
tags:
- 网络
- 内核
- Linux
- TCP
- 网络包发送
category: 网络管理
created: 2026-04-18
updated: 2026-04-18
内核是如何发送网络包的
这篇笔记的目标不是背函数名,而是把“一个网络包为什么能从应用程序走到网卡”这件事串起来。先记住一句话:发送网络包,就是应用把数据交给 socket,TCP 决定怎么切、什么时候发,IP 决定从哪条路走,邻居子系统补上 MAC 地址,qdisc 和驱动把包交给网卡,网卡再把它变成电/光信号发出去。
目录
- 一、先建立整体图景
- 二、应用调用 send 之后发生了什么
- 三、TCP 层:不是每次 send 都立刻上网线
- 四、IP 层:查路由、过 netfilter、处理 MTU
- 五、邻居子系统:IP 地址怎么变成 MAC 地址
- 六、网络设备层:qdisc、发送队列和驱动
- 七、发送完成:为什么还会有中断和软中断
- 八、性能优化:哪些地方真的会省 CPU
- 九、用一条主线把所有细节串起来
- 十、常用观测命令
- 十一、参考资料
一、先建立整体图景
1.1 用“寄快递”理解发送过程
可以把一次发送理解成寄快递:
| 寄快递动作 | Linux 发送网络包 |
|---|---|
| 你把东西交给快递员 | 应用调用 send()、write()、sendmsg() |
| 快递员先把东西放进公司系统 | 内核把用户数据拷贝到 socket 发送缓冲区,形成 sk_buff |
| 快递公司判断是否现在发车 | TCP 根据窗口、Nagle、TCP_CORK 等判断是否推送 |
| 分拣中心贴上运输单号 | TCP 添加端口、序号、ACK 号、校验和等信息 |
| 查询路线 | IP 查路由,选择出口网卡和下一跳 |
| 查下一站的具体门牌 | 邻居子系统通过 ARP 获取下一跳 MAC 地址 |
| 排队装车 | qdisc 根据队列规则排序、限速或丢弃 |
| 司机把货装上车 | 网卡驱动把 skb 映射给网卡,填 TX Ring |
| 车真正开出去 | 网卡 DMA 读取数据并发到物理链路 |
| 发车后回收单据 | 发送完成后驱动清理描述符、释放 skb |
这张图是整条链路的高度概括:
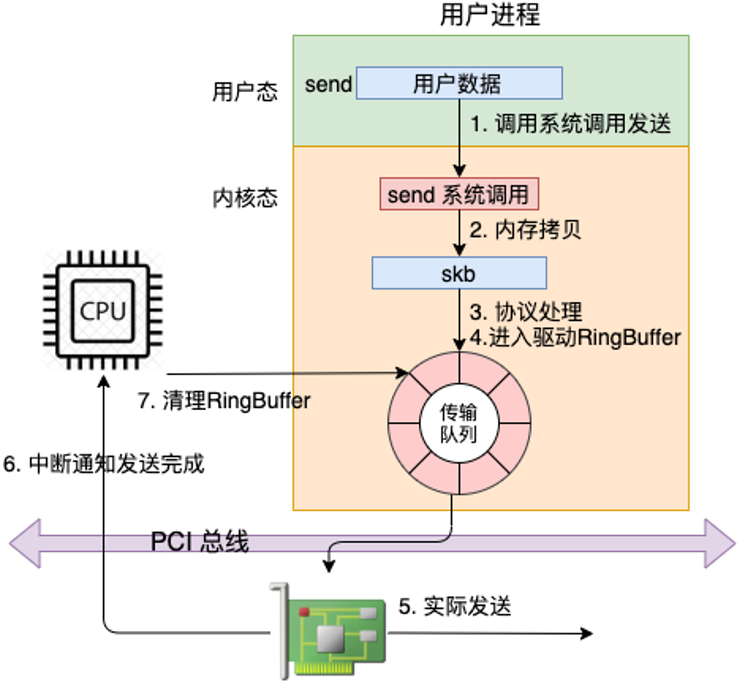
读图重点:
send不是直接操作网卡。它先进入内核,经过 socket、TCP/IP 协议栈、网络设备层、驱动,最后才到网卡。- 大部分发送工作发生在发起
send()的进程的内核态,也就是这个进程从用户态陷入内核态以后顺手完成很多事。 - 网卡发送完成后还需要清理 TX Ring 和释放 skb,所以“发出去”并不等于“内核完全不管了”。
1.2 图片对应性检查
原文里有几处图片和内容错位,我已经在本文中重新调整:
| 原问题 | 修正方式 |
|---|---|
tcp_push() 章节放成了邻居子系统和 dev_queue_xmit() 图 |
改为“启动发送时机”图 |
tcp_write_xmit() 章节放成了驱动图 |
改为 tcp_write_xmit()、tcp_transmit_skb() 图 |
ip_queue_xmit() 章节放成了 TCP 图 |
改为路由、netfilter、MTU 图 |
| ARP 章节放成了 IP/netfilter 图 | 改为文字解释 ARP,避免误导 |
| 发送完成章节重复使用同一张图,且解释成“因为 ACK 所以 RX_SOFTIRQ” | 改为更准确的 NAPI/驱动完成处理说明 |
1.3 源码主线
这张图展示了从用户态 send() 到协议栈入口的大致路径:



你可以先背下这条主线,后面的所有细节都挂在它上面:
应用程序
send() / write() / sendmsg()
↓
系统调用层
__sys_sendto()
sock_sendmsg()
↓
协议族和协议层
inet_sendmsg()
tcp_sendmsg()
↓
TCP 输出
tcp_push()
tcp_write_xmit()
tcp_transmit_skb()
↓
IP 输出
ip_queue_xmit()
__ip_local_out()
ip_output()
ip_finish_output()
↓
邻居子系统
dst_neigh_output()
neigh_hh_output()
↓
网络设备层
dev_queue_xmit()
__dev_xmit_skb()
dev_hard_start_xmit()
↓
网卡驱动
ndo_start_xmit()
↓
网卡硬件
TX Ring / DMA / 物理链路
注意:不同内核版本、协议、网卡驱动、是否启用 offload,函数细节会略有不同;但这条“从 socket 到协议栈,再到设备层和驱动”的方向不变。
二、应用调用 send 之后发生了什么
2.1 send() 的返回值容易误解
应用代码通常长这样:
send(fd, buf, len, 0);
write(fd, buf, len);
send() 成功返回,只能说明:内核接受了这些数据,或者至少接受了其中一部分数据。 它不等价于:
- 数据已经到达对端;
- 数据已经离开本机网卡;
- 对端应用已经读到了数据。
对于 TCP 来说,send() 面对的是一个字节流。应用把字节交给内核,内核再根据 MSS、窗口、拥塞控制、Nagle、qdisc、网卡状态等因素决定实际发送节奏。
2.2 tcp_sendmsg() 做的核心事情
这张图展示了协议栈中数据拷贝和发送队列的关系:
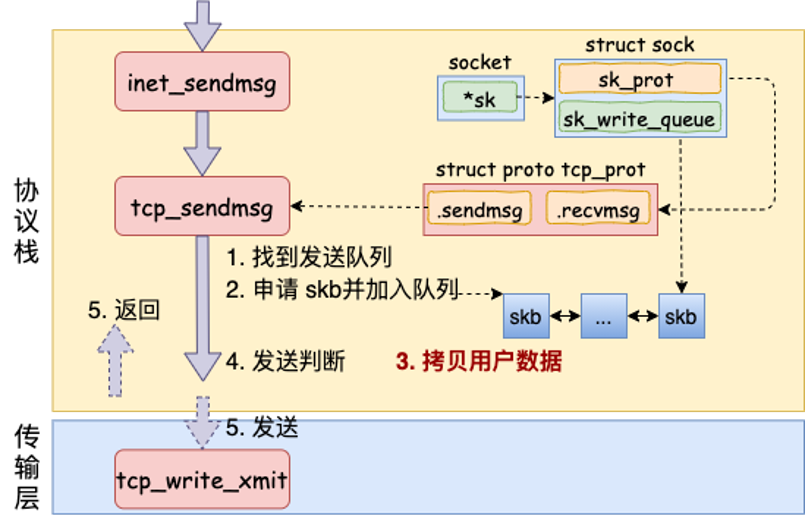
tcp_sendmsg() 可以理解成“把用户数据变成 TCP 待发送数据”的入口。它主要做几件事:
-
检查 socket 状态
- 连接是否建立;
- 是否有错误;
- 发送缓冲区是否还有空间。
-
按 MSS 或当前发送目标组织数据
- MSS 是 TCP 层单个报文段能承载的最大数据量;
- 应用传进来的大块数据,可能被拆成多个 skb;
- 如果启用 GSO/TSO,内核也可能先保留一个“大 skb”,晚点再分段。
-
申请或复用
sk_buffsk_buff是 Linux 内核网络栈里表示一个包的核心结构;- 它本身主要是元数据,真正的数据在关联的缓冲区或 page fragment 里;
- TCP 为了重传,常会保留原始 skb,再把克隆出来的 skb 往下层传。
-
从用户态拷贝数据到内核态
- 普通
send()会发生用户缓冲区到内核缓冲区的拷贝; sendfile()、splice()、MSG_ZEROCOPY等可以减少某些场景下的数据拷贝。
- 普通
-
把 skb 挂到 socket 的发送队列
- 常说的
sk_write_queue就是 TCP 还需要管理的一批待发送数据; - 这里的“待发送”不一定表示它已经进网卡队列。
- 常说的
2.3 sk_buff 不只是“一个包”
sk_buff 可以先粗略理解成快递面单加包裹索引:
struct sk_buff
├─ 指向数据区的位置:head / data / tail / end
├─ 各层头部位置:MAC 头 / IP 头 / TCP 头
├─ 长度、校验和、GSO 信息
├─ 路由信息 dst
├─ 所属 socket
└─ 链表指针,用来挂到各种队列上
它的厉害之处在于:各层协议不需要反复复制整包数据,很多时候只是在 skb 的头部预留区里“往前加头”,或者克隆 skb 元数据。
这也是为什么内核网络栈经常讨论“拷贝数据”和“克隆 skb 头部”之间的区别:前者真的搬动字节,后者更多是在改元数据。
三、TCP 层:不是每次 send 都立刻上网线
3.1 tcp_push():决定要不要推动发送
这张图对应的是 tcp_sendmsg() 里的“发送判断”:

这里很关键:应用调用了 send(),不代表 TCP 马上发一个包。
TCP 会考虑:
- 现在是否有足够多的数据组成一个 MSS;
- 之前的小包是否还没有被 ACK;
- 是否启用
TCP_NODELAY禁用 Nagle; - 是否启用
TCP_CORK暂时攒包; - 发送窗口是否允许继续发送;
- 拥塞窗口是否允许继续发送;
- 当前 skb 是否是发送队列队头;
- 是否到了必须 flush 的时机。
原视频里提到的两个判断点可以这样理解:
| 判断 | 直观含义 |
|---|---|
forced_push(tp) |
未发送的数据已经攒到一定程度,不能再一直等 |
skb == tcp_send_head(sk) |
当前 skb 正好是发送队列中下一个可以推进的包 |
但不要把它们理解成 TCP 发送的全部条件。真正能不能发,还要继续经过窗口、拥塞控制、MSS、TSO/GSO、qdisc、驱动队列等检查。
3.2 Nagle、TCP_NODELAY 和 TCP_CORK
初学时最容易卡住的是:“为什么我明明 send 了,抓包却没马上看到?”
原因之一就是 TCP 可能在攒小包。
| 机制 | 作用 | 适合场景 |
|---|---|---|
| Nagle 算法 | 尽量把小数据合并,减少小包数量 | 普通吞吐场景 |
TCP_NODELAY |
禁用 Nagle,小数据也尽快发 | 低延迟交互、RPC、小请求 |
TCP_CORK |
明确告诉内核先别发零碎包,等我凑完整再发 | 先发响应头再发文件、吞吐优化 |
一个简单判断:
- 如果你关心延迟,比如游戏、交易、短 RPC,常会考虑
TCP_NODELAY。 - 如果你关心吞吐,比如大文件、视频、日志批量传输,常希望批量发送,减少小包。
3.3 tcp_write_xmit():TCP 发送的总调度
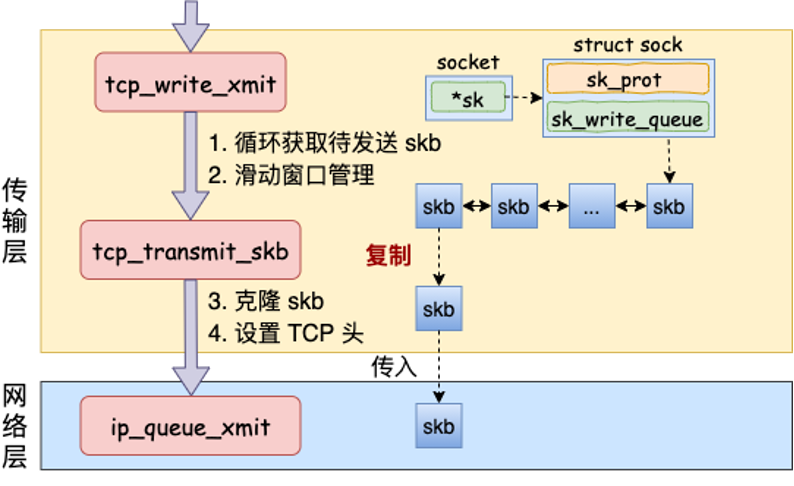
这张图展示了 tcp_write_xmit() 到 tcp_transmit_skb() 的关系:
tcp_write_xmit() 更像 TCP 输出路径的调度器。它循环查看发送队列里的 skb,然后判断:
-
接收窗口
rwnd够不够- 对端通过 ACK 告诉你它还能接收多少数据;
- 这是流量控制,防止把对端接收缓冲区打爆。
-
拥塞窗口
cwnd够不够- 本机根据网络拥塞情况控制发送量;
- 这是拥塞控制,防止把网络打爆。
-
MSS 和分段是否合适
- 普通情况下 TCP 尽量按 MSS 分段;
- 开启 GSO/TSO 时,可以先让一个大 skb 往下走,晚点再分段。
-
是否需要设置 PSH、FIN 等标志
- PSH 不是“必须马上交给应用”的强制命令;
- 它更像一个提示,实际行为还受接收端协议栈影响。
-
是否需要重传
- TCP 发送出去的数据,在收到 ACK 之前不能简单丢掉;
- 一旦超时或快速重传条件满足,TCP 要能重新发送。
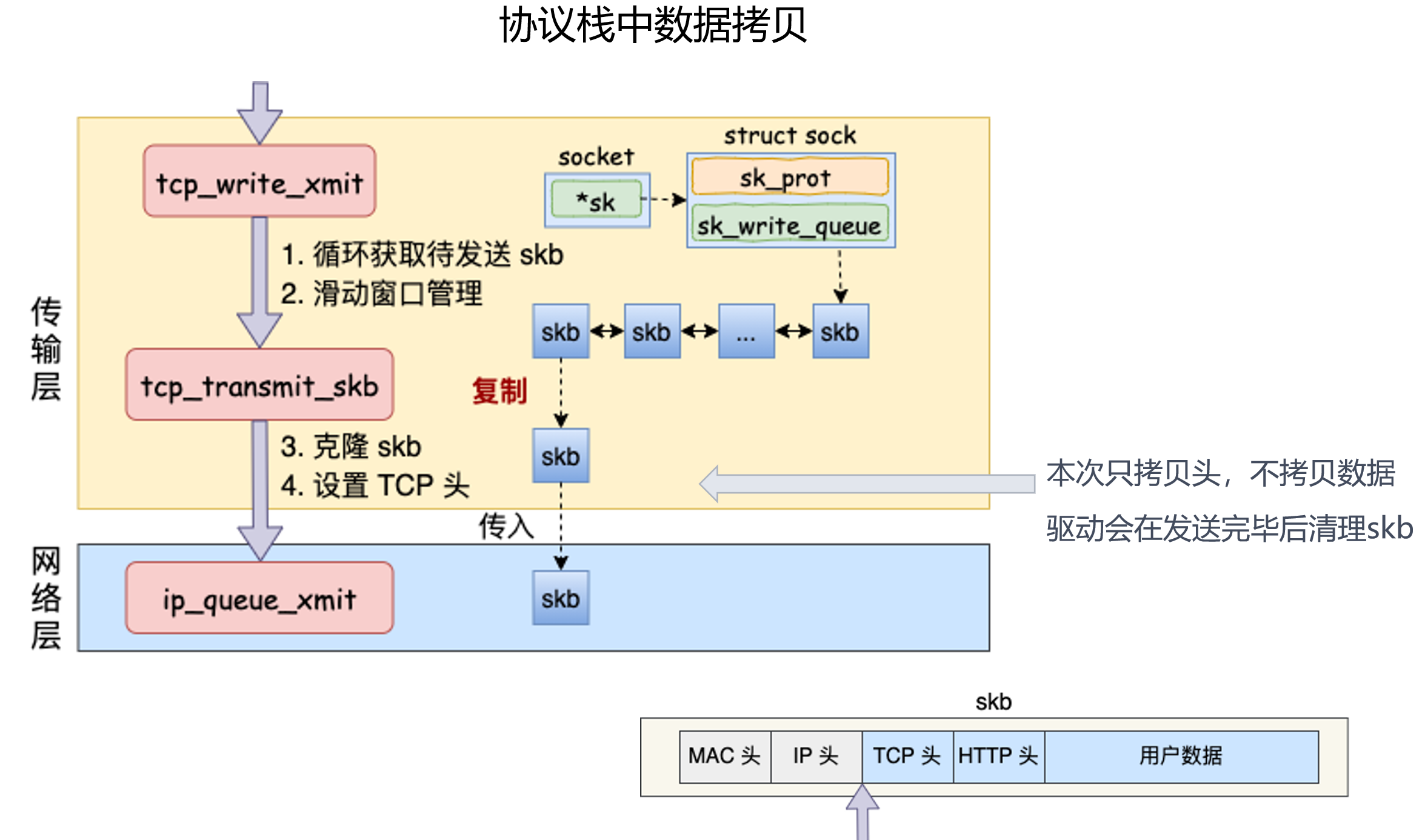
3.4 tcp_transmit_skb():克隆 skb,补 TCP 头
发送时 TCP 不一定把原 skb 直接交给下层。为了重传,TCP 常会:
发送队列中的 skb
↓ 克隆一份用于下发
下发 skb
↓ 填 TCP 头
交给 IP 层
这就是图中“本次只拷贝头,不拷贝数据”的含义。它的目的很实际:原始数据还要留在 TCP 队列里,直到对方 ACK 确认。
TCP 头里最重要的字段包括:
| 字段 | 作用 |
|---|---|
| 源端口、目的端口 | 找到两端应用 |
序列号 seq |
标记这段数据在 TCP 字节流里的位置 |
确认号 ack_seq |
告诉对方我已经收到哪里了 |
| flags | SYN、ACK、PSH、FIN、RST 等 |
| 窗口 | 告诉对方我还能接收多少 |
| 校验和 | 检查传输中是否出错 |
四、IP 层:查路由、过 netfilter、处理 MTU
4.1 ip_queue_xmit():选择从哪里出去
IP 层的任务不是可靠传输,它主要回答三个问题:
- 目标 IP 应该走哪条路?
- 应该从哪块网卡出去?
- 下一跳是谁?
这张图展示了 IP 输出路径和 netfilter 钩子:
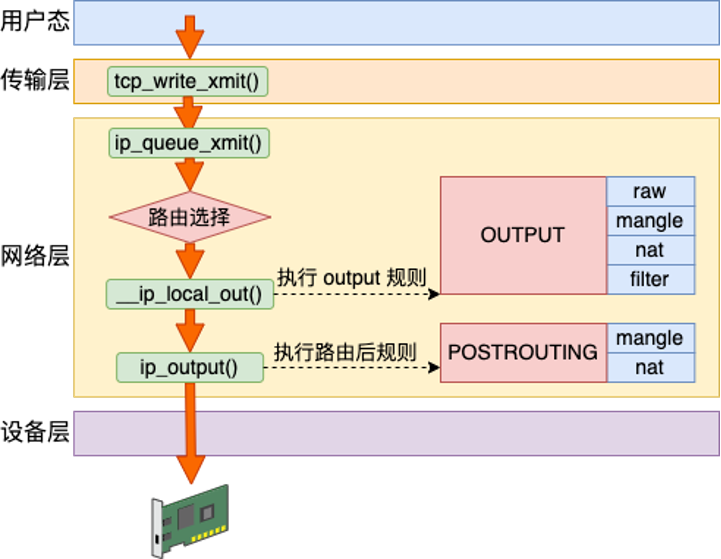
常见路径是:
ip_queue_xmit()
↓
路由查找
↓
__ip_local_out()
↓
netfilter LOCAL_OUT
↓
ip_output()
↓
netfilter POST_ROUTING
↓
ip_finish_output()
这里要注意 netfilter:
OUTPUT链处理本机产生的包;POSTROUTING链在路由决策之后处理包;- SNAT、MASQUERADE 等常发生在
POSTROUTING; - 所以你在本机发包时,iptables/nftables 也可能改包或丢包。
4.2 路由:决定出口网卡和下一跳
这张图对应“路由选择哪个设备把包发出去”:
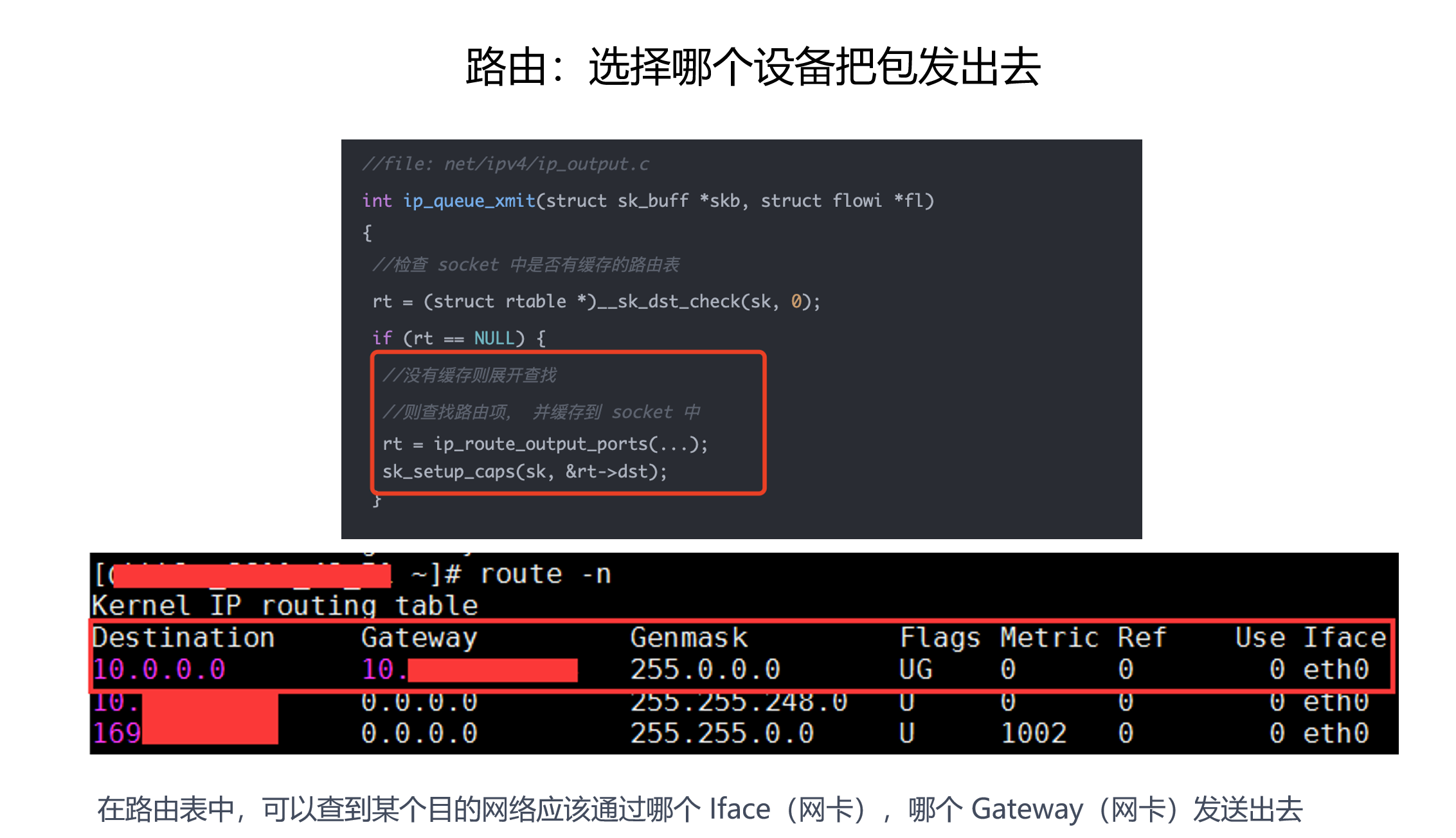
路由表里最常见的几个字段:
| 字段 | 含义 |
|---|---|
| Destination | 目标网段 |
| Gateway | 下一跳网关 |
| Genmask | 子网掩码 |
| Iface | 从哪块网卡出去 |
| Metric | 多条路由都匹配时的优先级参考 |
举个例子:
ip route get 8.8.8.8
你可能看到类似:
8.8.8.8 via 192.168.1.1 dev eth0 src 192.168.1.100
这句话翻译成人话是:
- 目标是
8.8.8.8; - 下一跳网关是
192.168.1.1; - 从
eth0出去; - 本机源 IP 用
192.168.1.100。
4.3 MTU、MSS、IP 分片和 GSO
这张图展示的是 IP 层发现包超过 MTU 时的处理:
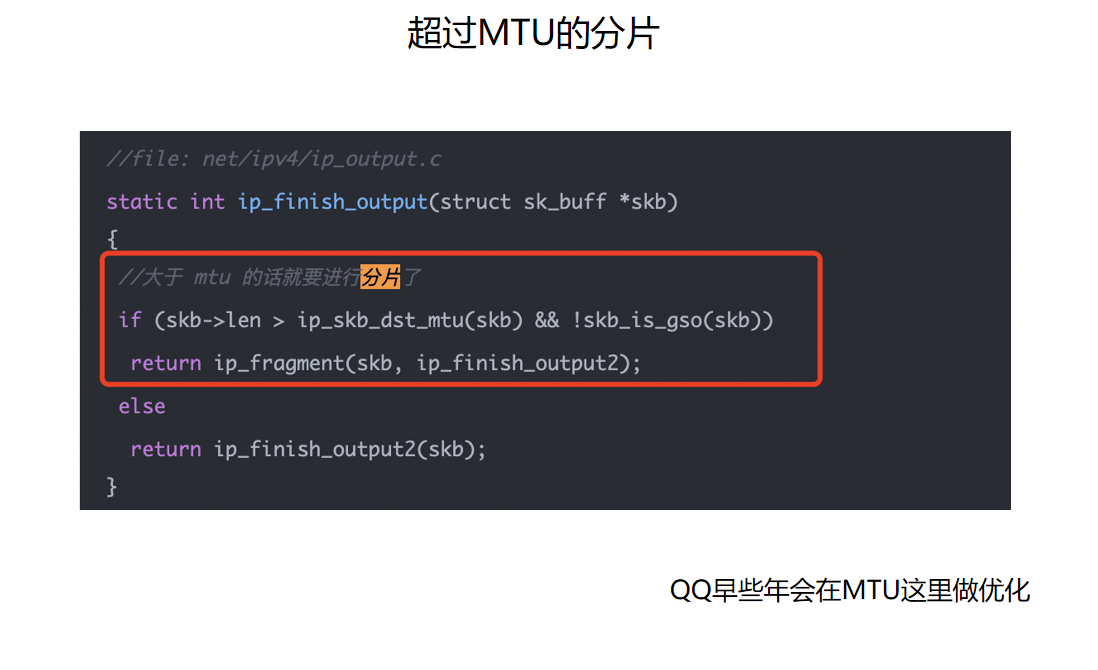
几个概念要分清:
| 概念 | 所在层 | 含义 |
|---|---|---|
| MTU | 链路层/IP 输出相关 | 一次链路帧能承载的最大 IP 包大小,以太网常见是 1500 |
| MSS | TCP 层 | 单个 TCP 段能承载的最大应用数据量 |
| IP 分片 | IP 层 | IP 包太大时拆成多个 IP 分片 |
| GSO/TSO | 内核/网卡 offload | 让大 skb 尽量晚分段,减少协议栈重复工作 |
初学时可以先这样记:
MTU = 整个 IP 包上限
MSS = TCP 数据负载上限
IPv4/TCP 常见情况:
MTU 1500
IP 头 20
TCP 头 20
MSS 约 1460
TCP 会尽量用 MSS 避免 IP 分片,因为 IP 分片会带来额外开销和丢包放大问题。现代发送路径又会用 GSO/TSO 做优化:在协议栈里少走几次,最后由软件或网卡硬件再切成适合链路发送的小段。
五、邻居子系统:IP 地址怎么变成 MAC 地址
5.1 为什么有了 IP 还不够
IP 层查完路由后,只知道:
我要从 eth0 发出去,下一跳 IP 是 192.168.1.1
但以太网真正发帧时需要的是:
目的 MAC 地址是多少?
所以还需要邻居子系统。IPv4 常用 ARP,IPv6 使用 Neighbor Discovery。
5.2 ARP 的工作流程
1. 先查邻居缓存
ip neigh show
2. 如果命中
直接拿到下一跳 MAC,填以太网头
3. 如果未命中
发 ARP 广播:
“谁是 192.168.1.1?请告诉 192.168.1.100”
4. 下一跳回复
“我是 192.168.1.1,我的 MAC 是 aa:bb:cc:dd:ee:ff”
5. 本机更新邻居缓存
后续一段时间不用重复 ARP
查看邻居缓存:
ip neigh show
可能看到:
192.168.1.1 dev eth0 lladdr aa:bb:cc:dd:ee:ff REACHABLE
5.3 邻居缓存状态
| 状态 | 含义 |
|---|---|
INCOMPLETE |
正在解析,还没拿到 MAC |
REACHABLE |
最近确认可达,可以直接用 |
STALE |
可能还能用,但已经有点旧 |
DELAY |
先等一等,看是否能确认 |
PROBE |
正在主动探测 |
FAILED |
解析失败 |
如果 ARP 解析失败,包就没法填二层目的 MAC,自然也发不出去。排查“同网段 ping 不通”时,ip neigh show 往往很有用。
六、网络设备层:qdisc、发送队列和驱动
6.1 dev_queue_xmit():进入网络设备层
这张图对应邻居子系统之后进入 dev_queue_xmit():

到了这里,skb 已经基本具备要发出去的样子:
以太网头 + IP 头 + TCP 头 + 应用数据
dev_queue_xmit() 要做的事情包括:
- 选择发送队列;
- 根据 qdisc 排队或直接发送;
- 处理设备是否可发送;
- 调用驱动提供的发送函数。
6.2 qdisc:不是所有包都直接进驱动
qdisc 是 Queueing Discipline,中文常叫“队列规则”或“排队规则”。tc(8) 手册里的核心意思是:内核要把包发到某个网络接口时,会先把包放到该接口配置的 qdisc 里,然后再尽可能从 qdisc 取包交给驱动。
你可以把 qdisc 理解为网卡前面的调度室:
| qdisc 能做什么 | 例子 |
|---|---|
| 排队 | 网卡忙时先暂存 |
| 调度 | 哪些流优先发 |
| 整形 | 限制发送速率 |
| 丢弃 | 队列满或主动 AQM 丢包 |
| 分类 | 根据规则把包分到不同队列 |
查看 qdisc:
tc qdisc show dev eth0
常见 qdisc:
| qdisc | 直观理解 |
|---|---|
pfifo_fast |
老式优先级 FIFO |
fq |
按流公平排队,支持 pacing |
fq_codel |
公平排队 + 控制队列延迟 |
mq |
多硬件发送队列的根 qdisc |
mqprio |
多队列优先级映射 |
htb |
常见限速和带宽分配 |
6.3 NET_TX_SOFTIRQ:什么时候会出现
这张图讲的是 qdisc 发送队列和 NET_TX_SOFTIRQ:
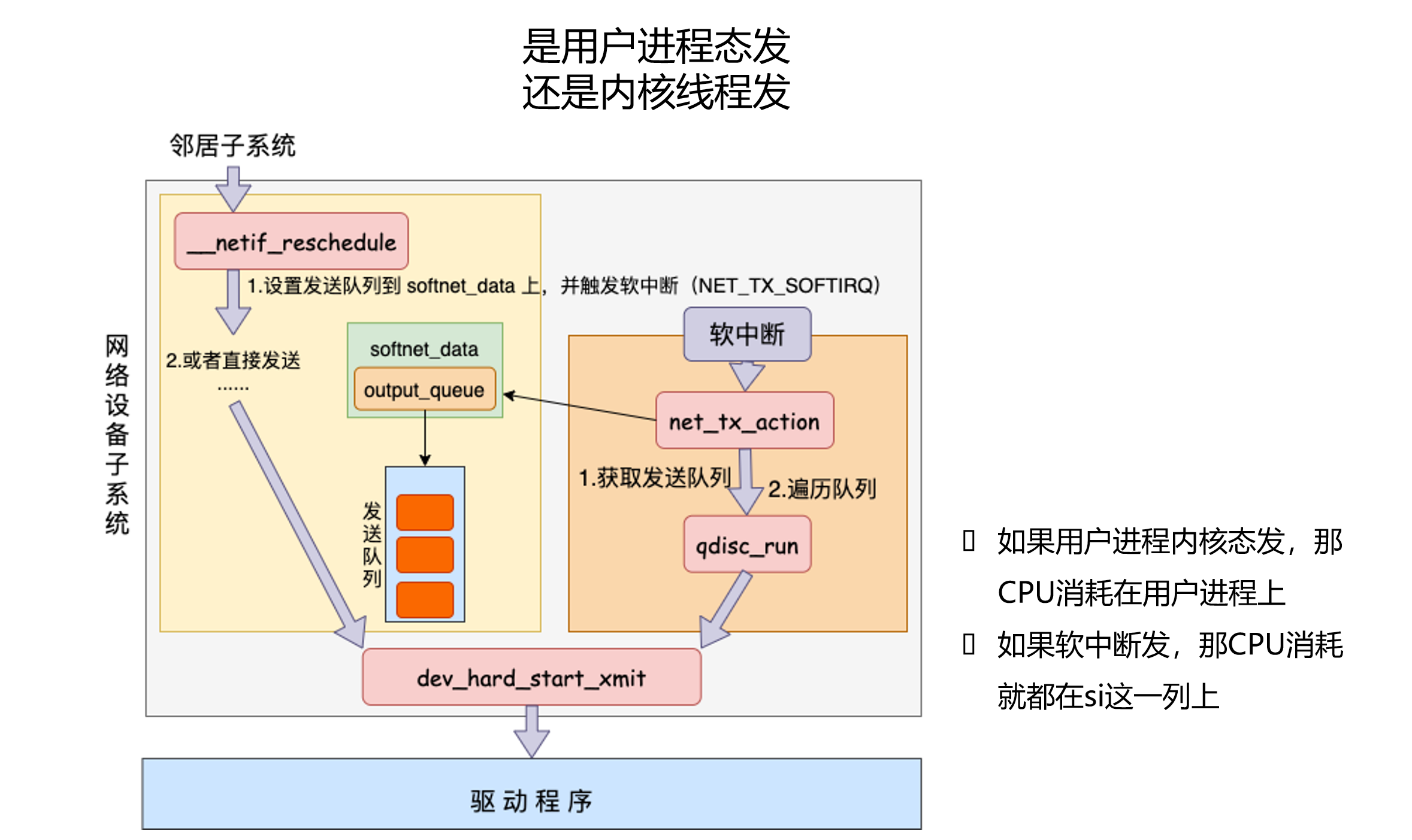
发送路径有两种常见执行方式:
方式 1:当前进程内核态直接推进
send() 进入内核
↓
协议栈处理
↓
dev_queue_xmit()
↓
驱动 ndo_start_xmit()
方式 2:队列稍后由软中断继续推进
包进入 output_queue
↓
触发 NET_TX_SOFTIRQ
↓
net_tx_action()
↓
qdisc_run()
↓
驱动 ndo_start_xmit()
所以,NET_TX_SOFTIRQ 不是“每发一个包必然触发一次”。很多发送工作已经在发起 send() 的进程上下文里完成了。只有当 qdisc、设备队列、调度等条件导致需要异步继续处理时,才会更多看到 TX softirq。
6.4 驱动:把 skb 交给网卡
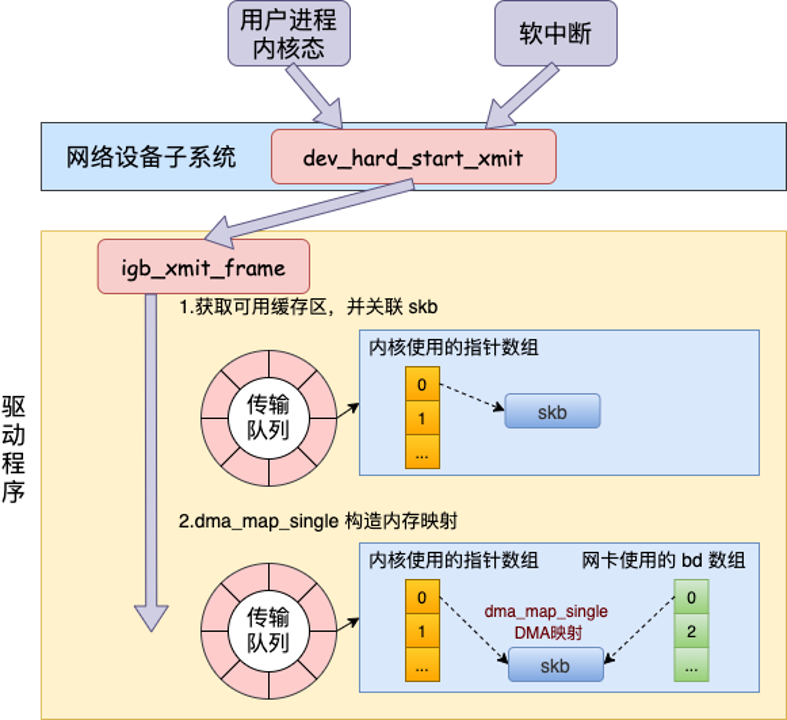
这张图对应驱动程序中的发送函数:

网络设备层最终会调用驱动注册的 ndo_start_xmit()。不同网卡驱动函数名不同,比如图里 Intel igb 驱动可能走到 igb_xmit_frame()。
驱动大致做这些事:
-
选择 TX Ring 的空闲描述符
- TX Ring 是网卡和驱动共享的一圈发送描述符;
- 描述符记录“数据在哪里、长度多少、需要哪些 offload”。
-
DMA 映射
- 网卡不能随便读 CPU 虚拟地址;
- 驱动要把 skb 数据映射成设备可访问的 DMA 地址。
-
填写描述符
- 把 DMA 地址、长度、校验和 offload、TSO 信息等写入描述符。
-
通知网卡
- 驱动更新 tail 指针或写 doorbell;
- 网卡知道 TX Ring 里有新数据可发。
-
网卡真正发送
- 网卡通过 DMA 读取内存;
- 如果启用 TSO/checksum offload,网卡还会做分段和校验和;
- 最后把比特流发到物理链路。
这张图把 DMA 映射和 TX Ring 关系画得更清楚:
七、发送完成:为什么还会有中断和软中断
7.1 “发出去”之后还要清理
网卡把数据发出后,驱动还要知道哪些 TX 描述符已经完成,然后:
- 解除 DMA 映射;
- 释放或减少 skb 引用;
- 回收 TX Ring 描述符;
- 如果之前因为队列满而停了队列,可能唤醒发送队列;
- 更新统计信息。
这张图展示了发送完成后清理 TX Ring 的过程:
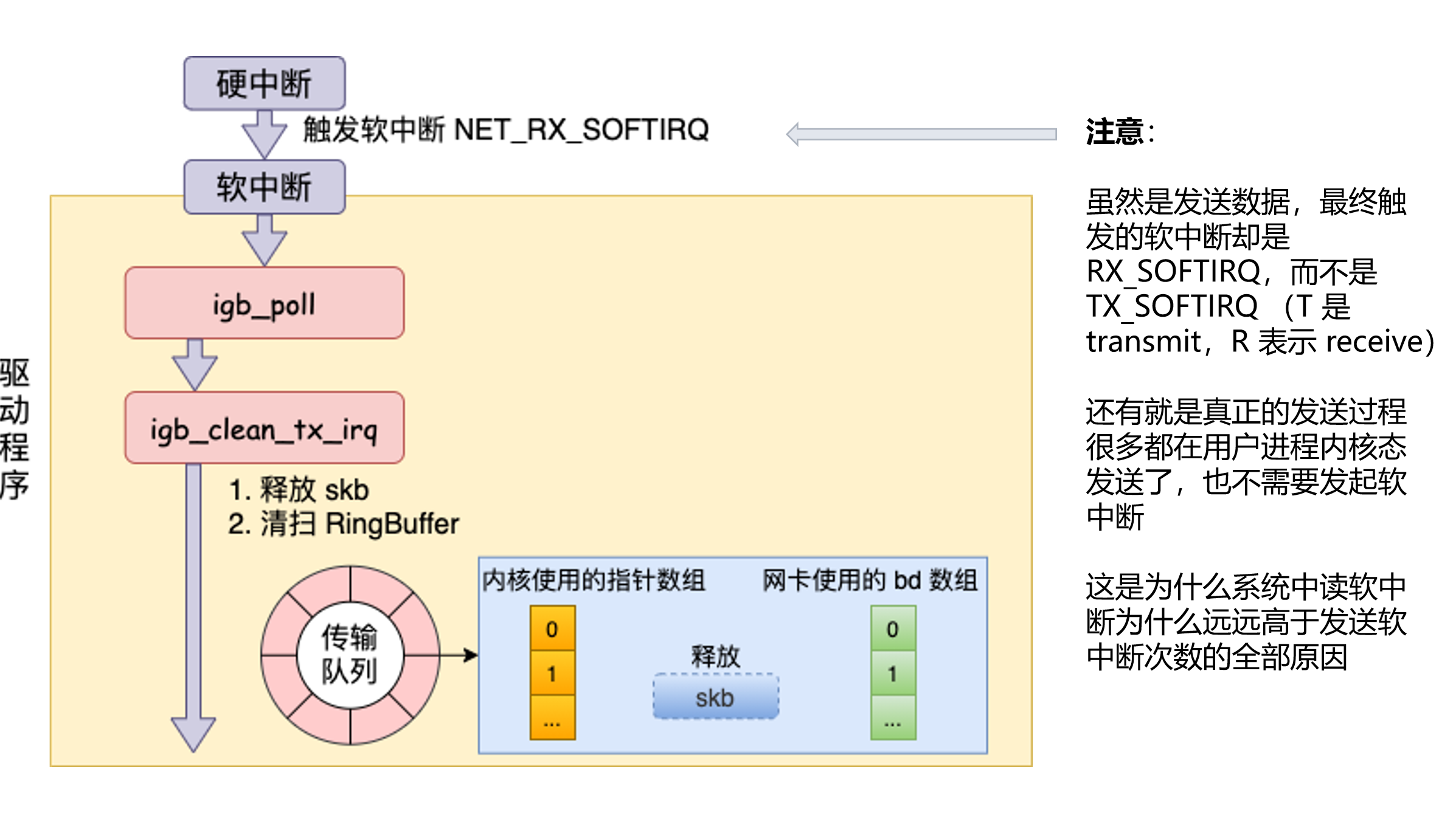
7.2 为什么图里是 NET_RX_SOFTIRQ
原文里说“发送数据最终触发 RX_SOFTIRQ,因为要处理 ACK”,这个说法需要纠正。
更准确的说法是:
-
对端回来的 ACK,当然属于接收路径
- ACK 是另一个从网卡进来的包;
- 它会走 RX 中断、NAPI、协议栈接收路径;
- 这和“本机刚才那个 skb 的发送完成清理”不是同一件事。
-
很多网卡驱动把 TX 完成清理放在 NAPI poll 里做
- NAPI 是 Linux 网络栈处理网卡事件的机制;
- 官方文档也说明,驱动的 poll 方法通常会释放已发送的 Tx 包,并处理新收到的 Rx 包;
- NAPI 通常运行在软件中断上下文,传统上主要通过
NET_RX_SOFTIRQ这一套 poll 机制调度。
-
NET_TX_SOFTIRQ主要不是用来表示“硬件发送完成”- 它更多和 qdisc 输出队列、异步继续发送有关;
- 所以你会看到:发送路径的主体在进程内核态,qdisc 可能用 TX softirq,驱动 TX 完成清理又可能在 NAPI/RX softirq 中发生。
一句话总结:
发包主体:常在 send() 进程的内核态推进
qdisc 异步发送:可能走 NET_TX_SOFTIRQ
网卡 TX 完成清理:很多驱动在 NAPI poll 中做,常表现为 NET_RX_SOFTIRQ
对端 ACK:这是独立的接收包,走接收路径
这样理解就不会把“ACK 接收”和“TX 完成清理”混成一件事。
八、性能优化:哪些地方真的会省 CPU
8.1 优化全景
网络发送路径的 CPU 开销主要来自:
- 系统调用次数;
- 用户态到内核态的数据拷贝;
- TCP/IP 协议栈处理;
- 分段和校验和计算;
- qdisc 排队和锁竞争;
- 驱动描述符处理;
- 中断和软中断处理;
- 缓存失效和跨 CPU 迁移。
优化也要按层次看:
| 层次 | 优化方向 | 常见手段 |
|---|---|---|
| 应用层 | 少调用、少小包 | 批量写、writev()、连接复用、TCP_NODELAY 或 TCP_CORK |
| 拷贝路径 | 少搬数据 | sendfile()、splice()、MSG_ZEROCOPY |
| TCP/IP | 减少重复协议栈工作 | GSO、TSO、checksum offload |
| qdisc | 控制排队和延迟 | fq、fq_codel、合理限速 |
| 多队列 | 减少锁竞争 | RSS、RPS、XPS、IRQ affinity |
| 驱动/网卡 | 批处理 | Ring Buffer、中断合并、offload |
8.2 零拷贝:sendfile()
这张图展示了传统文件发送和零拷贝发送的差异:
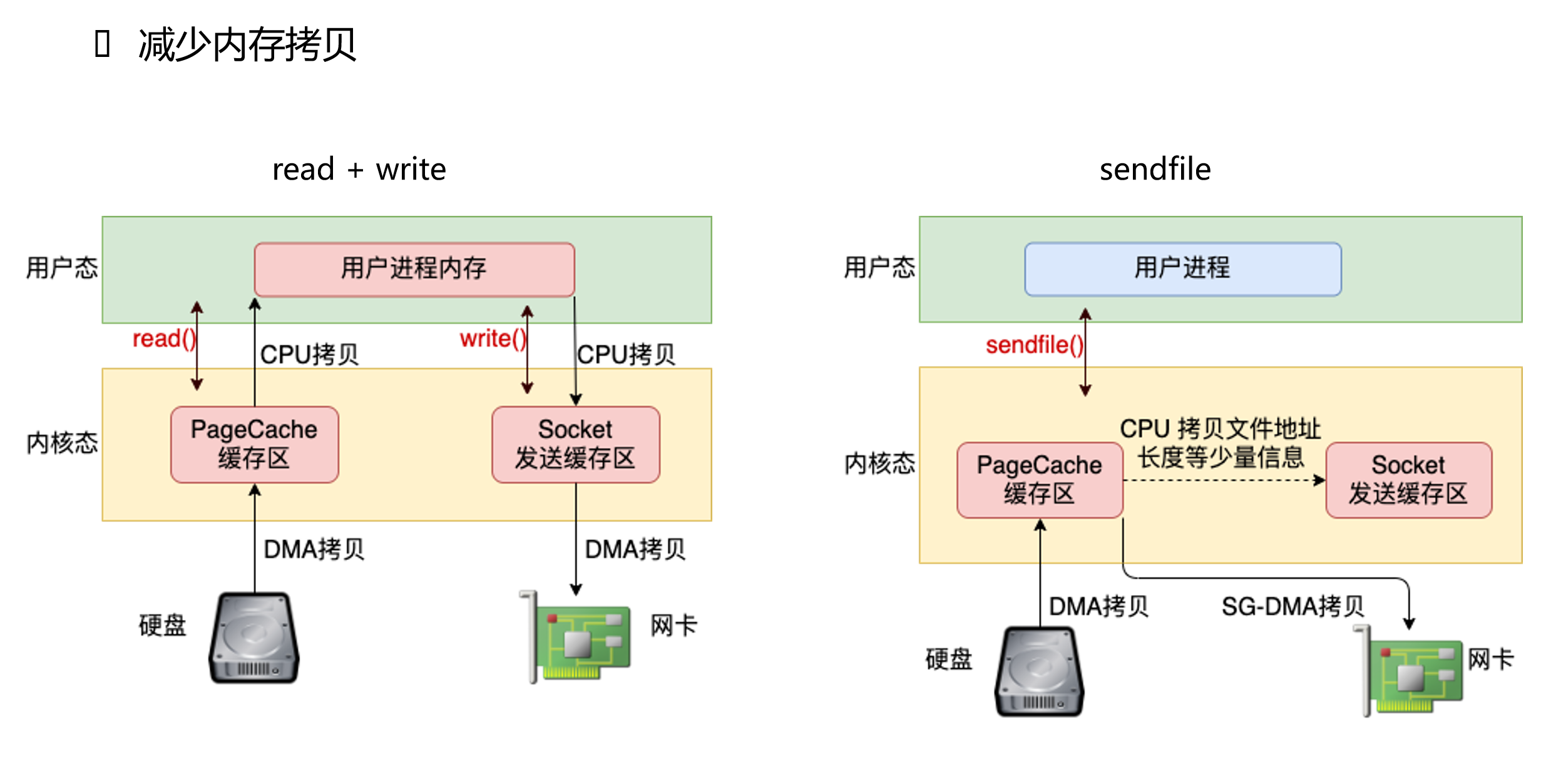
传统文件发送常见路径:
磁盘 → 内核页缓存 → 用户缓冲区 → socket 发送缓冲区 → 网卡
sendfile() 的典型优化是:
磁盘 → 内核页缓存 → socket / 网卡
它省掉了“文件数据先拷贝到用户态,再从用户态拷回内核态”的过程。Nginx 静态文件、Kafka 日志段传输等场景都非常依赖这类优化。
注意:零拷贝不是“完全没有任何拷贝”,而是减少 CPU 参与的数据搬运,具体效果还受页缓存、网卡 scatter-gather、DMA、TLS、压缩等因素影响。
8.3 GSO/TSO:少走几遍协议栈
这张图展示了 GSO/TSO 的思想:

没有 offload 时:
64KB 数据
↓
内核拆成很多 MSS 大小的小 skb
↓
每个小包都走一遍较完整的发送处理
有 GSO/TSO 时:
64KB 大 skb
↓
协议栈尽量按一个大 skb 处理
↓
靠近驱动或网卡时再分成 MTU 大小的小包
区别:
| 名称 | 谁来做 | 作用 |
|---|---|---|
| GSO | 内核软件 | 设备不支持硬件分段时,内核在较晚位置分段 |
| TSO | 网卡硬件 | 网卡按 MSS 把大 TCP skb 切成多个帧 |
| checksum offload | 网卡硬件 | 网卡计算 TCP/UDP 校验和 |
| GRO | 接收方向内核合并 | 把接收的小包合并后上送,减少协议栈次数 |
| LRO | 接收方向硬件/驱动合并 | 可能影响转发语义,路由器/网关上要谨慎 |
查看 offload:
ethtool -k eth0
修改 offload:
ethtool -K eth0 tso on gso on gro on
8.4 多队列、RSS、XPS
这张图展示的是多队列思想:
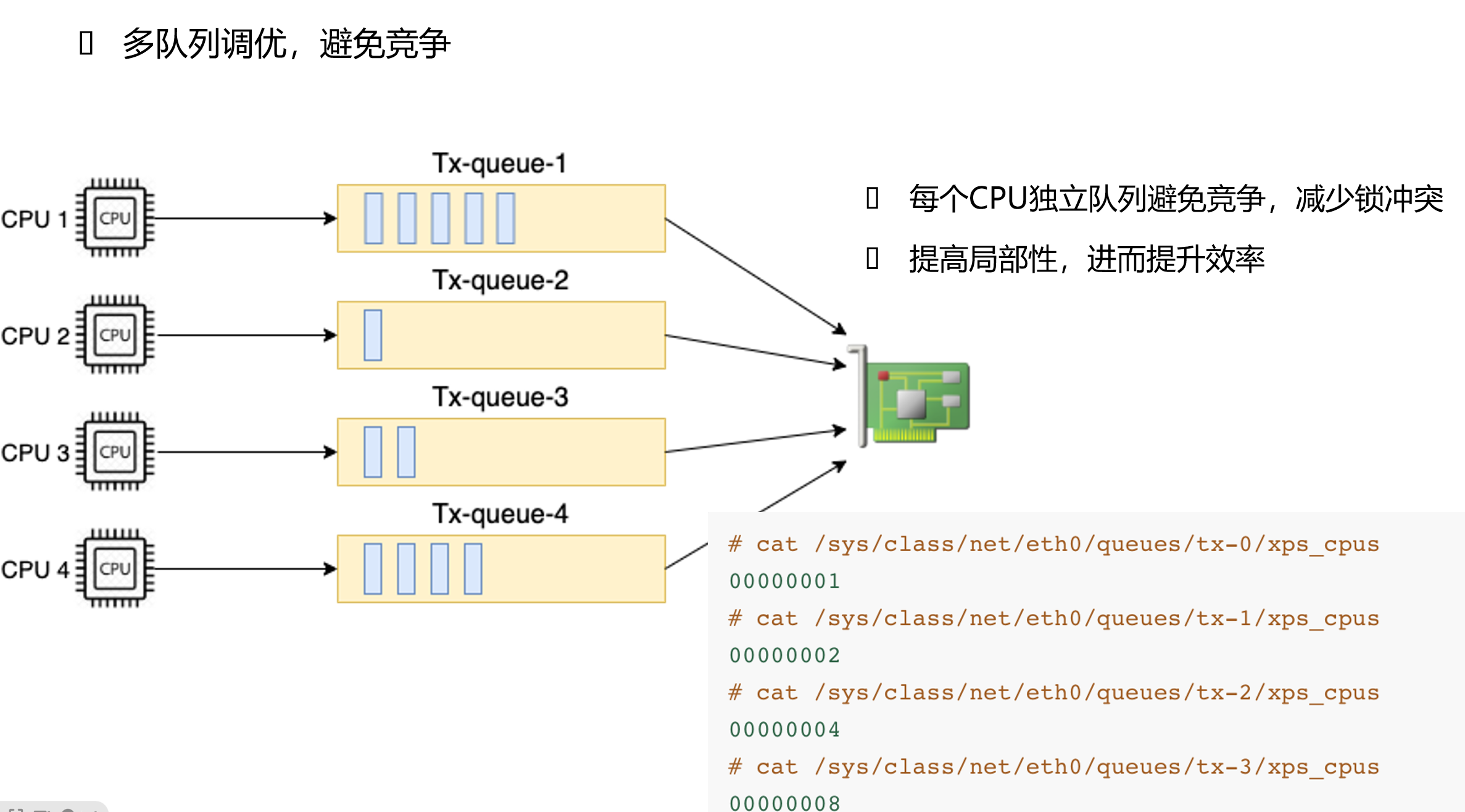
现代网卡通常有多个 RX/TX 队列。多队列的目的不是“看起来高级”,而是解决并发瓶颈:
- 多个 CPU 不要都抢同一个发送队列锁;
- 某条流尽量固定在同一个队列,避免乱序;
- 中断和缓存尽量保持 CPU 局部性;
- 高吞吐时把负载摊开。
几个概念:
| 名称 | 方向 | 作用 |
|---|---|---|
| RSS | 接收 | 网卡根据五元组 hash 把包分到不同 RX 队列 |
| RPS | 接收 | 内核软件把接收处理分发到不同 CPU |
| RFS | 接收 | 尽量把包送到应用所在 CPU,提高缓存命中 |
| XPS | 发送 | 选择哪个 TX 队列发送,减少锁竞争和缓存失效 |
| IRQ affinity | 中断 | 把队列中断绑定到合适 CPU |
查看队列:
ls /sys/class/net/eth0/queues/
查看中断分布:
cat /proc/interrupts | grep -E 'eth0|ens|enp'
查看 XPS:
cat /sys/class/net/eth0/queues/tx-0/xps_cpus
九、用一条主线把所有细节串起来
9.1 一次 TCP 发包的完整故事
假设你的程序执行:
send(fd, "hello", 5, 0);
完整过程可以这样读:
1. 应用进入内核
send()
↓
系统调用层找到 fd 对应的 socket
2. 进入 TCP
tcp_sendmsg()
↓
检查连接状态、发送缓冲区
↓
申请或复用 skb
↓
把 "hello" 从用户态拷贝到内核态
↓
挂到 TCP 发送队列
3. TCP 判断是否推进发送
tcp_push()
↓
看 Nagle、TCP_NODELAY、TCP_CORK、MSS、队列位置等
4. TCP 真正组织输出
tcp_write_xmit()
↓
看 rwnd 和 cwnd
↓
选择可发送的 skb
↓
tcp_transmit_skb()
↓
克隆 skb、填写 TCP 头
5. 进入 IP
ip_queue_xmit()
↓
查路由,确定 eth0 和下一跳
↓
经过 OUTPUT / POSTROUTING
↓
检查 MTU,必要时分片或走 GSO
6. 进入邻居子系统
查邻居缓存
↓
如果没有 MAC,先 ARP
↓
有 MAC 后填以太网头
7. 进入网络设备层
dev_queue_xmit()
↓
选择 TX queue
↓
经过 qdisc
↓
dev_hard_start_xmit()
8. 进入驱动
ndo_start_xmit()
↓
DMA 映射
↓
填 TX Ring 描述符
↓
通知网卡
9. 网卡发送
DMA 读取内存
↓
可能执行 TSO/checksum offload
↓
发到网线或光纤
10. 发送完成清理
网卡产生完成事件
↓
驱动在 NAPI poll 中清理 TX 描述符
↓
释放 skb
↓
必要时唤醒发送队列
9.2 四个最重要的理解点
第一,send() 成功不等于对方收到。
它主要表示数据被内核接收。TCP 负责后续可靠传输、重传、ACK 处理。
第二,TCP 是字节流,不是消息队列。
你 send() 两次,对端不一定 recv() 两次。TCP 只保证字节顺序,不保留应用消息边界。
第三,发送路径的主体经常在进程内核态完成。
所以看 CPU 时,网络发送成本可能体现在业务进程的 sys 时间上,而不是全部体现在 ksoftirqd。
第四,软中断要分清场景。
NET_TX_SOFTIRQ:更多和 qdisc 异步输出有关;NET_RX_SOFTIRQ/NAPI:接收处理,也常承载驱动 TX 完成清理;- ACK:是对端返回的新包,属于接收路径,不是本机发送完成本身。
十、常用观测命令
10.1 看路由
ip route
ip route get 8.8.8.8
10.2 看邻居缓存
ip neigh show
10.3 看 qdisc
tc qdisc show dev eth0
tc -s qdisc show dev eth0
10.4 看网卡 offload
ethtool -k eth0
10.5 看 Ring Buffer
ethtool -g eth0
10.6 看网卡统计
ethtool -S eth0
ip -s link show dev eth0
10.7 看软中断
cat /proc/softirqs | grep NET
10.8 看中断分布
cat /proc/interrupts | grep -E 'eth0|ens|enp'
10.9 看 TCP 统计
ss -s
netstat -s | grep -i tcp
10.10 抓包验证
tcpdump -i eth0 -nn host 目标IP
抓包时要注意:如果开启 TSO/GSO,你在发送端抓到的包可能看起来“超过 MTU”,这是因为抓包位置在软件分段之前。到网线上真正发出的帧仍然会符合 MTU。
十一、参考资料
官方和权威资料
- Linux Kernel Documentation: struct sk_buff
- Linux Kernel Documentation: Segmentation Offloads
- Linux Kernel Documentation: Scaling in the Linux Networking Stack
- Linux Kernel Documentation: NAPI
- Linux Foundation Wiki: Neighboring Subsystem
- man7: send(2)
- man7: tcp(7)
- man7: tc(8)
延伸阅读
- 25 张图,一万字,拆解 Linux 网络包发送过程
- 深入理解 Linux 网络:内核是如何发送网络包的
- 《Understanding Linux Network Internals》
- 《深入理解 Linux 网络》