
网络收发包应用之抓包(含实验)
这节课的核心问题不是 tcpdump 命令怎么用,而是:一个运行在用户态的程序,为什么能看到主要发生在内核态的网络包流转过程?
读完这篇笔记,应该能回答 3 个问题:
- 用户态
tcpdump如何抓到内核网络包? - 被
iptables/netfilter丢弃的包,tcpdump到底能不能抓到? - 为什么用
socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL))就能写出一个最小抓包程序?
先给结论:在 Linux 上,tcpdump 底层依赖 libpcap,libpcap 会创建 AF_PACKET 类型的 packet socket。这个 socket 不是普通 TCP/UDP socket,而是工作在链路层附近。内核创建它时,会把一个回调函数 packet_rcv 注册到网络设备层的抓包链表 ptype_all 上。之后无论是收包路径还是发包路径,只要包走到网络设备层,内核都会遍历 ptype_all,把包递交给这些“旁路观察者”,tcpdump 就是在这里拿到包的。
flowchart LR
A["tcpdump / libpcap"] --> B["socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL))"]
B --> C["packet_create"]
C --> D["po->prot_hook.func = packet_rcv"]
D --> E["dev_add_pack"]
E --> F["ptype_all"]
R1["收包: __netif_receive_skb_core"] --> R2["遍历 ptype_all"]
R2 --> R3["deliver_skb"]
R3 --> R4["packet_rcv"]
R4 --> R5["sk_receive_queue"]
R5 --> R6["用户态 recvfrom/read"]
T1["发包: xmit_one / dev_hard_start_xmit"] --> T2["dev_queue_xmit_nit"]
T2 --> T3["遍历 ptype_all"]
T3 --> T4["packet_rcv"]
一、tcpdump 启动过程
首次启动 tcpdump 时,可以用 strace 观察它创建了什么类型的 socket。
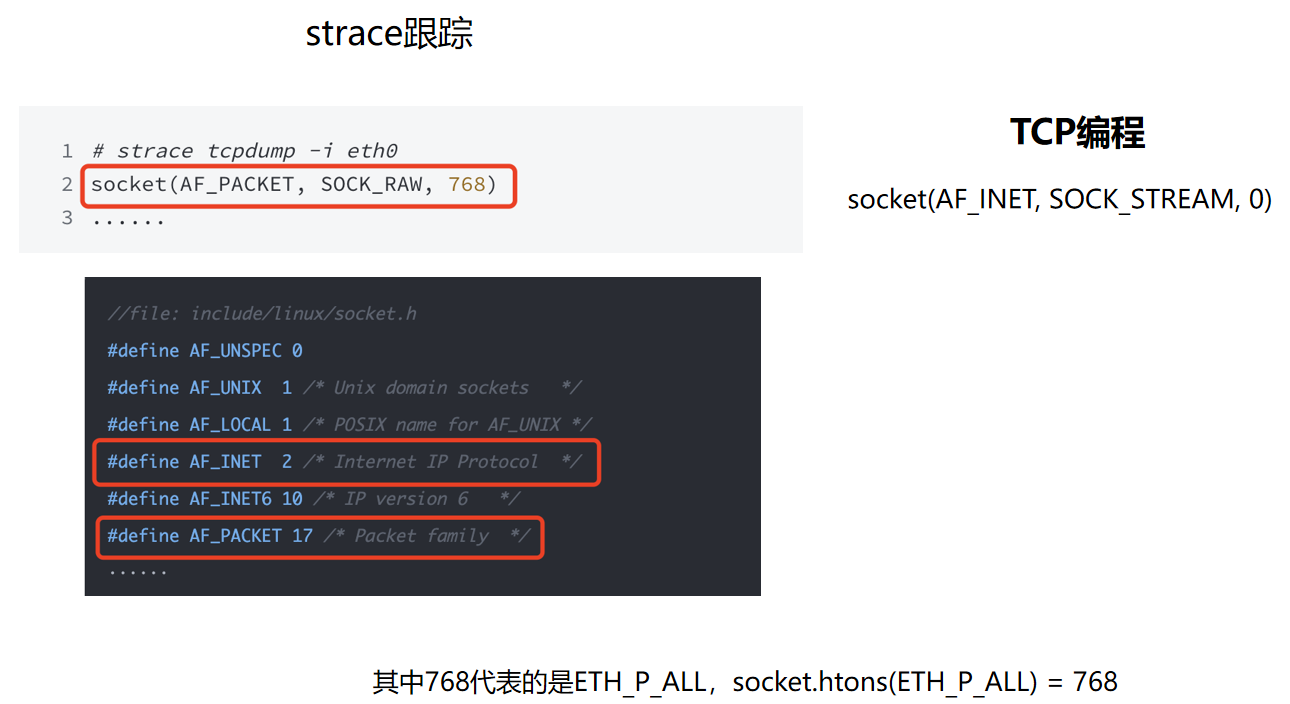
图里最关键的一行是:
socket(AF_PACKET, SOCK_RAW, 768)
这和普通 TCP 编程很不一样。普通 TCP 客户端或服务端一般创建的是:
socket(AF_INET, SOCK_STREAM, 0)
两者的差别在于工作层级:
AF_INET + SOCK_STREAM:创建 IPv4 TCP socket,关注传输层字节流,应用只看到 TCP 已经处理过的数据。AF_PACKET + SOCK_RAW:创建 packet socket,工作在设备层/链路层附近,能看到包含二层头部的原始帧。
第三个参数 768 也很关键。ETH_P_ALL 的值是 0x0003,表示接收所有以太网协议类型。socket 参数要求协议号使用网络字节序,所以代码里通常写 htons(ETH_P_ALL)。在小端机器上,htons(0x0003) 会变成 0x0300,十进制就是 768。所以 strace 里看到的 768,其实就是 htons(ETH_P_ALL)。
换句话说,tcpdump 启动时是在告诉内核:我要创建一个链路层原始 socket,并且我对所有协议的包都感兴趣。
接下来再看内核如何根据协议族找到具体的创建函数。
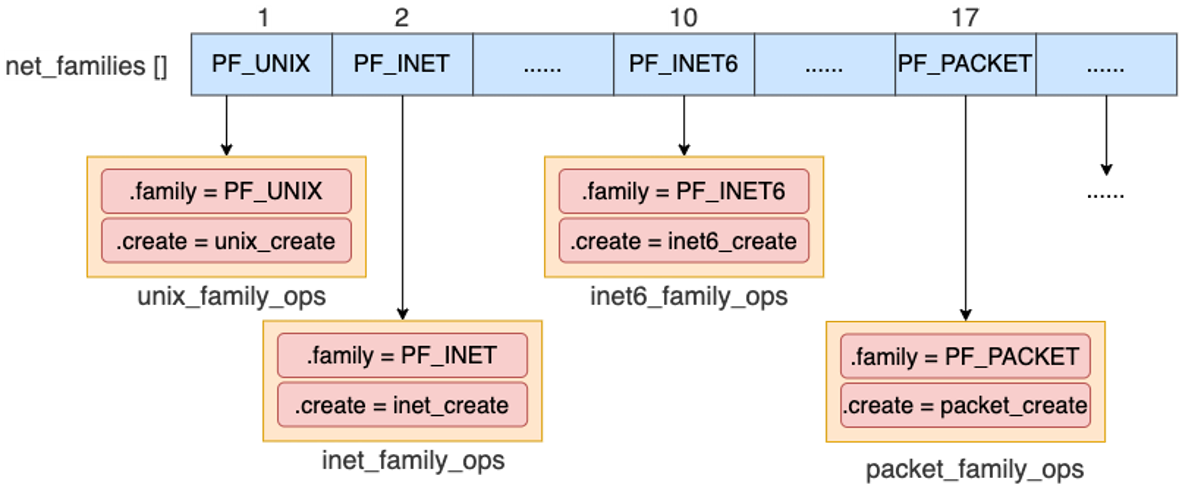
Linux 内核里有一个 net_families 数组,不同协议族在数组里有不同位置。常见的包括:
PF_INET/AF_INET:IPv4 协议族,对应普通 TCP/UDP socket,创建函数是inet_create。PF_INET6/AF_INET6:IPv6 协议族,创建函数是inet6_create。PF_PACKET/AF_PACKET:packet socket 协议族,创建函数是packet_create。
AF_* 和 PF_* 在很多场景下值相同,经常混用。更准确地说,AF 偏“地址族”,PF 偏“协议族”;实际 Linux socket 编程里经常直接等价使用。
因此,socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL)) 会走到 packet_create。
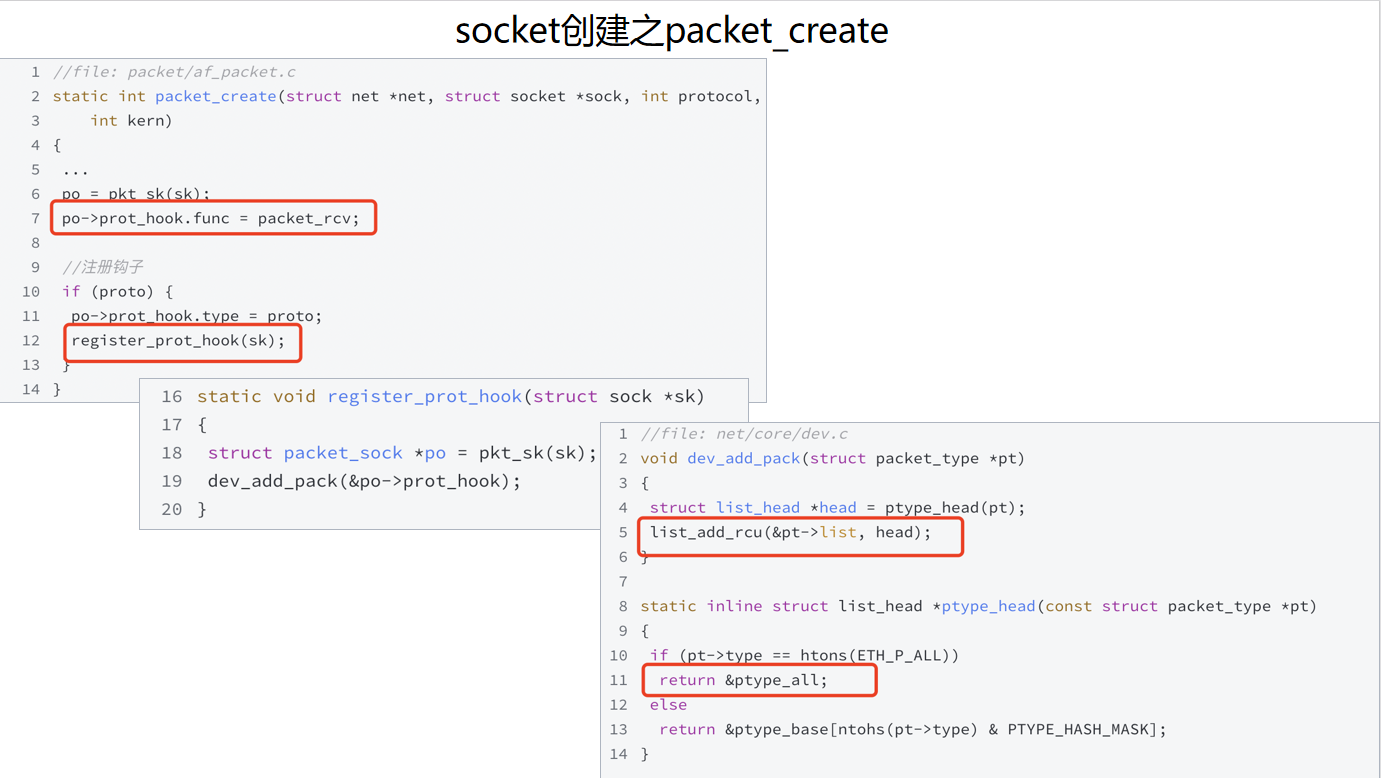
这张图展示的是 packet_create 的关键动作:
po = pkt_sk(sk);
po->prot_hook.func = packet_rcv;
if (proto) {
po->prot_hook.type = proto;
register_prot_hook(sk);
}
这里的 po 是 packet_sock,可以理解为 packet socket 在内核里的私有对象。po->prot_hook 是一个 packet_type,它会被挂到网络设备层的协议链表上。最关键的是:
po->prot_hook.func = packet_rcv:以后内核抓到匹配的包,就调用packet_rcv。po->prot_hook.type = proto:这里的proto是htons(ETH_P_ALL)。register_prot_hook -> dev_add_pack:把这个抓包钩子注册到内核的协议分发链表里。
dev_add_pack 最终会根据协议类型选择注册位置:
if (pt->type == htons(ETH_P_ALL))
return &ptype_all;
else
return &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
所以 tcpdump 监听所有协议时,会被挂到 ptype_all。
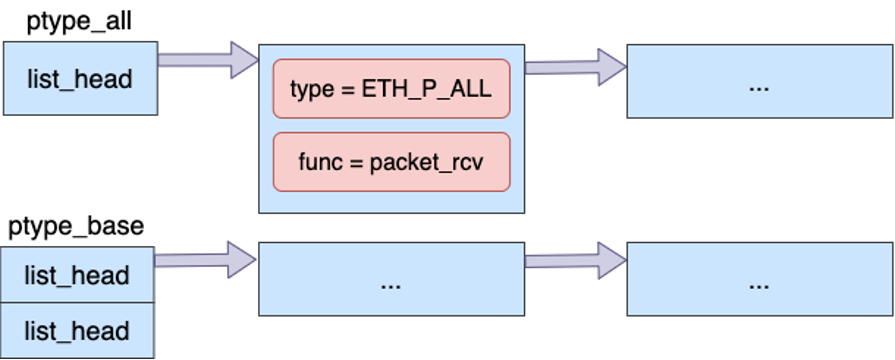
这张图可以理解为:ptype_all 是网络设备层上的一条观察者链表。tcpdump 创建 packet socket 后,就往这条链表里插入了一个节点,这个节点的协议类型是 ETH_P_ALL,回调函数是 packet_rcv。
之后只要网络包走到网络设备层的抓包点,内核就会遍历这条链表,把包递交给 packet_rcv。这就是用户态 tcpdump 能看到内核网络包的入口。
二、网络包接收过程中的抓包
收包路径可以先按这个粗粒度顺序理解:
网卡收到包
-> DMA 写入接收 RingBuffer
-> 网卡触发硬中断
-> 驱动通过 NAPI poll 收包
-> 触发/执行 NET_RX_SOFTIRQ
-> 进入网络设备层
-> 进入 IP/TCP/UDP 等协议栈
-> 唤醒用户进程读取 socket 接收队列
tcpdump 的抓包点在“网络设备层”,而 iptables/netfilter 的常见过滤点在 IP 协议层。这个先后顺序决定了收包时一个非常重要的现象:即使后面被 iptables 的 INPUT 或 PREROUTING 规则丢掉,tcpdump 通常仍然已经看到了这个包。
总体接收如下图。
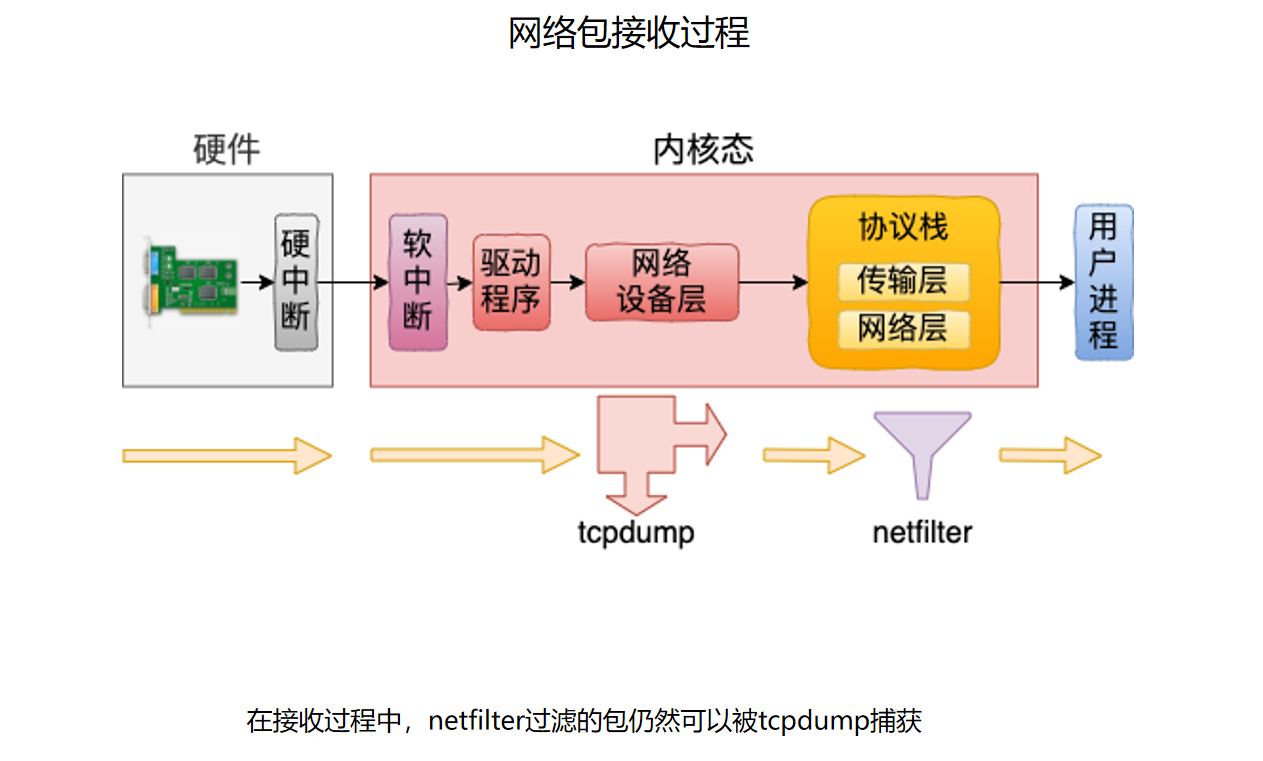
图中的关键位置是:包从驱动进入网络设备层后,会先到 tcpdump 能观察的位置;再往后才进入协议栈中的 netfilter 钩子。换句话说,收包时 tcpdump 比 IP 层过滤更早看到包。
内核源码里对应的位置在 net/core/dev.c 的 __netif_receive_skb_core。
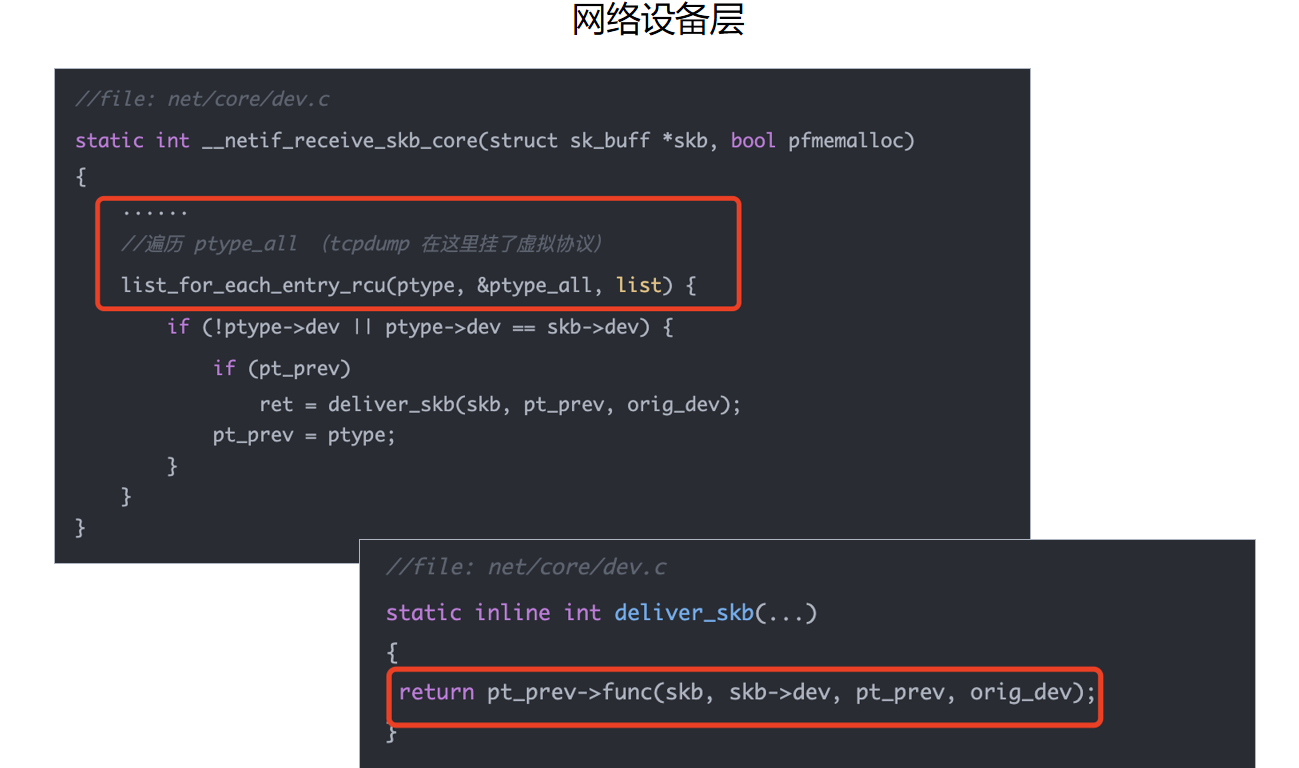
这段代码的意思是:在网络设备层接收包时,内核会遍历 ptype_all:
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
ptype_all 里挂着所有“想看所有包”的 packet socket。tcpdump 之前通过 dev_add_pack 注册进去的 packet_type,就在这里被遍历到。
deliver_skb 本质上就是调用这个 packet_type 的回调函数:
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
对于 tcpdump 的 packet socket 来说,func 就是启动阶段设置好的 packet_rcv。
这里容易被“钩子函数、链表、队列”这些词绕晕,可以拆开看:
ptype_all不是存放数据包的队列,而是一张“旁路观察者名单”。名单里的每一项都是一个packet_type,表示“我想看哪些包,以及看到包后调用哪个函数”。packet_rcv是tcpdump对应 packet socket 登记进去的回调函数。所谓“钩子函数”,就是内核走到这个抓包点时,额外调用一下这个函数。sk_receive_queue才是 packet socket 自己真正暂存数据包的接收队列。packet_rcv的核心工作,就是把抓到的skb放到这个队列里,等待用户态的tcpdump/libpcap读取。
这里的 packet_type 不是数据包本身,而是网络设备层的一条“包处理/包观察规则”。它大致包含这些信息:
struct packet_type {
__be16 type; // 关心哪种以太网协议类型
struct net_device *dev; // 只监听某个网卡,或 NULL 表示所有网卡
int (*func)(...); // 包匹配后调用哪个处理函数
struct list_head list; // 挂到 ptype_all/ptype_base 链表里的节点
};
如果是正常 IPv4 协议栈,可能注册的是“type = ETH_P_IP,func = ip_rcv”,意思是收到 IPv4 以太网帧后交给 IP 层处理。如果是 tcpdump 这种抓包程序,注册的则更像是“type = ETH_P_ALL,func = packet_rcv”,意思是所有以太网协议类型的包都想看一眼,匹配后调用 packet_rcv 放入 packet socket 接收队列。
所以打开 tcpdump 后,收包路径不是被改写了,而是在网络设备层多了一条旁路递交流程:
不抓包时:
网卡 -> 驱动 -> 网络设备层 -> IP/ARP 等协议处理 -> TCP/UDP socket -> 应用
抓包时:
-> tcpdump 的 packet socket 接收队列
/
网卡 -> 驱动 -> 网络设备层
\
-> IP/ARP 等协议处理 -> TCP/UDP socket -> 应用
也就是说,tcpdump 更像在网络设备层旁边放了一个观察者。它会额外拿到一份包,但原本该交给 IP、ARP、TCP、UDP 的主流程仍然继续向下走。

packet_rcv 做的核心事情,是把当前 skb 放进 packet socket 自己的接收队列:
__skb_queue_tail(&sk->sk_receive_queue, skb);
这样用户态的 tcpdump/libpcap 后续调用 recvfrom、read 或者通过 PACKET_MMAP 读取 ring buffer 时,就能拿到这个包。
所以收包方向可以串成一条完整链路:
网卡/驱动生成 skb
-> __netif_receive_skb_core
-> 遍历 ptype_all
-> deliver_skb
-> packet_rcv
-> sk_receive_queue
-> 用户态 tcpdump 读取
这也解释了一个实践现象:如果你在本机配置了 iptables -A INPUT -s x.x.x.x -j DROP,对端发来的包可能应用层收不到,但 tcpdump -i eth0 仍然能抓到。因为在收包路径上,tcpdump 站在 netfilter 之前。
三、网络包发送过程中的抓包
发包路径和收包路径刚好反过来。发包时,包先从用户进程进入协议栈,经过 TCP/IP、路由、netfilter 等处理后,才到网络设备层,最后交给驱动和网卡发送。
粗略顺序如下:
用户进程 send/write
-> TCP/UDP 传输层
-> IP 网络层
-> 路由选择
-> netfilter OUTPUT / POSTROUTING
-> 邻居子系统
-> 网络设备层
-> 驱动
-> 网卡发送
发送过程总体如图。
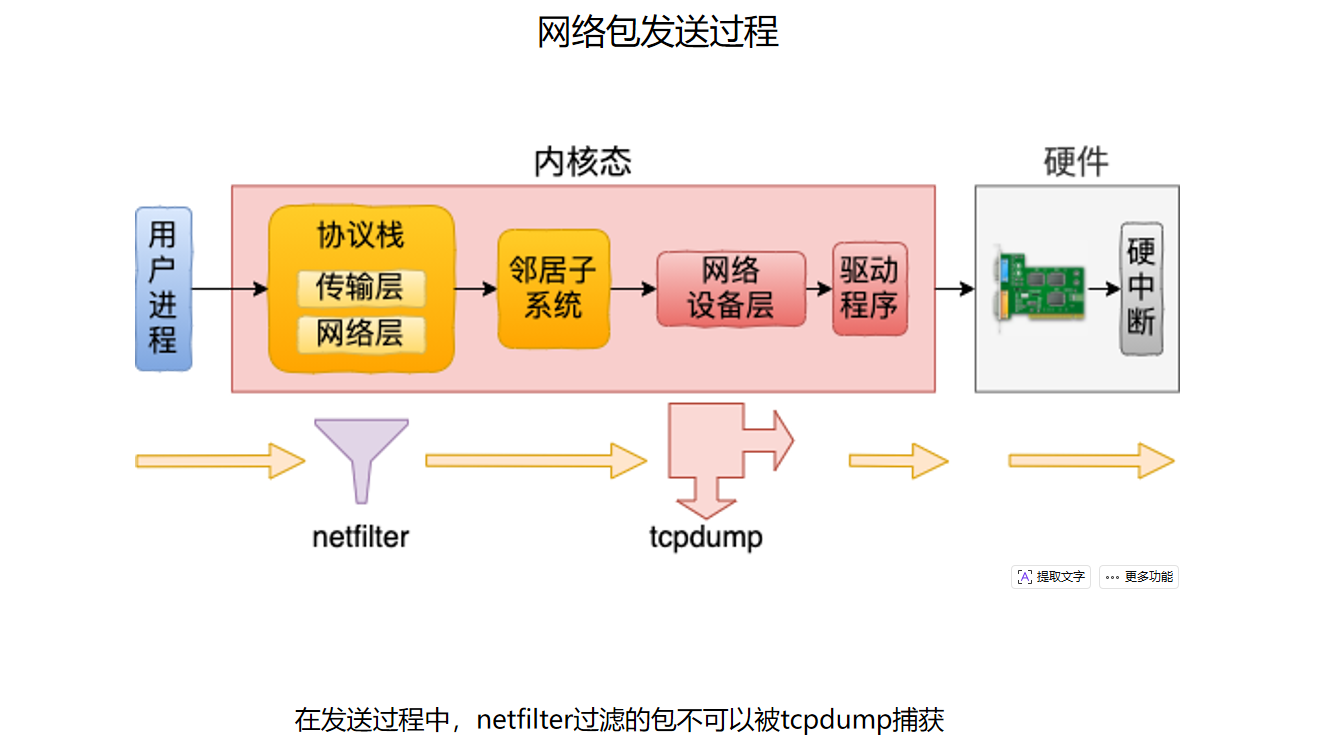
图中的关键点是:发送方向里,netfilter 位于 tcpdump 抓包点之前。如果包在 OUTPUT 或 POSTROUTING 等位置被 netfilter 丢弃,它就不会继续向下走到网络设备层,因此 tcpdump 也抓不到。
这和接收方向正好相反:
- 收包:网络设备层先看到包,netfilter 后过滤,所以被过滤的入方向包仍可能被
tcpdump抓到。 - 发包:netfilter 先过滤,网络设备层后看到包,所以被过滤的出方向包通常抓不到。
发送路径中的抓包源码在 net/core/dev.c。
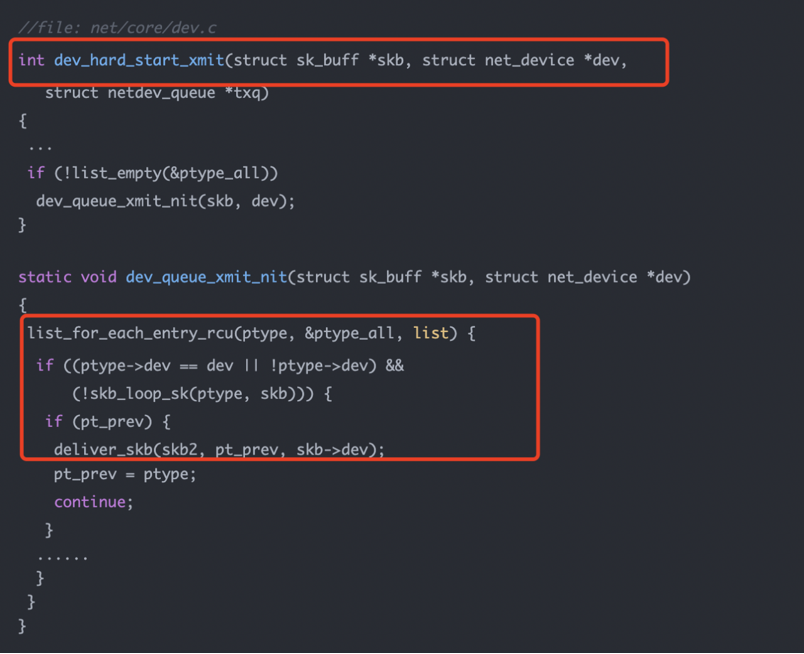
在较新的内核中,发送路径会在 xmit_one 中检查是否存在 packet socket 监听者:
if (dev_nit_active_rcu(dev))
dev_queue_xmit_nit(skb, dev);
旧版本代码里也能看到类似逻辑:在 dev_hard_start_xmit 或相关发送入口处,如果 ptype_all 非空,就调用 dev_queue_xmit_nit。
dev_queue_xmit_nit 的作用是把即将发出的包递交给网络监听者。它会遍历 ptype_all,并通过 deliver_skb 调用对应回调。对 tcpdump 来说,这个回调仍然是 packet_rcv。
发送方向的抓包链路可以串成:
send/write
-> TCP/IP 协议栈
-> netfilter OUTPUT / POSTROUTING
-> 网络设备层 xmit_one/dev_hard_start_xmit
-> dev_queue_xmit_nit
-> 遍历 ptype_all
-> packet_rcv
-> tcpdump 读取
-> 驱动真正发送
注意,这里说的是从协议栈正常发出的包。还有一些特殊场景,例如 XDP、硬件 offload、虚拟交换、抓错 interface、容器网络命名空间不同,都可能影响你实际能看到的包。但这节课要掌握的主线是:tcpdump 的经典抓包点在网络设备层,和 netfilter 的先后顺序决定了能否抓到被过滤的包。
四、抓包实验程序
理解了上面的原理后,自己写一个最小抓包程序就不神秘了。核心就是创建一个 packet socket,然后不断从这个 socket 里读取包。
实验源码主要内容如下图。
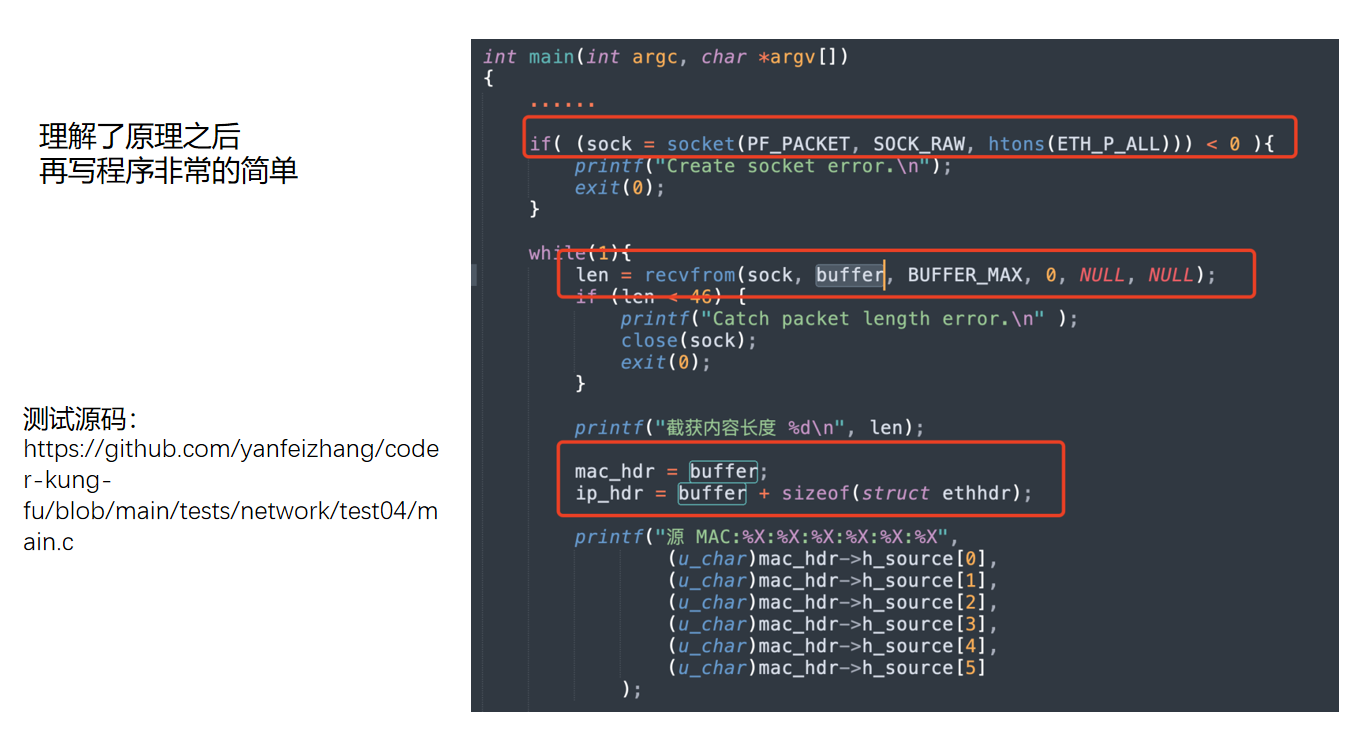
关键代码可以概括为三步:
sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
while (1) {
len = recvfrom(sock, buffer, BUFFER_MAX, 0, NULL, NULL);
mac_hdr = (struct ethhdr *)buffer;
ip_hdr = (struct iphdr *)(buffer + sizeof(struct ethhdr));
}
第一步创建 PF_PACKET + SOCK_RAW + ETH_P_ALL socket。这会触发前面分析过的 packet_create -> dev_add_pack -> ptype_all 注册过程。
第二步调用 recvfrom。它读取的不是普通 TCP socket 的应用数据,而是 packet socket 接收队列里的原始链路层帧。前面 packet_rcv 已经把匹配到的 skb 放进了这个 socket 的 sk_receive_queue,所以用户态能读到。
第三步按协议头解析 buffer。因为使用的是 SOCK_RAW packet socket,读到的数据从二层以太网头开始。因此:
buffer起始位置可以当作struct ethhdr,读取源 MAC、目的 MAC、以太网类型。buffer + sizeof(struct ethhdr)后面通常是 IP 头,可以按struct iphdr解析源 IP、目的 IP、协议号。
运行结果如下。
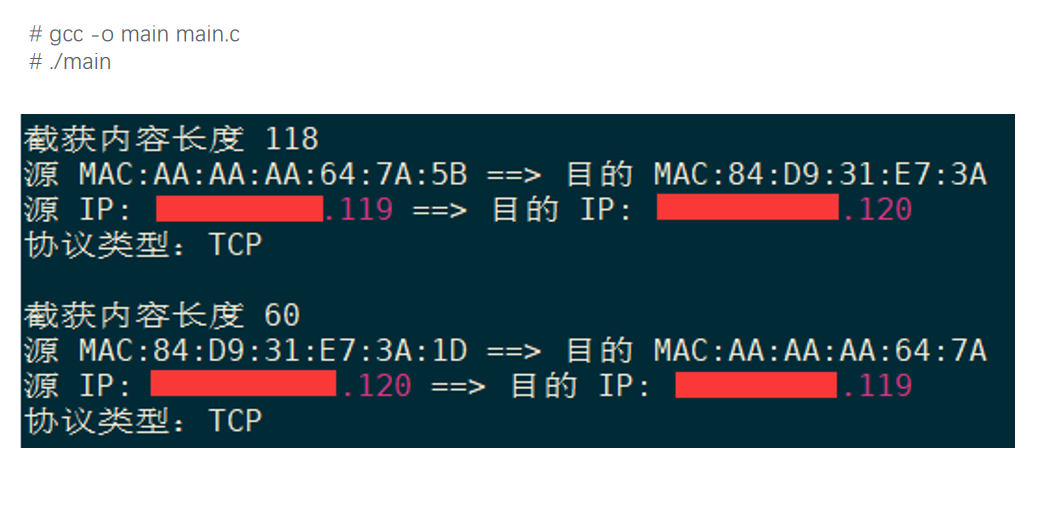
输出里第一段和第二段分别展示了两个方向的 TCP 包:
- “源 MAC -> 目的 MAC”:来自以太网头。
- “源 IP -> 目的 IP”:来自 IP 头。
- “协议类型 TCP”:来自 IP 头里的
protocol字段。 - “截获内容长度”:是本次从 packet socket 读到的帧长度。
这个 demo 只解析了最基础的以太网头和 IP 头,没有处理 VLAN、IPv6、IP 分片、TCP/UDP 端口、变长 IP 头等情况。它的价值在于证明抓包的最小闭环:只要创建 packet socket,内核就会把网络设备层观察到的包送进这个 socket,用户态程序就能读取和解析。
五、容易混淆的点
1. AF_PACKET/PF_PACKET 和 AF_INET/PF_INET
AF_INET/PF_INET 面向 IPv4 协议栈,普通 TCP/UDP socket 都走这里。应用看到的是协议栈处理后的数据。
AF_PACKET/PF_PACKET 面向链路层/设备层,能接触更原始的二层帧。tcpdump 抓包依赖的是这个能力。
2. packet socket 的 SOCK_RAW 和 IPv4 raw socket 不是一回事
socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL)) 是 packet socket,能看到链路层头。
socket(AF_INET, SOCK_RAW, protocol) 是 IPv4 raw socket,工作在 IP 层附近,不包含普通以太网二层头。两者都叫 raw,但层级不同。
3. 为什么 ETH_P_ALL 要 htons
packet socket 的第三个参数是以太网协议号,并且要求是网络字节序。ETH_P_ALL 本身是主机字节序常量,所以要写成:
htons(ETH_P_ALL)
这也是为什么 strace 里看到的不是 3,而是 768。
4. ptype_all 和 ptype_base
ptype_all 用于“我想看所有协议”的监听者,例如 ETH_P_ALL 的 tcpdump。
ptype_base 用于按具体协议类型分发,例如只关心 IPv4、ARP 等特定以太网类型的处理逻辑。
可以粗略理解为:ptype_all 更像旁路抓包链表,ptype_base 更像正常协议分发入口。但二者都属于网络设备层的 packet type 机制。
5. tcpdump 看到包,不等于应用层收到包
收包时,tcpdump 在网络设备层就可能看到包。这个包后面还可能因为 netfilter、路由、本机端口不存在、TCP 状态不匹配等原因被丢弃。
所以排查网络问题时,如果 tcpdump 能看到包,只能说明包到达了这个抓包点;不能直接说明应用已经收到。
另外,打开 tcpdump 一般不会改变正常协议栈的主流程。它主要增加的是旁路观察开销:内核要额外遍历 ptype_all,把匹配的包送进 packet socket 的接收队列。如果抓包程序读得太慢,丢的通常是抓包队列里的包,不等于业务 socket 一定丢包。
6. 收包和发包方向上,tcpdump 与 netfilter 的相对位置相反
这是本节最重要的判断规则:
收包:网卡/驱动 -> 网络设备层 tcpdump -> IP 层 netfilter -> 协议栈
发包:协议栈 -> IP 层 netfilter -> 网络设备层 tcpdump -> 驱动/网卡
因此:
- 入方向被 netfilter 丢弃的包,
tcpdump通常仍能抓到。 - 出方向被 netfilter 丢弃的包,
tcpdump通常抓不到。
六、本文参考与延伸
- 《深入理解 Linux 网络》:本节课的背景知识来源之一,适合系统理解 Linux 收包、发包、协议栈、软中断、驱动和性能问题。
- 用户态 tcpdump 如何实现抓到内核网络包的?:主线是
AF_PACKET、packet_create、ptype_all、packet_rcv。 - 来,今天飞哥带你理解 iptables 原理!:用于理解 netfilter 四表五链,以及为什么收包/发包方向上过滤点位置不同。
- 图解 Linux 网络包接收过程:用于补齐收包路径,从网卡、硬中断、NAPI、软中断到协议栈。
- 25 张图,一万字,拆解 Linux 网络包发送过程:用于补齐发包路径,从
send到协议栈、路由、邻居子系统、网络设备层和驱动。 - packet(7) - Linux manual page:官方手册,解释
AF_PACKET、SOCK_RAW、SOCK_DGRAM、ETH_P_ALL、CAP_NET_RAW等概念。 - Packet MMAP - The Linux Kernel documentation:解释高性能抓包为什么会使用
PACKET_RX_RING、mmap、TPACKET_V3等机制。本文实验用的是简单recvfrom,真实tcpdump/libpcap常会利用更高效的 ring buffer。 - Linux 源码:net/packet/af_packet.c:可查看
packet_create、packet_rcv、register_prot_hook等实现。 - Linux 源码:net/core/dev.c:可查看
dev_add_pack、__netif_receive_skb_core、dev_queue_xmit_nit、dev_hard_start_xmit等实现。 - 14-tcpdump 原理-源码分析