
我们将会分为3个阶段分别学习AI开发相关的内容,第一阶段是RAG,第二阶段是MCP,第三阶段是AIAgent智能体。
关于本章节则是是一个第一阶段RAG 静态知识库项目总体的介绍章节,基于 Ollama 部署 DeepSeek 大模型,提供 API 接口。运用 Spring AI 框架承接接口实现 RAG 知识库能力。重点在于突出 RAG 功能实现。
RAG相关介绍
以下内容摘录自检索增强生成RAG
通用语言模型通过微调就可以完成几类常见任务,比如分析情绪和识别命名实体。这些任务不需要额外的背景知识就可以完成。
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG)的方法来完成这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
Lewis 等人(2021)提出一个通用的 RAG 微调方法。这种方法使用预训练的 seq2seq 作为参数记忆,用维基百科的密集向量索引作为非参数记忆(使通过神经网络预训练的检索器访问)。这种方法工作原理概况如下:
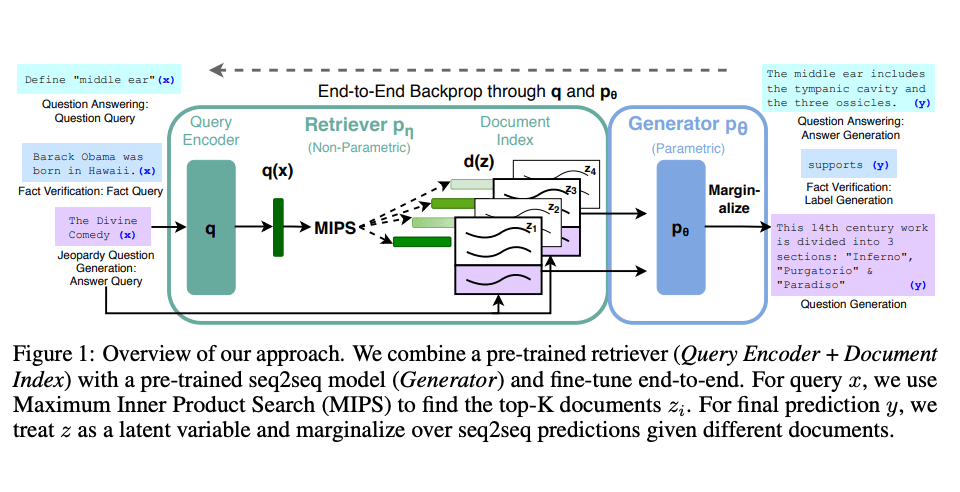
以下内容摘录自 RAG的场景即技术原理
RAG技术凭借其将检索与生成相结合的优势,可广泛应用于多个领域和场景,满足了在大模型应用中实时性、高准确性和领域专有知识获取的需求。
在企业或领域知识管理与问答系统中,RAG能够实时从企业或领域的私有知识库中检索相关信息,确保生成的回答不仅准确且符合企业内部的最新动态,解决了大模型在处理特定领域知识时的局限性。
其次,在客户支持与智能客服系统中,RAG可以动态地将用户的询问与最新的产品信息、客服知识等外部数据相结合,生成的回答更加贴合客户的实际需求,且满足企业要求。
此外,RAG在医疗、金融等对数据准确性、时效性要求极高的专业领域中尤为重要。通过实时检索最新的研究成果、市场动态或文档资料,RAG确保了生成的内容不仅基于最新信息,同时具备领域专有知识的深度分析能力。这些场景中,RAG的应用有效优化了大模型的固有缺陷,为大模型应用提供了更高的可靠性和场景可落地性。
RAG标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
最后生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
通过这一流程,RAG实现了检索与生成的有机结合,显著提升了LLM在领域任务中的准确性和实时性。
索引是RAG系统的基础环节,包含四个关键步骤。
首先,将各类数据源及其格式(如书籍、教材、领域数据、企业文档等,txt、markdown、doc、ppt、excel、pdf、html、json等格式)统一解析为纯文本格式。
接着,根据文本的语义或文档结构,将文档分割为小而语义完整的文本块(chunks),确保系统能够高效检索和利用这些块中包含的信息。
然后,使用文本嵌入模型(embedding model),将这些文本块向量化,生成高维稠密向量,转换为计算机可理解的语义表示。
最后,将这些向量存储在向量数据库(vector database)中,并构建索引,完成知识库的构建。这一流程成功将外部文档转化为可检索的向量,支撑后续的检索和生成环节。
检索是连接用户查询与知识库的核心环节。首先,用户输入的问题通过同样的文本嵌入模型转换为向量表示,将查询映射到与知识库内容相同的向量空间中。通过相似度度量方法,检索模块从向量数据库中筛选出与查询最相关的前K个文本块,这些文本块将作为生成阶段输入的一部分。通过相似性搜索,检索模块有效获取了与用户查询切实相关的外部知识,为生成阶段提供了精确且有意义的上下文支持。
生成是RAG流程中的最终环节,将检索到的相关文本块与用户的原始查询整合为增强提示词(Prompt),并输入到大语言模型(LLM)中。LLM基于这些输入生成最终的回答,确保生成内容既符合用户的查询意图,又充分利用了检索到的上下文信息,使得回答更加准确和相关,充分使用到知识库中的知识。通过这一过程,RAG实现了具备领域知识和私有信息的精确内容生成。
详细的学习可以去参考论文综述:Retrieval-Augmented Generation: A Comprehensive Survey of Architectures, Enhancements, and Robustness Frontiers
第一阶段项目概述
以下内容摘录自 xfg-关于AI RAG知识库介绍
我们知道 AI(OpenAI/DeepSeek)的信息回复是基于我们的提问,提问的信息越完善准确,越可以更好的反馈结果。
那么对于一个Git项目或者一个工程的全部SQL,我们需要对工程信息发起提问,但不想每次都从工程或者SQL中做整理,那么就可以把这些信息提交给知识库。那么每次提问的时候选择对应的知识库,就可以帮我们携带文本向量匹配知识,之后进行一起提交给 AI 大模型来提问。如图;
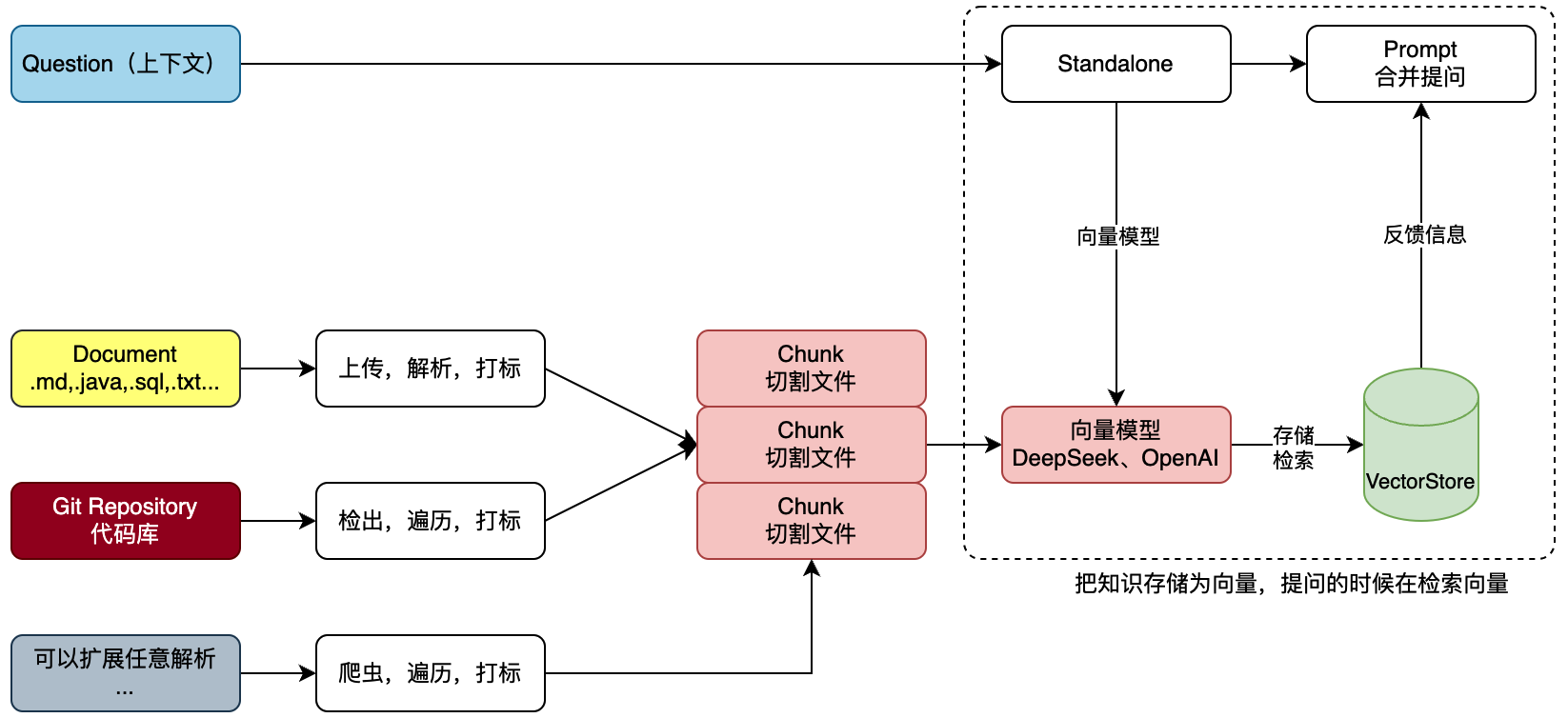
首先,文本知识库可以是非常多种的类型,不非得限定到文字,也可以是sql或者java代码。那么这里我们就可以解析一类是上传的文件,一类是Git代码库的项目。也可以是来自于网页的内容之后爬虫。这些内容都可以被解析处理。
之后,把文件进行切割,存储到向量模型。存储的时候要对文件进行打标,标记出属于哪个知识库。甚至你可以做的更细致,比如,项目工程时,这是什么包下的什么类。都可以打标。完事后存储到向量库。这个也就是说所说的文本向量化。
最后,在进行提问的时候,以提交的问题和问题到向量库检索,一起合并信息进行提问,这样提问的信息描述会更加定向准确,也就可以获得更好的回答。如,我们问的是,
请对拼团项目SQL语句,生产对应的所有JavaPO对象。那么这个时候就会反馈类信息了。也可以为运营伙伴提供必要的SQL语句请提供我要查询xxx、yyy、zzz数据,在什么时间产生的数据。,他们也就不用非得找研发要SQL语句了。这样就可以帮助企业提效了。
最终一阶段的效果:
1.对话页面
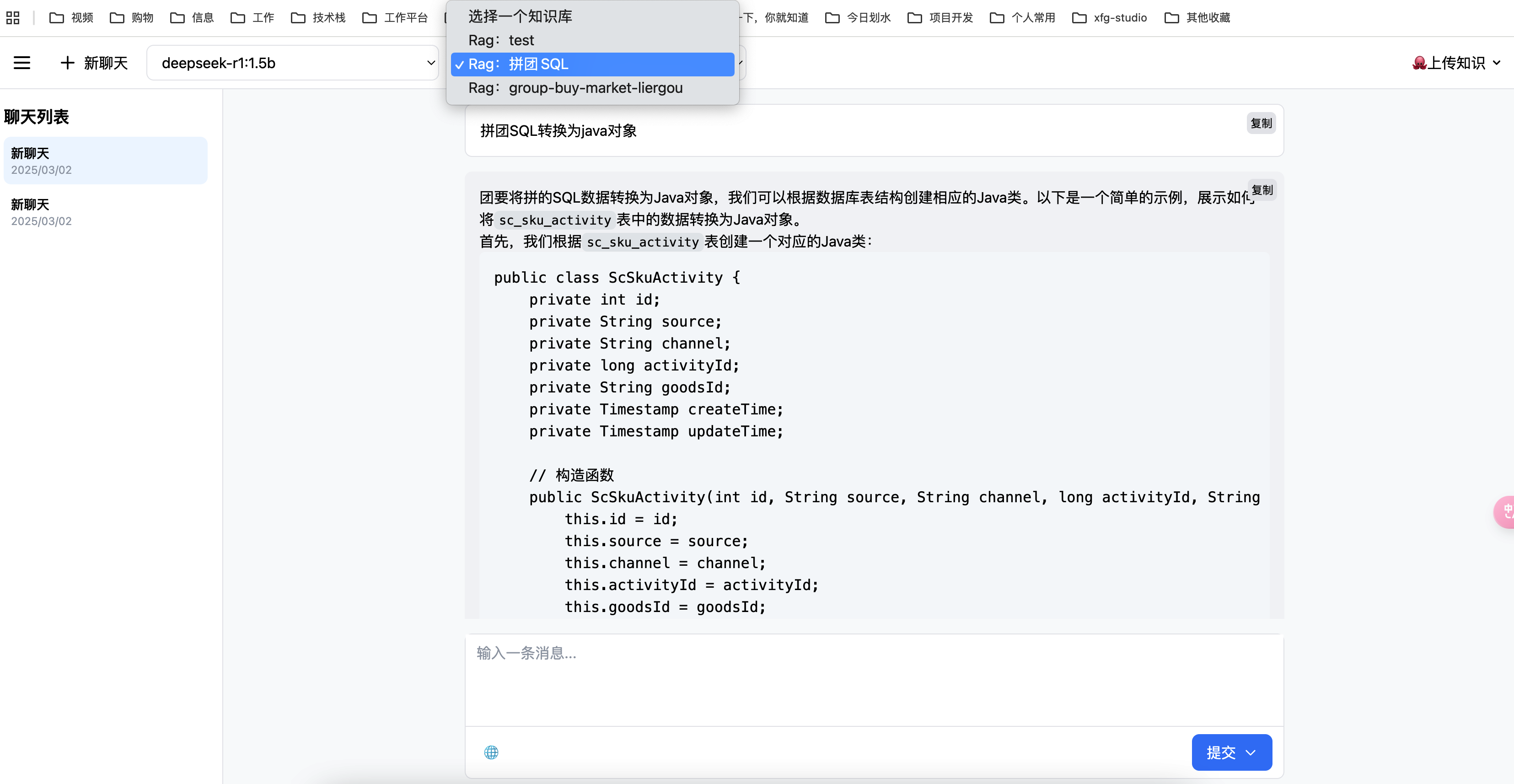
这是通过非常多的AI工具😂(课程会演示这个操作),实现的一款非常简单漂亮的UI效果。
上传知识
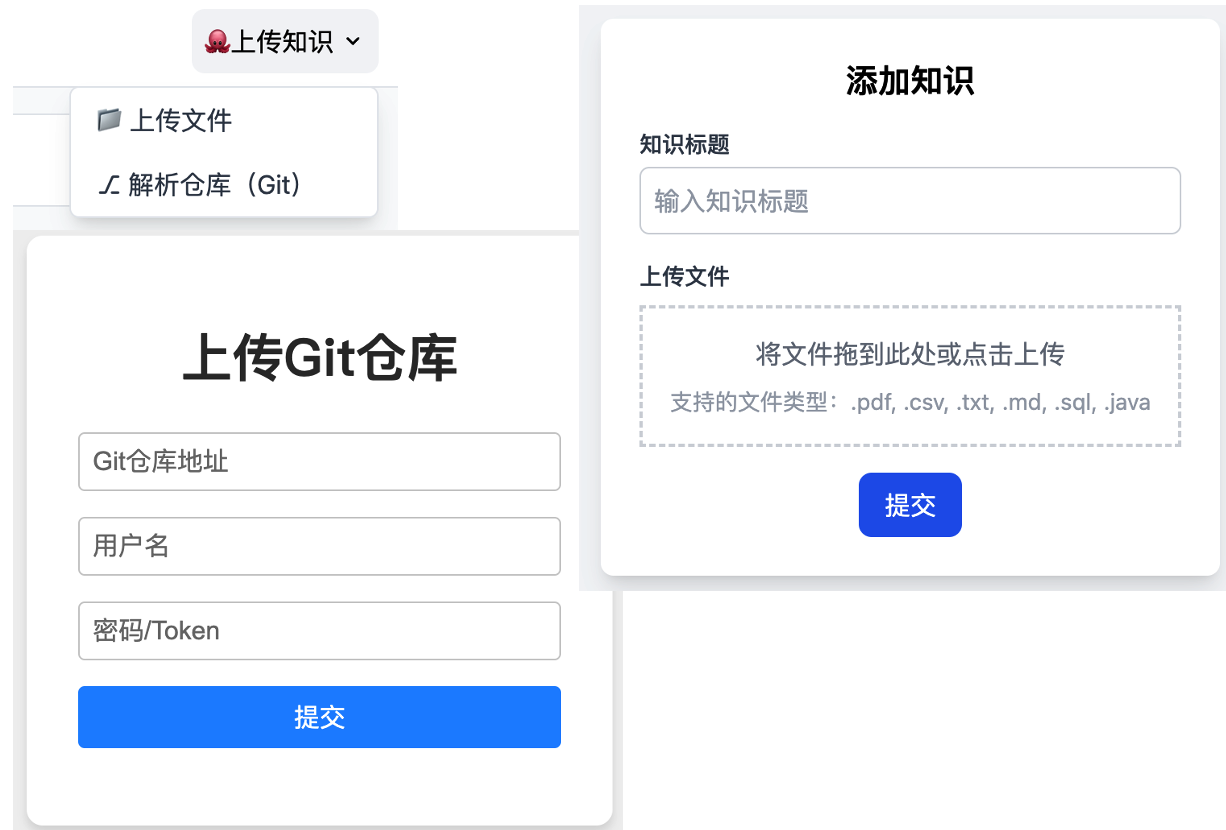
上传知识,可以解析不同类型的知识库。
除了课程提供的文档库、代码库,你可以增加其他的知识库,如;网页的解析,与网页内容对话。让我们的UI,增加一个侧边栏,读取当前网页内容,分析对话。这样在公司中的一些工程的日志,错误分析时,可以更快的处理。
解析知识 - 后台日志

上传知识后,可以看到日志信息。