
本机网络 IO 工作原理
这篇笔记回答一个很容易被低估的问题:两个进程都在同一台 Linux 机器上,使用
127.0.0.1或本机 IP 通信时,数据到底怎么走?结论先放前面:本机 TCP 通信仍然会走系统调用、socket、TCP/IP 协议栈、路由、netfilter 和网络设备层,只是路由结果指向lo,最终由 loopback 伪设备把 skb 重新送回接收路径。它不经过物理网卡、DMA、真实链路和物理硬中断,但仍然有协议栈和软中断开销。
目录
- 一、先建立整体图景
- 二、跨机网络通信回顾
- 三、本机发送过程:差异从路由开始
- 四、本机接收过程:从 backlog 回到协议栈
- 五、跨机和本机通信对比
- 六、本机网络 IO 优化
- 七、常用观测命令
- 八、常见误区
- 九、参考资料
一、先建立整体图景
1.1 一句话主线
普通 TCP 本机通信可以概括成这条链路:
发送进程
send() / write()
-> socket 层
-> TCP 层构造或发送 skb
-> IP 层查路由、过 netfilter、处理 MTU
-> 路由命中 local 表,出口设备选择 lo
-> dev_queue_xmit()
-> loopback_xmit()
-> __netif_rx() / backlog
-> NET_RX_SOFTIRQ
-> process_backlog()
-> IP/TCP 接收路径
-> 对端 socket 接收队列
-> 唤醒接收进程
这里最关键的是三点:
- 本机 TCP 不是用户态直接拷贝给另一个进程。它仍然先进入内核,并经过 TCP/IP 协议栈。
- 本机 TCP 不经过物理网卡。路由命中本机地址时,出口设备会变成
lo,也就是 loopback 回环设备。 - loopback 是伪网卡,不是魔法捷径。它省掉了物理网卡 DMA、RingBuffer、网线传输、发送完成硬中断等开销,但会把包重新注入内核接收路径。
1.2 先区分三种本机通信方式
| 通信方式 | 典型地址或接口 | 是否走 TCP/IP 协议栈 | 主要特点 |
|---|---|---|---|
| 本机 TCP | 127.0.0.1:port、本机网卡 IP:port |
是 | 兼容网络编程模型,能复用 TCP、netfilter、服务治理等能力 |
| Unix Domain Socket | AF_UNIX,如 /dev/shm/app.sock |
否 | 面向同机 IPC,路径更短,通常延迟和吞吐更好 |
| eBPF sockmap/sockops | TCP socket + BPF map | 可部分绕过 | 常用于 sidecar、服务网格等本机 TCP 转发加速 |
这篇笔记先解释“普通本机 TCP 为什么仍然不便宜”,再解释为什么 UDS 和 eBPF 能进一步优化。
二、跨机网络通信回顾
理解本机通信之前,先把跨机网络 IO 的发送和接收链路回忆一下。后面所有差异都来自“哪些环节还在,哪些环节被 loopback 替换”。
2.1 跨机接收过程
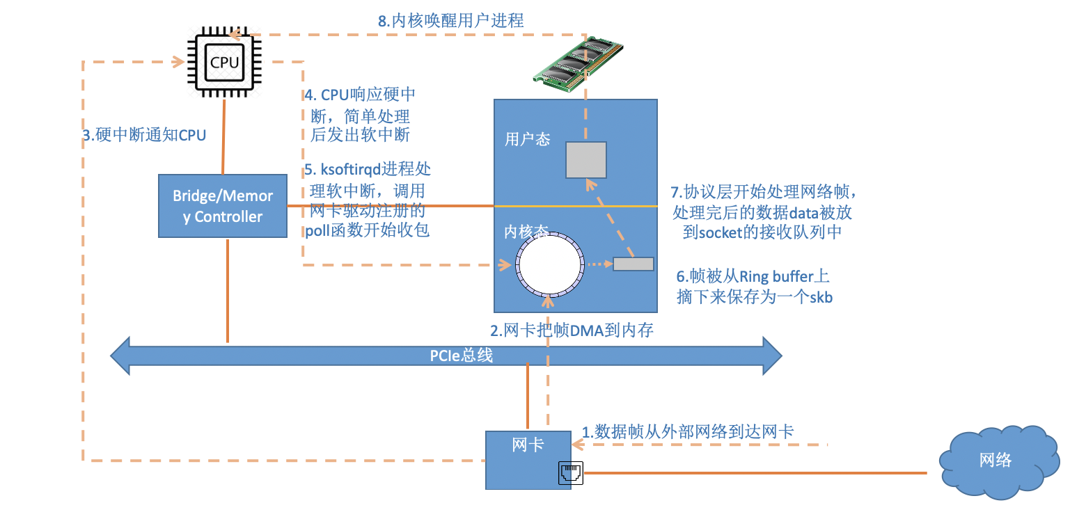
读图重点:
- 第 1 步,外部网络帧到达物理网卡。
- 第 2 步,网卡通过 DMA 把数据写入内存中的 RingBuffer。
- 第 3、4 步,网卡发起硬中断通知 CPU,CPU 进入驱动的中断处理函数,快速处理后退出硬中断。
- 第 5 步,驱动触发
NET_RX_SOFTIRQ,由软中断上下文或ksoftirqd继续处理。 - 第 6 步,驱动从 RingBuffer 摘下数据,构造成
sk_buff,也就是内核网络栈里的 skb。 - 第 7 步,协议栈按链路层、IP 层、TCP/UDP 层逐层处理,最后把数据放入目标 socket 的接收队列。
- 第 8 步,如果用户进程正在阻塞等待
recv(),内核会唤醒它。
这张图说明什么:
跨机接收的开销不只在协议栈,还包括物理网卡、DMA、硬中断、软中断、驱动轮询、RingBuffer 管理等一整套设备路径。
容易误解的点:
硬中断只是通知和调度,真正大量处理通常放在软中断中完成。这样可以避免 CPU 长时间停在硬中断上下文里。
2.2 跨机发送过程
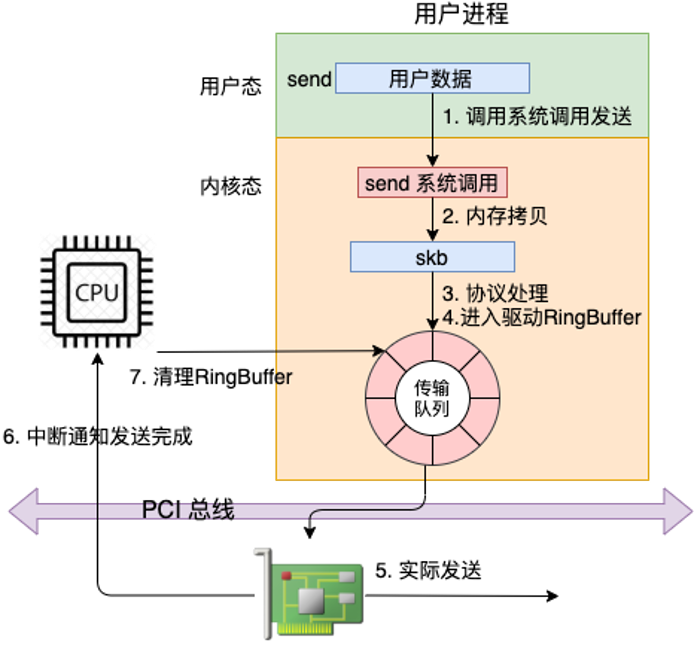
读图重点:
- 应用调用
send(),从用户态陷入内核态。 - 内核把用户数据拷贝或组织到 socket 发送缓冲区中,并用 skb 表示。
- TCP 层决定是否立即发送、如何切分、如何设置序号和 ACK 等头部信息。
- IP 层查路由,选择出口网卡,处理 netfilter 和 MTU。
- 网络设备层进入 qdisc 和驱动,驱动把 skb 映射给网卡,填充 TX Ring。
- 物理网卡最终通过 PCIe、DMA 和链路层把帧发送出去。
这张图说明什么:
send() 返回不代表对端已经收到数据,甚至不代表物理网卡已经完全发送完成。它更多表示用户数据已经被内核接受,后续由协议栈、驱动和网卡继续推进。
容易误解的点:
发送路径的大部分协议栈处理发生在发起 send() 的进程上下文中,但发送完成后的清理可能由硬中断和软中断触发。
2.3 跨机通信总览
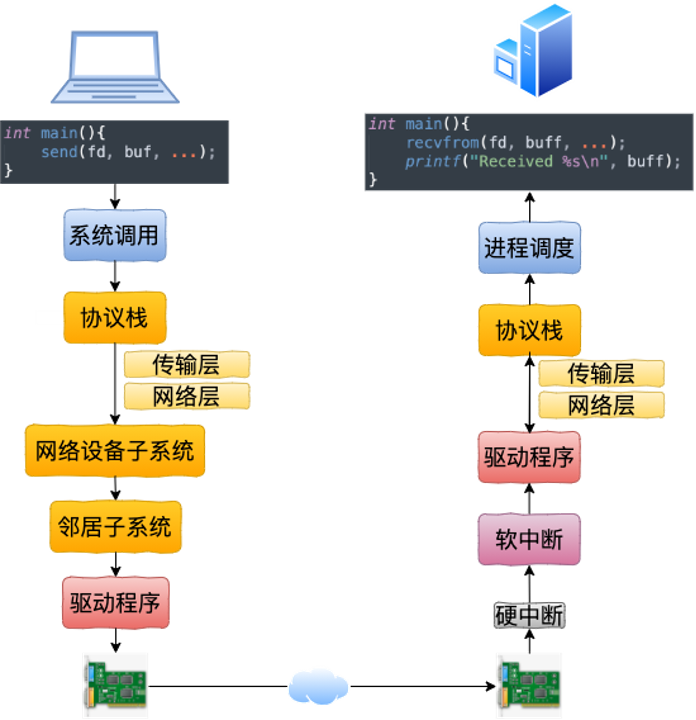
读图重点:
左侧是发送机器,右侧是接收机器。跨机通信是两台机器各自完成半条链路:
发送端:应用 -> 系统调用 -> 协议栈 -> 网络设备子系统 -> 邻居子系统 -> 驱动 -> 网卡
接收端:网卡 -> 硬中断 -> 软中断 -> 驱动 -> 协议栈 -> 进程调度 -> 接收应用
这张图说明什么:
跨机通信有两套内核网络路径:发送端一套,接收端一套,中间还有真实网络。之后看本机通信时,可以问一个问题:如果发送端和接收端在同一台机器上,Linux 会不会把这两套路径合并掉?答案是:不会完全合并,只是在设备层用 lo 把发送路径接回接收路径。
三、本机发送过程:差异从路由开始
本机 TCP 的前半段和普通 TCP 发送非常像。应用仍然调用 send(),内核仍然形成 skb,TCP/IP 协议栈仍然工作。真正的分叉点出现在 IP 层查路由之后。
3.1 路由过程不同:命中 local 路由表
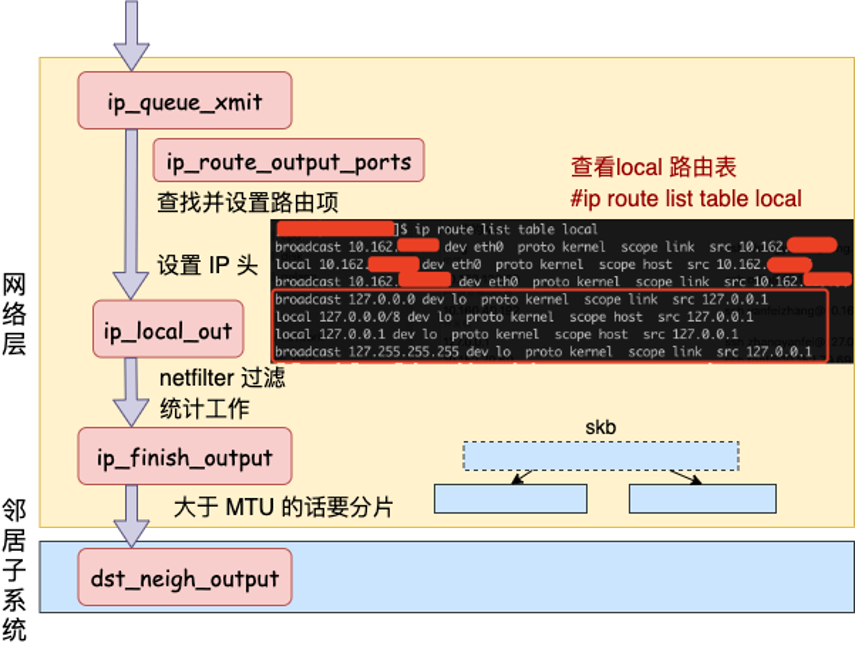
读图重点:
ip_queue_xmit()进入 IP 层发送路径。ip_route_output_ports()查找路由,并把路由结果挂到 skb 上。- 对于本机目的地址,路由类型会命中
RTN_LOCAL,出口设备选择lo。 - 之后仍然会经过
ip_local_out()、netfilter、ip_finish_output()等逻辑,再往网络设备层走。
这张图说明什么:
本机通信的特殊点不是“不查路由”,而是查出来的结果不同。普通跨机包通常路由到 eth0 等物理网卡,本机包路由到 lo。
可以用下面命令观察本机 local 路由表:
ip route list table local
3.2 127.0.0.1 和本机 IP 都可能走 lo
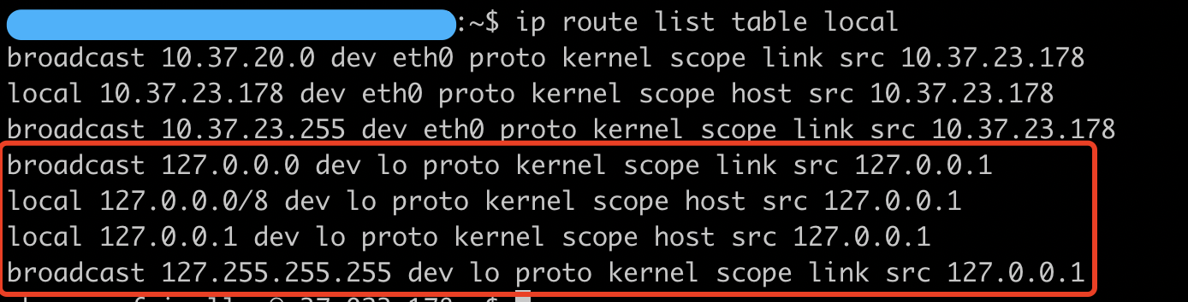
读图重点:
图中 ip route list table local 里既有 127.0.0.0/8 dev lo,也有本机网卡 IP 对应的 local ... dev eth0 或 local 路由项。不同发行版和内核版本显示会有差异,但核心判断是:这个目的地址是否属于本机。
这张图说明什么:
访问 127.0.0.1 一定是回环通信;访问本机网卡 IP,例如 10.x.x.x、192.168.x.x,如果目的地址就是本机,也会被内核当作 local 流量处理,不会真的从物理网卡发出去再绕回来。
容易误解的点:
dev eth0 出现在 local 表里不等于数据真的从 eth0 出线。内核路由逻辑识别到 RTN_LOCAL 后,会把输出设备设置为网络命名空间里的 loopback 设备。老版本源码里可以看到类似逻辑:
if (res.type == RTN_LOCAL) {
dev_out = net->loopback_dev;
}
这也是为什么“本机 IP 通信”和“127.0.0.1 通信”在内核路径上很接近。
3.3 源码视角:本机路由选择 loopback
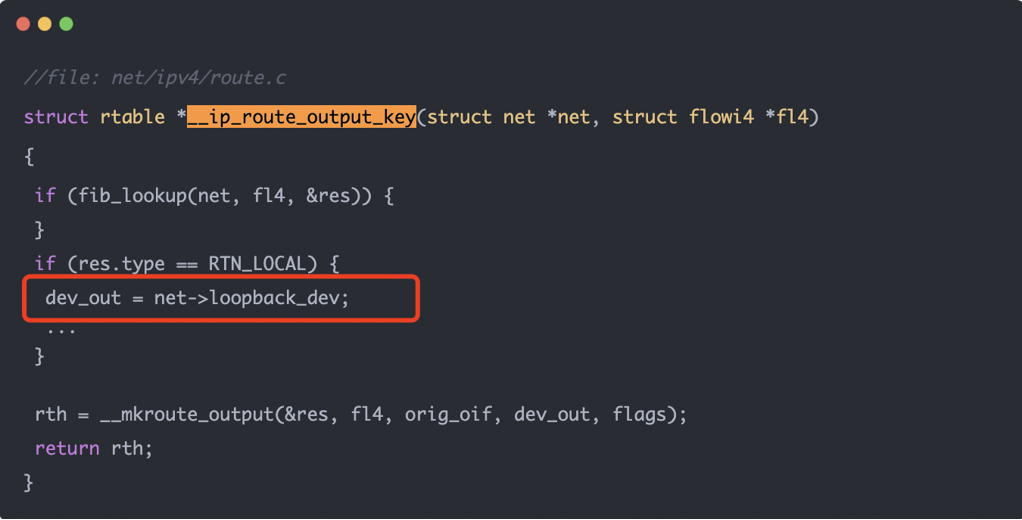
读图重点:
- 图里展示的是路由输出函数的关键判断。
- 当路由查询结果
res.type == RTN_LOCAL时,dev_out被设置为net->loopback_dev。 - 后续 skb 进入设备层时,调用的就不再是物理网卡驱动的发送函数,而是 loopback 设备的发送函数。
这张图说明什么:
本机 TCP 发送路径的核心转折点就是路由。它没有跳过 TCP/IP 协议栈,而是在 IP 层之后选择了一个特殊的“出口设备”。
3.4 MTU 更大:降低 IP 分片概率
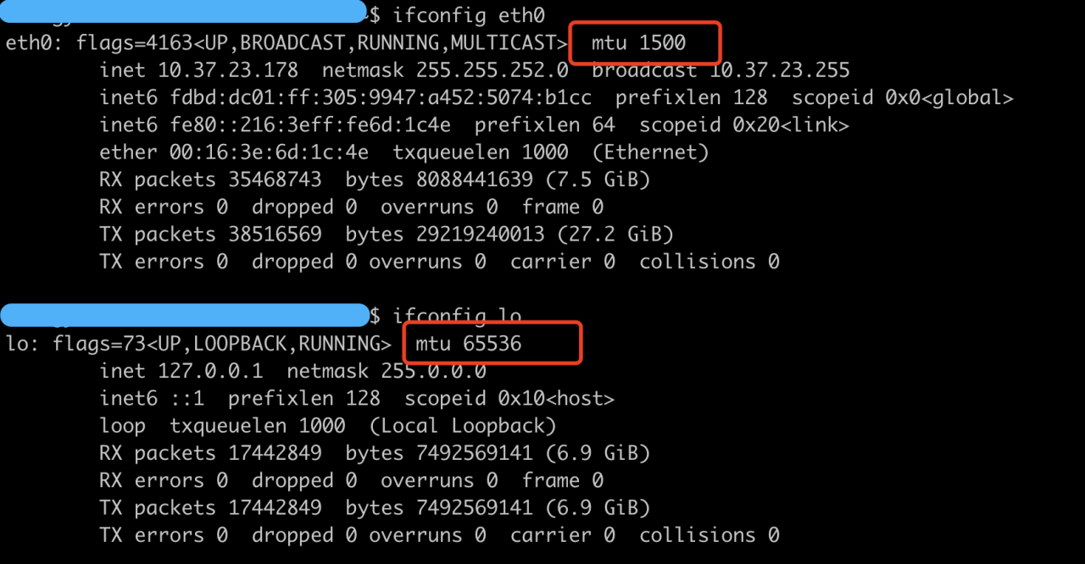
读图重点:
- 图里
eth0的 MTU 是 1500,这是以太网常见值。 - 图里
lo的 MTU 是 65536,也就是 64K 左右。 - IP 层在
ip_finish_output()附近会判断 skb 长度是否超过路径 MTU,超过且不能通过 GSO 等方式处理时,才需要分片。
这张图说明什么:
本机通信走 lo,MTU 通常远大于物理网卡,所以在 IP 层触发分片的概率更低。这样可以减少分片处理开销,也避免“任意一个分片丢失导致整个 IP 包无法重组”的问题。
容易误解的点:
lo MTU 大不等于没有 TCP 分段。TCP 仍然有 MSS、发送缓冲区、拥塞控制、GSO/GRO 等机制。MTU 影响的是 IP 层分片和设备层可承载的包大小,不代表应用一次 send() 就会原样变成一个完整包。
3.5 设备驱动不同:物理网卡驱动 vs loopback 驱动
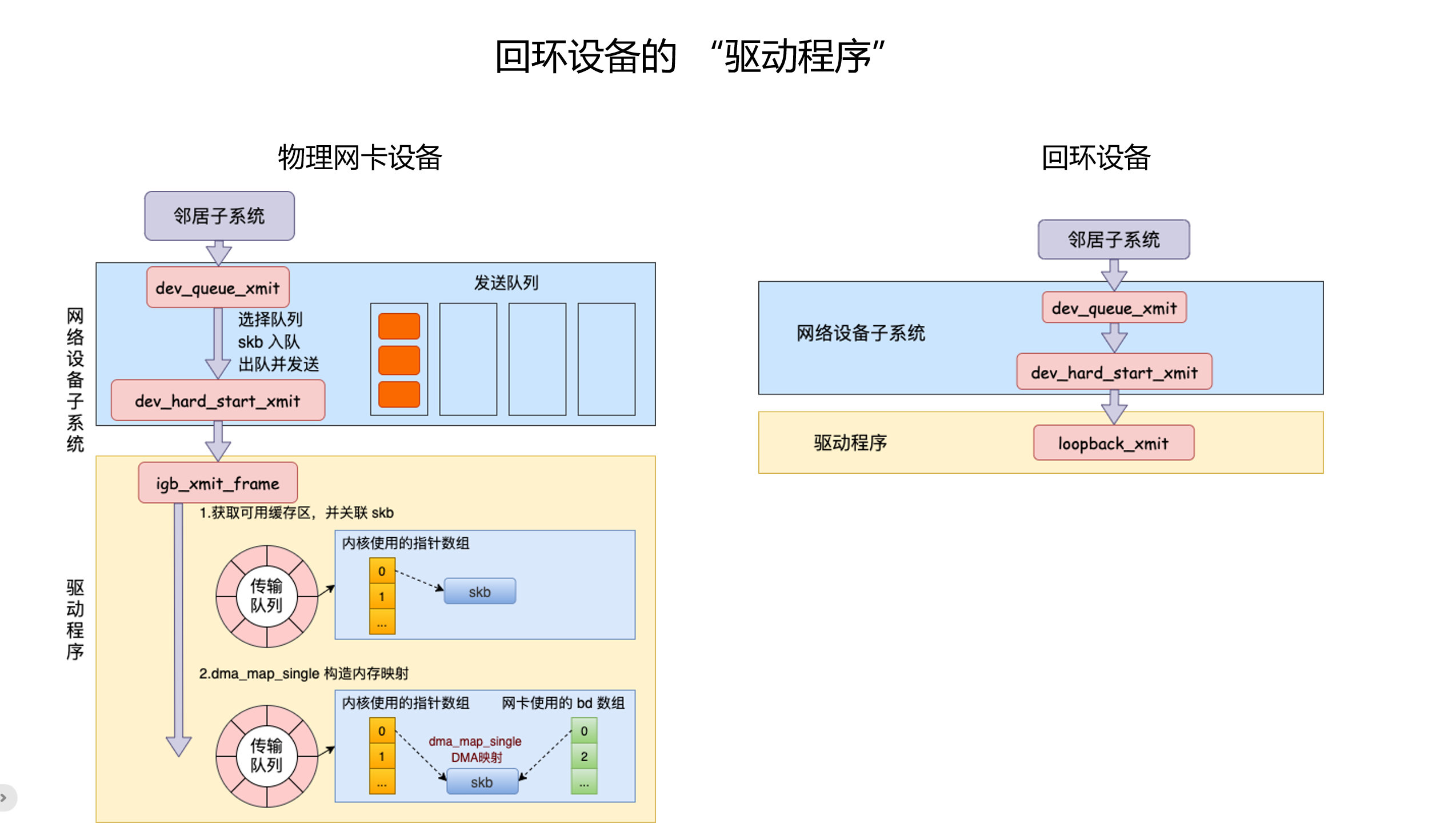
读图重点:
左侧是物理网卡发送路径,大致包含:
- 邻居子系统处理下一跳和 MAC 地址。
dev_queue_xmit()进入网络设备子系统。- qdisc 选择发送队列,skb 入队或直接下发。
- 驱动函数如
igb_xmit_frame()获取 TX Ring 可用描述符。 - 驱动把 skb 的内存地址通过 DMA 映射给网卡。
- 网卡读取内存并真正发送,完成后再通过中断通知内核清理。
右侧是 loopback 设备路径,大致是:
- 仍然进入
dev_queue_xmit()。 - 设备层调用
dev_hard_start_xmit()。 - 最终调用 loopback 设备的
loopback_xmit()。
这张图说明什么:
本机通信节省的主要是物理设备相关成本:不用真实网卡发送,不用 DMA 映射,不用 TX Ring,不用等待网卡发送完成硬中断。
3.6 loopback_xmit():把 skb 重新送入接收路径
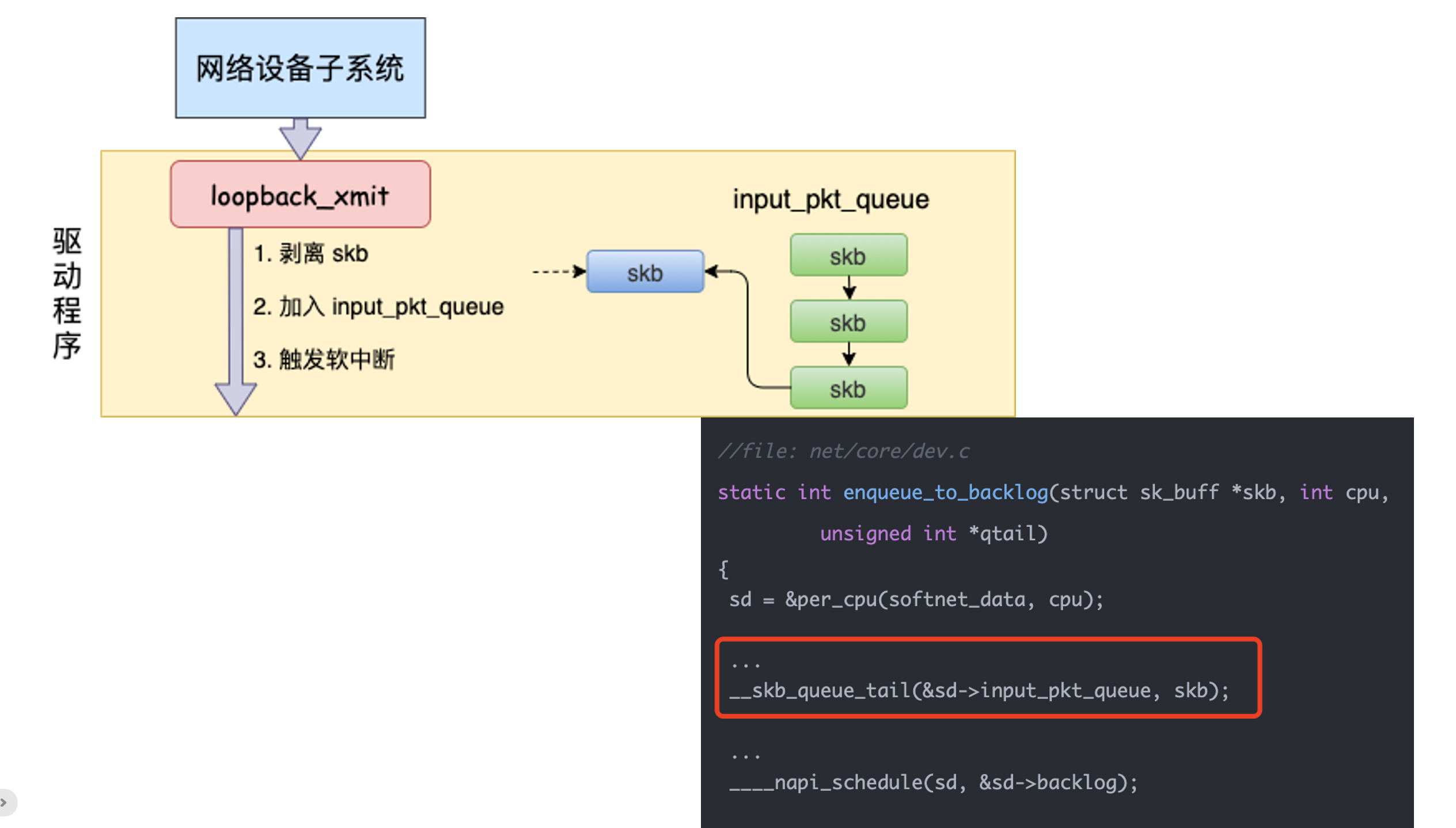
读图重点:
loopback_xmit()不会把数据交给物理设备。- 它会先处理 skb,比如剥离发送端 socket 关联、设置协议字段、维护统计。
- 然后通过
__netif_rx()或同类接收入口,把 skb 放入当前 CPU 的接收 backlog。 - 接着触发接收方向的软中断,让后续接收路径继续处理。
在现代内核源码里,loopback 设备仍然能看到类似主线:
static netdev_tx_t loopback_xmit(struct sk_buff *skb, struct net_device *dev)
{
skb_orphan(skb);
skb_dst_force(skb);
skb->protocol = eth_type_trans(skb, dev);
__netif_rx(skb);
return NETDEV_TX_OK;
}
这张图说明什么:
loopback 的本质不是“发送到网卡”,而是“从发送路径切回接收路径”。所以本机 TCP 是一条在内核里绕回来的网络链路。
四、本机接收过程:从 backlog 回到协议栈
4.1 本机接收没有物理硬中断
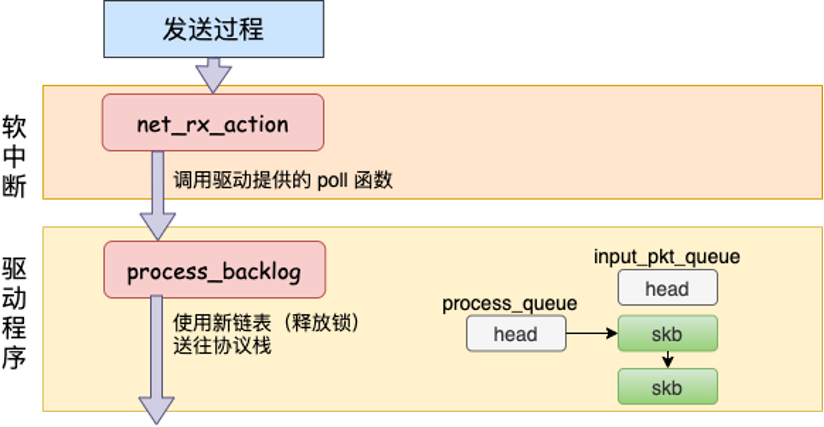
读图重点:
- 跨机接收通常从物理网卡硬中断开始。
- 本机接收则来自发送路径里的
loopback_xmit()。 loopback_xmit()把 skb 放入input_pkt_queue或 backlog 队列,并触发NET_RX_SOFTIRQ。- 软中断执行
net_rx_action(),再调用process_backlog()从队列中取出 skb。 - 取出的 skb 继续交给协议栈处理,最终进入对端 socket 的接收队列。
这张图说明什么:
本机接收路径省掉了“网卡收到帧、DMA 到 RingBuffer、发起硬中断”的前置过程,但进入协议栈之后,IP/TCP 层和 socket 接收队列处理仍然存在。
可以把本机接收想成:
loopback_xmit()
-> enqueue_to_backlog()
-> raise NET_RX_SOFTIRQ
-> net_rx_action()
-> process_backlog()
-> __netif_receive_skb()
-> ip_rcv()
-> tcp_v4_rcv()
-> sk_receive_queue
-> wake up recv()
容易误解的点:
本机通信没有物理硬中断,不代表没有软中断。实际上,loopback 正是通过接收软中断把 skb 推进后续协议栈。
五、跨机和本机通信对比
5.1 总体对比图
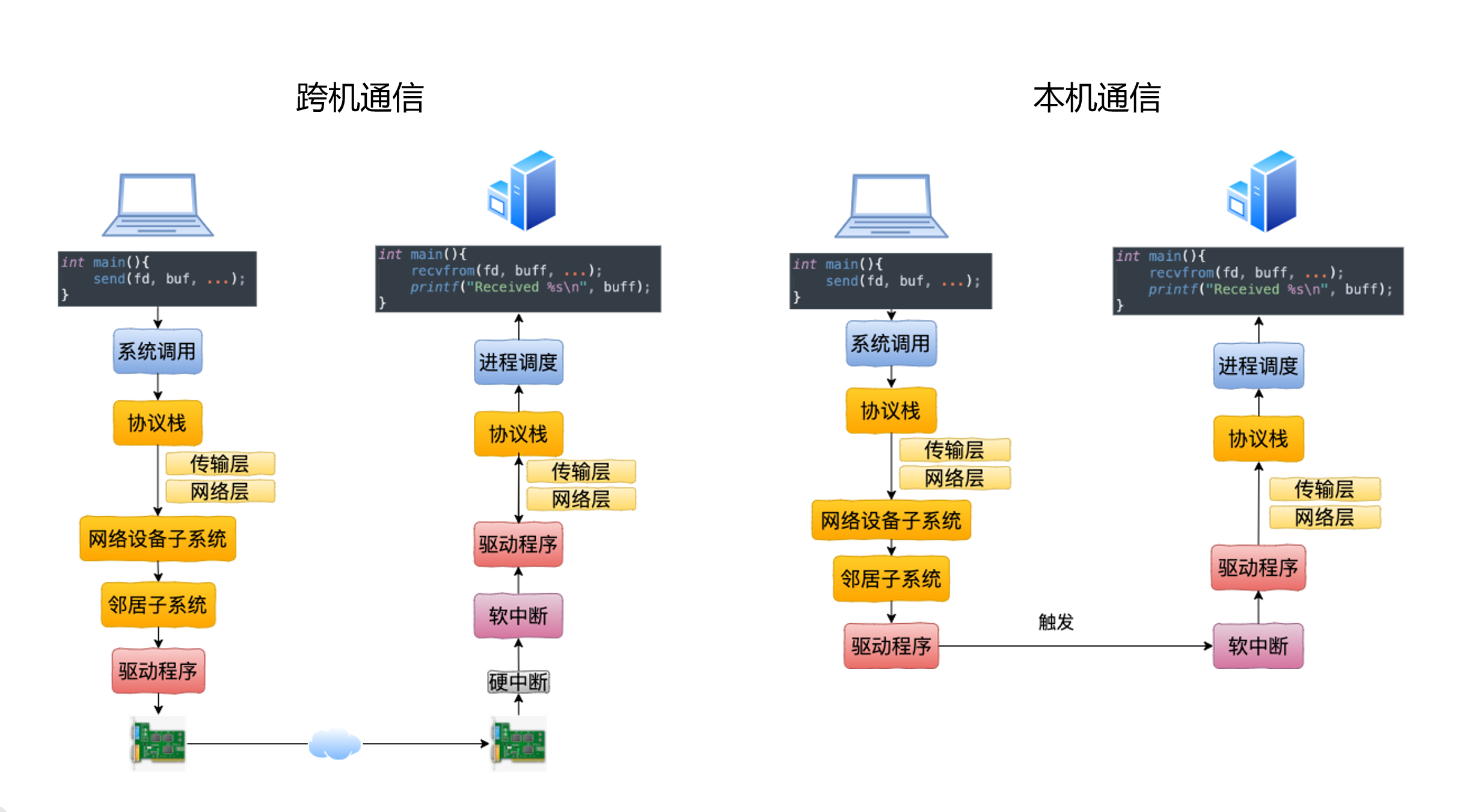
读图重点:
- 左侧跨机通信,发送端和接收端各有一套设备路径,中间经过真实网络。
- 右侧本机通信,发送路径走到网络设备子系统后,由 loopback 驱动触发软中断,再回到本机接收路径。
- 本机通信没有物理网卡传输,但发送和接收两侧协议栈逻辑仍然存在。
5.2 对照表
| 环节 | 跨机 TCP | 本机 TCP |
|---|---|---|
| 系统调用 | send() / recv() |
send() / recv() |
| socket 层 | 需要 | 需要 |
| TCP/IP 协议栈 | 需要 | 需要 |
| 路由查询 | 查 main/local 等路由表,通常选物理网卡 | 命中 local,出口选 lo |
| netfilter | 可能经过 | 也可能经过,取决于 hook 和规则 |
| 邻居子系统 | 通常需要 ARP/邻居缓存 | 基本不需要真实下一跳 MAC |
| 网络设备层 | 物理网卡设备 | loopback 伪设备 |
| qdisc | 可能参与排队、限速、调度 | lo 常见为 noqueue 或轻量路径 |
| DMA / RingBuffer | 需要 | 不需要物理 DMA/TX Ring |
| 硬中断 | 接收和发送完成都可能触发 | 没有物理网卡硬中断 |
| 软中断 | NET_RX_SOFTIRQ 等 |
仍然会触发 NET_RX_SOFTIRQ |
| 数据拷贝 | 用户态到内核态,网卡 DMA 等 | 用户态到内核态,内核中 skb 流转 |
| 性能瓶颈 | 网卡、驱动、中断、协议栈、链路 | 协议栈、软中断、内存拷贝、进程调度 |
一句话总结:
本机 TCP 省掉的是物理网络设备和真实链路,不是整套网络协议栈。
六、本机网络 IO 优化
普通本机 TCP 的优势是兼容性强,缺点是路径仍然偏长。优化思路通常有两类:一类是换 IPC 机制,比如 Unix Domain Socket;另一类是在保留 TCP socket 的前提下,用 eBPF sockmap/sockops 对本机转发做数据面加速。
6.1 Unix Domain Socket:同机 IPC 的更短路径
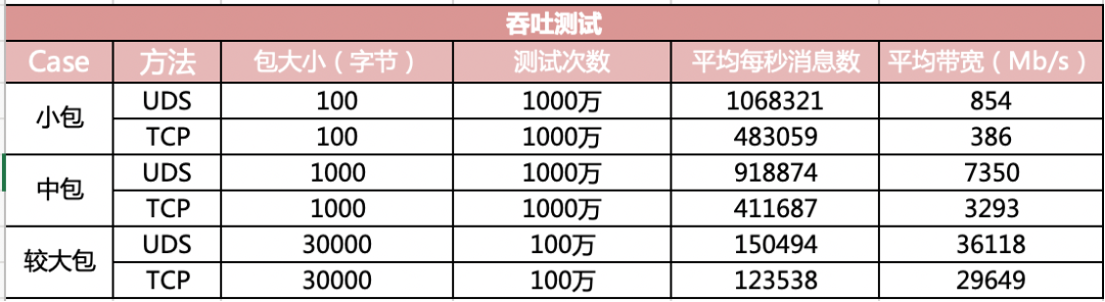
读图重点:
这张图展示了 UDS 和 TCP 在吞吐指标上的对比。小包场景里,UDS 的每秒消息数和平均带宽明显高于 TCP loopback;包变大后,两者差距缩小,但 UDS 仍然通常更有优势。
为什么 UDS 更快:
UDS 使用 AF_UNIX,通信双方通过文件系统路径或抽象命名空间定位,而不是通过 IP 和端口定位。它不需要 IP 层路由、TCP 拥塞控制、重传、netfilter、loopback 设备回注等完整网络路径。
典型使用方式:
int fd = socket(AF_UNIX, SOCK_STREAM, 0);
Nginx 访问本机 PHP-FPM 时也常见类似配置:
fastcgi_pass unix:/dev/shm/fpm-cgi.sock;
6.2 UDS 发送:直接进入对端接收队列
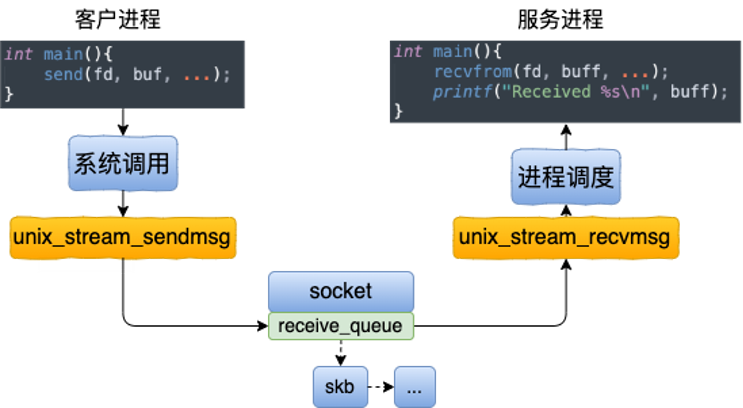
读图重点:
- 发送进程调用
send()后进入 Unix socket 的发送函数,例如unix_stream_sendmsg()。 - 内核申请 skb,并把用户数据拷贝进 skb。
- 通过 socket 的 peer 关系找到对端 socket。
- 把 skb 直接挂到对端 socket 的
sk_receive_queue。 - 调用对端 socket 的数据到达回调,唤醒正在等待的接收进程。
可以把 UDS 主线简化成:
send()
-> unix_stream_sendmsg()
-> sock_alloc_send_skb()
-> copy user data into skb
-> unix_peer(sk)
-> skb_queue_tail(&peer->sk_receive_queue, skb)
-> peer->sk_data_ready()
-> recv()
这张图说明什么:
UDS 仍然有系统调用和用户态到内核态的数据拷贝,但绕过了 TCP/IP 协议栈和网络设备层。因此,在单机内高频 IPC 中,UDS 往往比 127.0.0.1 TCP 更合适。
适用场景:
- Nginx 和 PHP-FPM 在同机通信。
- 本机 agent、daemon、数据库 proxy 之间的控制面通信。
- 不需要跨机透明迁移,只需要单机 IPC 的高频请求。
不适用或要谨慎的场景:
- 需要直接保留 TCP/IP 地址语义的服务。
- 强依赖 iptables、sidecar、透明代理、网络安全策略的链路。
- 未来可能从单机部署迁移到跨机部署的组件。
6.3 eBPF sockmap/sockops:保留 TCP 接口,缩短本机转发路径
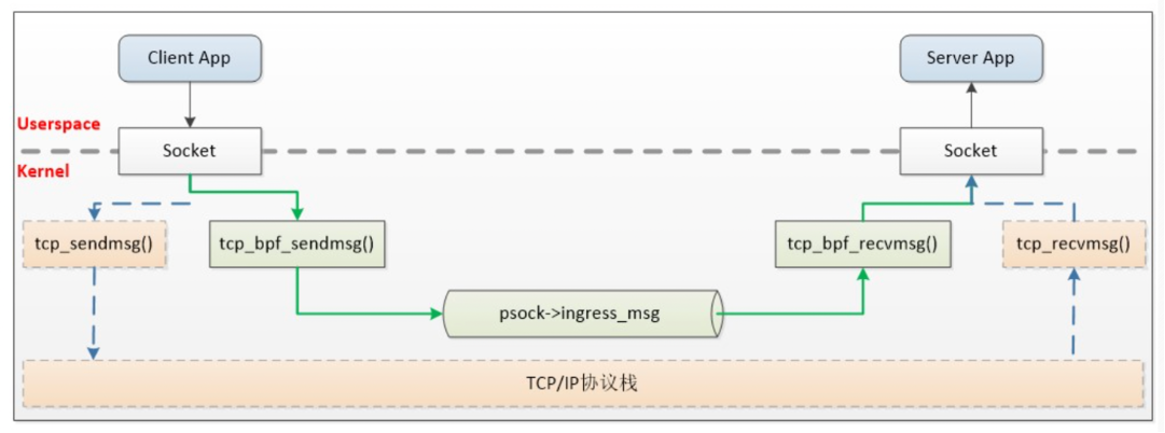
读图重点:
- 图中虚线是传统 TCP/IP 协议栈路径。
- 绿色路径是 eBPF sockmap 加速路径。
- BPF 程序 hook 到 socket 发送或接收相关位置,例如
sk_msg、sk_skbverdict。 - 当流量命中 sockmap/sockhash 中记录的 socket,BPF 可以 redirect 到目标 socket。
- 对于本机 sidecar 场景,这能减少本地应用和代理之间来回经过 TCP/IP 协议栈的开销。
核心概念:
| 概念 | 说明 |
|---|---|
BPF_MAP_TYPE_SOCKMAP |
用数组形式保存 socket 引用 |
BPF_MAP_TYPE_SOCKHASH |
用 hash key 保存 socket 引用,适合四元组等 key |
BPF_SK_MSG_VERDICT |
对发送消息做 verdict,可配合 bpf_msg_redirect_map() |
BPF_SK_SKB_VERDICT |
对 skb 做 verdict,可配合 bpf_sk_redirect_map() |
| sockops | 常用于监听 TCP 状态变化,在连接建立时把 socket 放进 map |
这张图说明什么:
eBPF sockmap 的目标不是把所有本机通信都替换成 UDS,而是在还使用 TCP socket 的情况下,给内核一个“这两个 socket 可以直接转发”的信息,从而绕过部分协议栈路径。
适用场景:
- 服务网格 sidecar,例如应用进程和 Envoy 在同一个 Pod 或同一台机器内通信。
- 本机 TCP proxy 转发频繁,协议栈开销显著。
- 团队具备 eBPF 程序发布、观测、回滚和内核兼容性治理能力。
边界和代价:
- 依赖内核版本和 BPF 能力,sockmap 从 Linux 4.14 左右开始出现,sockhash 更晚。
- 程序需要通过 verifier 校验,能力边界和内核版本相关。
- 线上排查复杂度高于普通 TCP 和 UDS。
- 对 iptables redirect、sidecar 连接方向、四元组匹配等场景要额外处理。
6.4 三种方案怎么选
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 想保持普通网络编程和跨机兼容 | 本机 TCP | 改造最少,兼容性最好 |
| 两个进程固定同机部署,追求低延迟 IPC | Unix Domain Socket | 路径短,通常性能更好 |
| 服务网格或 sidecar 本机 TCP 转发压力大 | eBPF sockmap/sockops | 保留 TCP 接口,同时减少重复协议栈开销 |
| 只是偶发本机管理请求 | 本机 TCP 或 UDS 都可 | 性能差异通常不是瓶颈 |
| 团队缺少 eBPF 运维经验 | 优先 UDS 或普通 TCP | 降低内核态复杂度 |
七、常用观测命令
7.1 看本机 local 路由
ip route list table local
关注点:
local 127.0.0.1 dev lo- 本机网卡 IP 对应的
local x.x.x.x - 目的地址是否被识别为本机地址
7.2 看地址和 loopback MTU
ip addr
ip link show lo
关注点:
lo是否UPlo的 MTU,常见是65536- 本机业务监听的是
127.0.0.1、0.0.0.0还是某个具体网卡 IP
7.3 看 TCP 连接状态
ss -tinp
关注点:
- 本机连接的两端地址和端口。
- send/recv 队列是否积压。
- TCP 内部状态,如拥塞窗口、rtt、重传等。
7.4 抓 loopback 流量
tcpdump -i lo -nn port 8080
如果访问本机服务时能在 lo 上抓到包,说明它确实走了 loopback 接口。注意抓包会带来额外开销,线上高流量环境谨慎使用。
7.5 看软中断
cat /proc/softirqs
关注 NET_RX。本机 loopback 流量也会增加接收方向软中断相关统计,所以不要把 NET_RX 简单理解成“外部网卡收包”。
7.6 看 softnet backlog
cat /proc/net/softnet_stat
关注是否有 backlog 溢出或处理不过来的迹象。不同内核版本字段含义要结合内核文档或源码确认,常见排查重点是是否有丢包、time squeeze、CPU 分布不均等问题。
7.7 看进程是否使用 UDS
ss -x -a -p
关注点:
u_str、u_dgrm等 Unix socket 类型。- socket path,例如
/run/app.sock、/dev/shm/fpm-cgi.sock。 - 哪些进程持有这个 socket。
八、常见误区
8.1 “本机 IO 不出网卡,所以没有内核开销”
不对。本机 TCP 不经过物理网卡,但仍然经过系统调用、socket、TCP/IP 协议栈、路由、设备层、软中断和进程唤醒。它只是省掉了物理设备路径。
8.2 “loopback 就是用户态直接拷贝”
不对。loopback 是内核网络设备。它的工作是把发送路径里的 skb 重新注入接收路径,而不是在两个用户进程之间直接搬运内存。
8.3 “访问本机网卡 IP 一定会从网卡出去”
不对。目的地址如果属于本机,路由会命中 local 类型,实际会由 loopback 接收路径处理。可以用 ip route get <本机IP> 和 ip route list table local 验证。
8.4 “lo MTU 大,所以不会切包”
不严谨。lo MTU 大会降低 IP 分片概率,但 TCP 层仍有 MSS、发送缓冲区、GSO/GRO 等机制。应用层一次写入和内核里的 skb、TCP segment、IP packet 不是一一对应关系。
8.5 “UDS 一定可以替代 TCP”
不对。UDS 适合同机 IPC,但它没有 IP 地址和端口语义,也不适合需要透明迁移到跨机通信的场景。选 UDS 前要确认部署边界稳定在单机内。
8.6 “eBPF sockmap 开了就一定更快”
不一定。sockmap 适合特定本机 TCP 转发场景,尤其是 sidecar 模式。如果流量路径不匹配、BPF map 维护复杂、连接方向处理不完整,收益可能被复杂度抵消。
九、参考资料
书籍
- 《深入理解 Linux 网络》 第四章、第九章
原始推荐文章
- 127.0.0.1 之本机网络通信过程知多少 ?
- 这种本机网络 IO 方法,性能可以翻倍!
- eBPF 在网易轻舟云原生的应用实践
- 图解 Linux 网络包接收过程
- 25 张图,一万字,拆解 Linux 网络包发送过程
- Linux 网络包接收过程的监控与调优
可访问转载和镜像
- 127.0.0.1 之本机网络通信过程知多少
- 这种本机网络 IO 方法,性能可以翻倍
- 25 张图,一万字,拆解 Linux 网络包发送过程
- 图解 Linux 网络包接收过程
- Linux 网络包接收过程的监控与调优
官方和源码资料
相关笔记
- [[09、内核是如何接收网络包的-01]]
- [[10、内核是如何发送网络包的]]