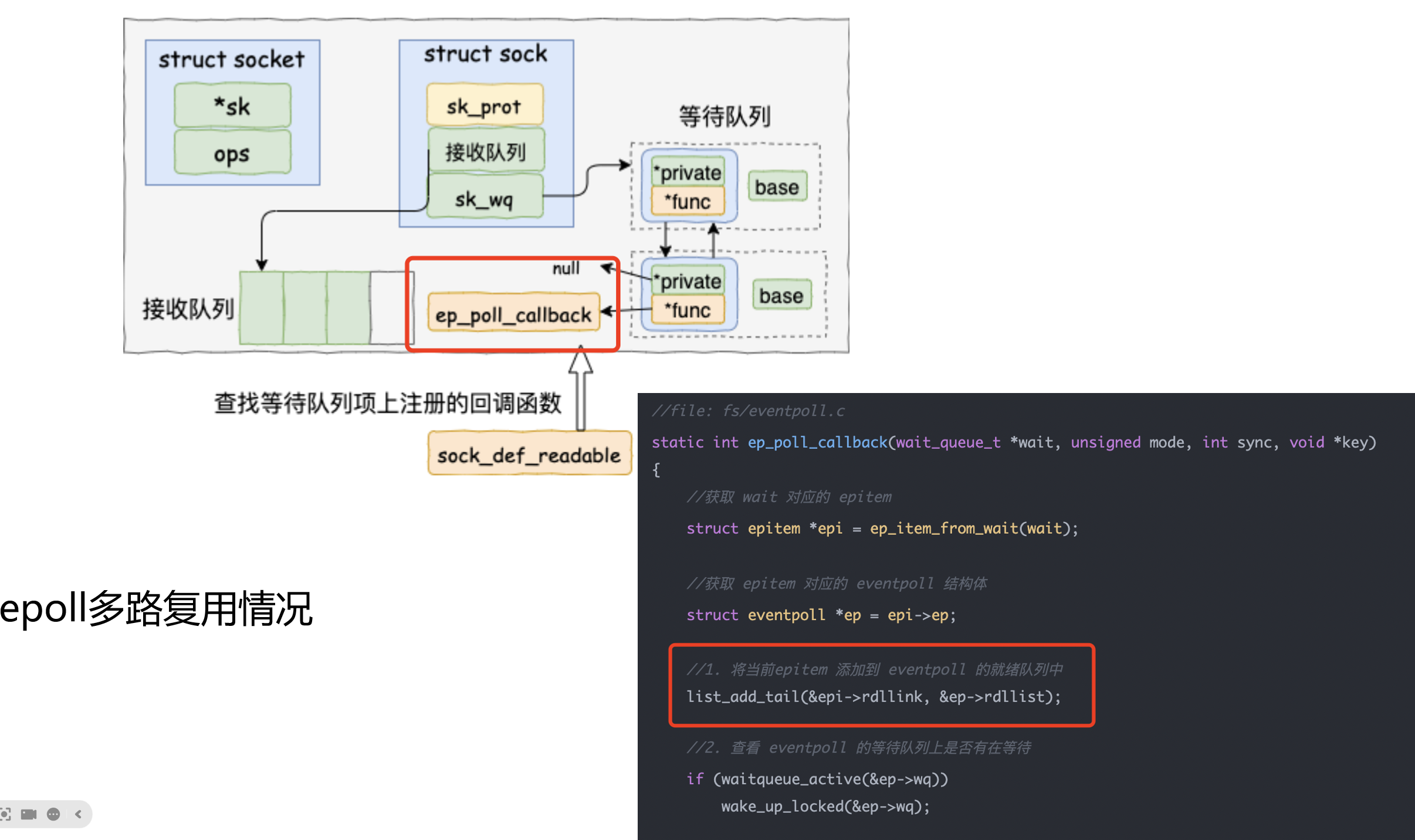
图片解析:
- 图中展示了IO多路复用模型的工作原理
- 多路复用的核心思想:一个线程同时监控多个socket
- 涉及三个关键操作:
- select/poll/epoll_create:创建监控集合,添加需要监控的socket
- select/poll/epoll_wait:阻塞等待,直到有socket就绪
- recv/read:对就绪的socket进行读写操作
流程说明:
- 应用程序创建多个socket连接
- 将所有socket添加到监控集合(如epoll实例)
- 调用
epoll_wait()阻塞等待 - 内核监控所有socket的状态
- 当任意一个或多个socket就绪时,
epoll_wait()返回 - 应用程序遍历就绪的socket列表
- 对每个就绪的socket调用
recv()读取数据 - 处理完所有就绪socket后,再次调用
epoll_wait()等待
与同步阻塞的区别:
- 同步阻塞:一个线程管理一个连接
- IO多路复用:一个线程管理多个连接
- 多路复用通过系统内核的监控能力,实现高效的并发处理
三种实现比较:
| 特性 | select | poll | epoll |
|---|---|---|---|
| 最大连接数 | 1024(受FD_SETSIZE限制) | 无限制 | 无限制 |
| 时间复杂度 | O(n) | O(n) | O(1) |
| 内存拷贝 | 每次调用都拷贝 | 每次调用都拷贝 | 通过mmap避免拷贝 |
| 跨平台 | 是 | 是 | 仅Linux |
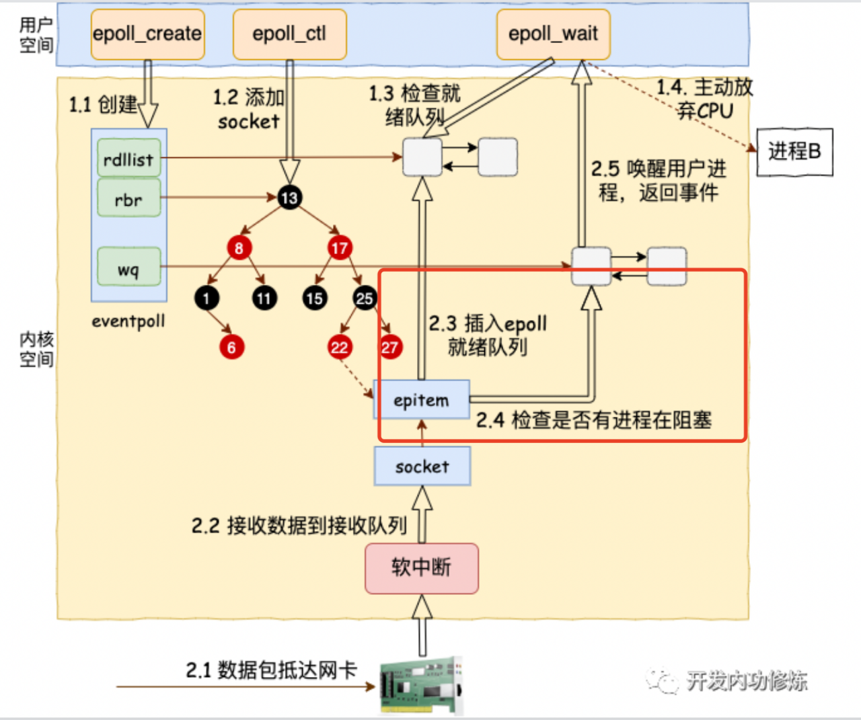
epoll详细机制:
epoll的三大核心函数:
- epoll_create:创建epoll实例,在内核中创建eventpoll结构
- epoll_ctl:添加、删除或修改监控的socket,维护红黑树和就绪链表
- epoll_wait:等待事件就绪,检查就绪链表是否为空
epoll在内核中的数据结构:
- 红黑树:存储所有监控的socket
- 就绪链表:存储已经就绪的socket
流程说明:
- 创建阶段:应用程序调用
epoll_create(1)创建epoll实例,内核分配eventpoll结构 - 注册阶段:调用
epoll_ctl()将socket添加到红黑树,注册回调函数ep_poll_callback() - 等待阶段:调用
epoll_wait()检查就绪链表,如果为空则阻塞 - 事件通知:当socket就绪时,回调函数将socket添加到就绪链表,唤醒等待的进程
- 返回阶段:
epoll_wait()返回就绪的socket列表,应用程序遍历处理
epoll的两种触发模式:
-
水平触发(LT - Level Triggered):默认模式
- 只要条件满足就持续通知
- 编程更简单,不容易出错
- 适合大多数场景
-
边缘触发(ET - Edge Triggered):
- 只在状态变化时通知一次
- 更高效,但编程复杂
- 必须使用非阻塞IO
- 需要一次性读完所有数据(直到EAGAIN)
补充知识:
epoll的高效性体现在:O(1)的时间复杂度、不需要每次都重新传递监控集合、基于mmap的零拷贝机制。它是Linux特有的I/O事件通知机制,支持百万级并发连接。
四、网络包接收性能优化
在高流量场景下,需要对网络包接收过程进行优化,以提升系统性能。以下是几种主要的优化方法。
4.1 监控CPU开销
首先,我们需要了解如何监控网络处理对CPU的占用情况。
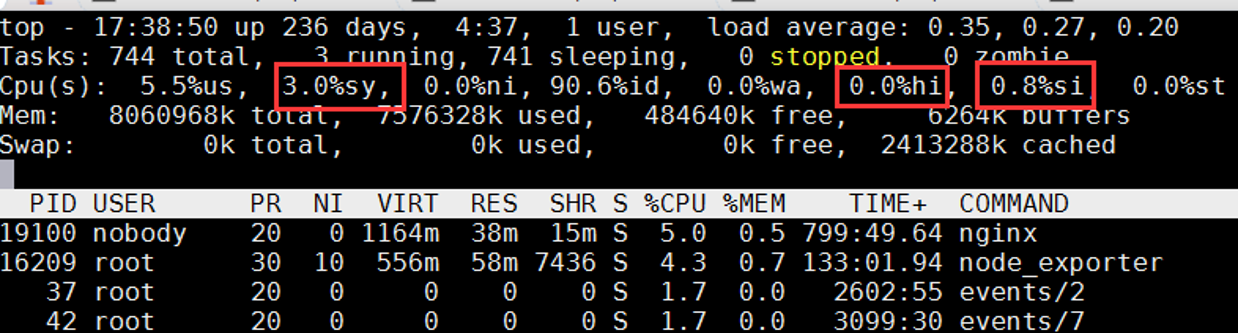
图片解析:
- 图中展示了
top命令的输出界面,重点标记了CPU时间分配 - 关键指标:
- hi (hardware IRQ):硬中断占用的CPU时间
- si (software IRQ):软中断占用的CPU时间
性能判断标准:
- 正常情况:si < 5%,表示网络处理正常
- 轻度负载:5% < si < 15%,需要关注
- 重度负载:si > 15%,可能存在性能瓶颈
- 异常情况:某个CPU的si特别高,说明网络负载不均衡
补充知识:
可以通过
mpstat -P ALL 1查看每个CPU核心的中断情况,判断是否需要调整RSS或CPU亲和性。
4.2 优化1:Ring Buffer扩大
Ring Buffer过小会导致丢包,扩大Ring Buffer是解决丢包问题的有效方法。

Ring Buffer:环形缓冲区,网卡驱动和内核之间用于传递网络包的内存队列。
图片解析:
- 图中对比了Ring Buffer过小和扩大后的效果
- 问题场景:Ring Buffer过小 → 网络包突发时队列填满 → 新数据包被丢弃
- 优化后:Ring Buffer扩大 → 可以缓存更多数据包 → 给软中断处理更多时间
优化方法:
# 查看当前Ring Buffer设置
ethtool -g eth0
# 临时修改RX/TX Ring Buffer大小
ethtool -G eth0 rx 4096 tx 4096
# 永久修改(写入网络配置)
# /etc/sysconfig/network-scripts/ifcfg-eth0
ETHTOOL_OPTS="-G eth0 rx 4096 tx 4096"
调优建议:
- 一般场景:rx=1024, tx=1024
- 高流量场景:rx=4096, tx=4096
- 极高流量:rx=8192或更高
- 注意:Ring Buffer越大,占用内存越多,延迟也可能略高
4.3 优化2:多队列网卡RSS调优
RSS(Receive Side Scaling)可以将网络包分发到不同的接收队列,实现多核并行处理。
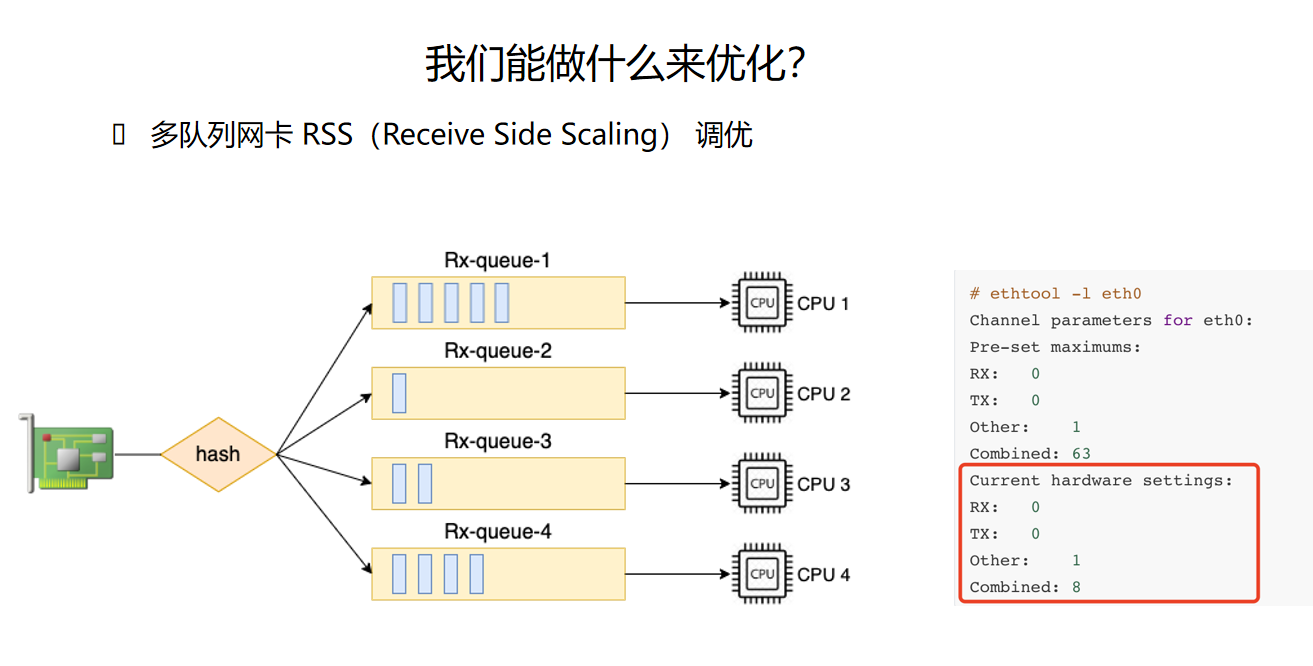
RSS (Receive Side Scaling):网卡硬件特性,可以将网络包根据哈希分发到不同的接收队列,实现多核并行处理。
图片解析:
- 图中展示了多队列网卡的工作原理和数据包分发机制
- RSS工作流程:网卡接收数据包 → 硬件计算hash值 → 选择接收队列 → 触发对应CPU的中断 → 并行处理
哈希输入:
源IP、目的IP、源端口、目的端口、协议号
队列选择:
hash % queue_count,确保同一连接的数据包去往同一队列
优化方法:
# 查看网卡队列数
ethtool -l eth0
# 查看当前RSS配置
ethtool -x eth0
# 修改RSS队列数(需要驱动支持)
ethtool -L eth0 combined 8
# 设置RSS间接表(手动控制队列分配)
ethtool -X eth0 equal 8
调优建议:
- 队列数应该匹配CPU核心数或略少
- 对称多路(SMP)系统:队列数 = 物理CPU数
- NUMA系统:队列数 = NUMA节点数 × 每节点核心数
- 避免队列数过多,导致上下文切换开销大
性能提升:
- 单队列vs多队列:性能提升2-8倍
- 充分利用多核CPU的并行处理能力
- 减少单个CPU的软中断负载
4.4 优化3:硬中断合并
硬中断合并可以降低中断频率,减少CPU开销。

图片解析:
- 图中展示了硬中断合并(Interrupt Coalescing)的工作原理
- 未启用合并:每个数据包都触发一次中断 → 高流量下中断频率极高
- 启用合并后:累积多个数据包或到达时间阈值后触发中断 → 大幅降低中断频率
合并参数:
- rx-usecs:延迟触发中断的最大微秒数
- rx-frames:累积多少帧后触发中断
优化方法:
# 查看当前中断合并设置
ethtool -c eth0
# 设置中断合并参数
ethtool -C eth0 rx-usecs 50 rx-frames 32
# 激进合并(高吞吐优先)
ethtool -C eth0 rx-usecs 100 rx-frames 64
# 保守合并(低延迟优先)
ethtool -C eth0 rx-usecs 10 rx-frames 8
调优建议:
- 高吞吐场景:增大合并参数,降低中断频率
- 低延迟场景:减小合并参数,及时处理数据包
- 需要在延迟和吞吐之间找到平衡点
性能影响:
- 启用合并后,中断频率可降低50%-90%
- 可能增加几十到几百微秒的延迟
4.5 优化4:软中断合并
软中断合并通过一次处理多个数据包来减少软中断调度开销。
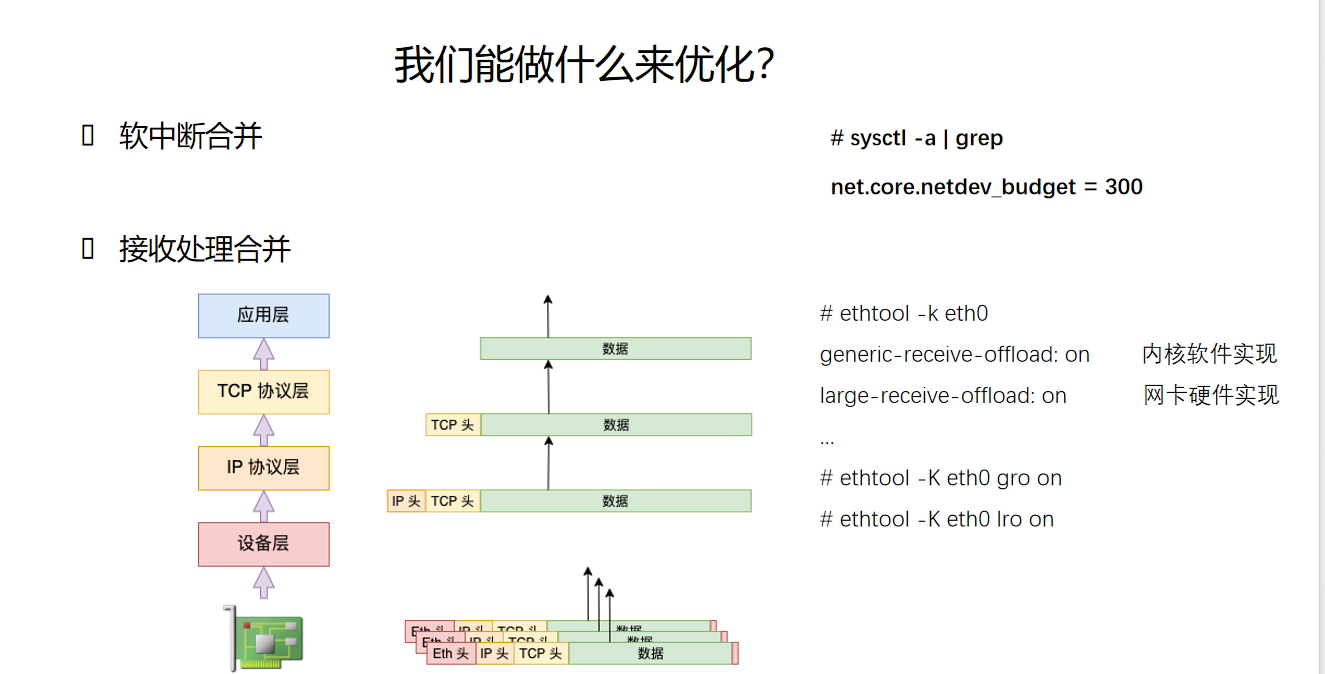
图片解析:
- 图中展示了软中断合并的工作机制
- 问题场景:每个数据包都触发一次软中断 → 高流量下软中断频繁调度
- 软中断合并机制:一次软中断处理多个数据包 → 减少软中断调度次数
软中断处理逻辑:
// 简化的net_rx_action()伪代码
int net_rx_action() {
int work = 0;
while (work < budget && !list_empty(&poll_list)) {
work += napi->poll(napi, weight); // 处理数据包
}
if (work < budget) {
__napi_complete(napi); // 完成本次处理
} else {
__raise_softirq_irqoff(NET_RX_SOFTIRQ); // 重新调度
}
return work;
}
相关内核参数:
# 查看软中断预算
cat /proc/sys/net/core/netdev_budget
# 默认值:300,表示一次软中断最多处理300个包
# 查看软中断最大处理时间(微秒)
cat /proc/sys/net/core/netdev_budget_usecs
# 默认值:2000,表示最多处理2毫秒
# 临时修改
echo 600 > /proc/sys/net/core/netdev_budget
# 永久修改(/etc/sysctl.conf)
net.core.netdev_budget = 600
net.core.netdev_budget_usecs = 3000
调优建议:
- 高流量场景:增大budget值(如600-1000)
- 多核系统:每个CPU有独立的软中断处理
- 注意:budget过大可能影响其他任务的响应速度
性能影响:
- 合理设置budget可提升30%-50%的网络吞吐
- 减少软中断调度和上下文切换开销
五、实际应用场景与监控
5.1 什么时候需要关注网络包接收性能?
- 高并发场景:服务器需要处理大量客户端连接时(如Web服务器、API网关)
- 低延迟要求:实时性要求高的应用(如在线游戏、金融交易)
- 网络吞吐量瓶颈:通过
top或mpstat发现si(软中断)占用CPU过高 - 丢包问题:通过
netstat -su或/proc/net/softnet_stat发现丢包
5.2 常用监控命令
# 查看软中断统计
cat /proc/net/softnet_stat
# 查看网络丢包统计
netstat -su | grep "packet receive errors"
# 查看网络队列长度
ethtool -g eth0
# 查看硬中断分布
cat /proc/interrupts | grep eth
# 查看软中断CPU占用
top # 查看si指标
mpstat -P ALL 1 # 查看每个CPU的软中断
5.3 调优建议总结
- Ring Buffer:根据流量情况增大,避免因队列满导致丢包
- RSS配置:确保队列数匹配CPU核心数,充分利用多核
- 中断合并:在高吞吐场景下开启,降低中断频率
- CPU亲和性:将网络处理绑定到特定CPU核心,减少缓存失效
六、参考资料
书籍
- 《深入理解Linux网络》 第二章、第三章、第九章
文章
- 图解Linux网络包接收过程
- Linux网络包接收过程的监控与调优
- 图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!
- 图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO
- 漫画 | 看进程小 P 讲述它的网络性能故事!