
1、redis对epoll的使用
redis服务启动
redis启动时,主要流程源码如下
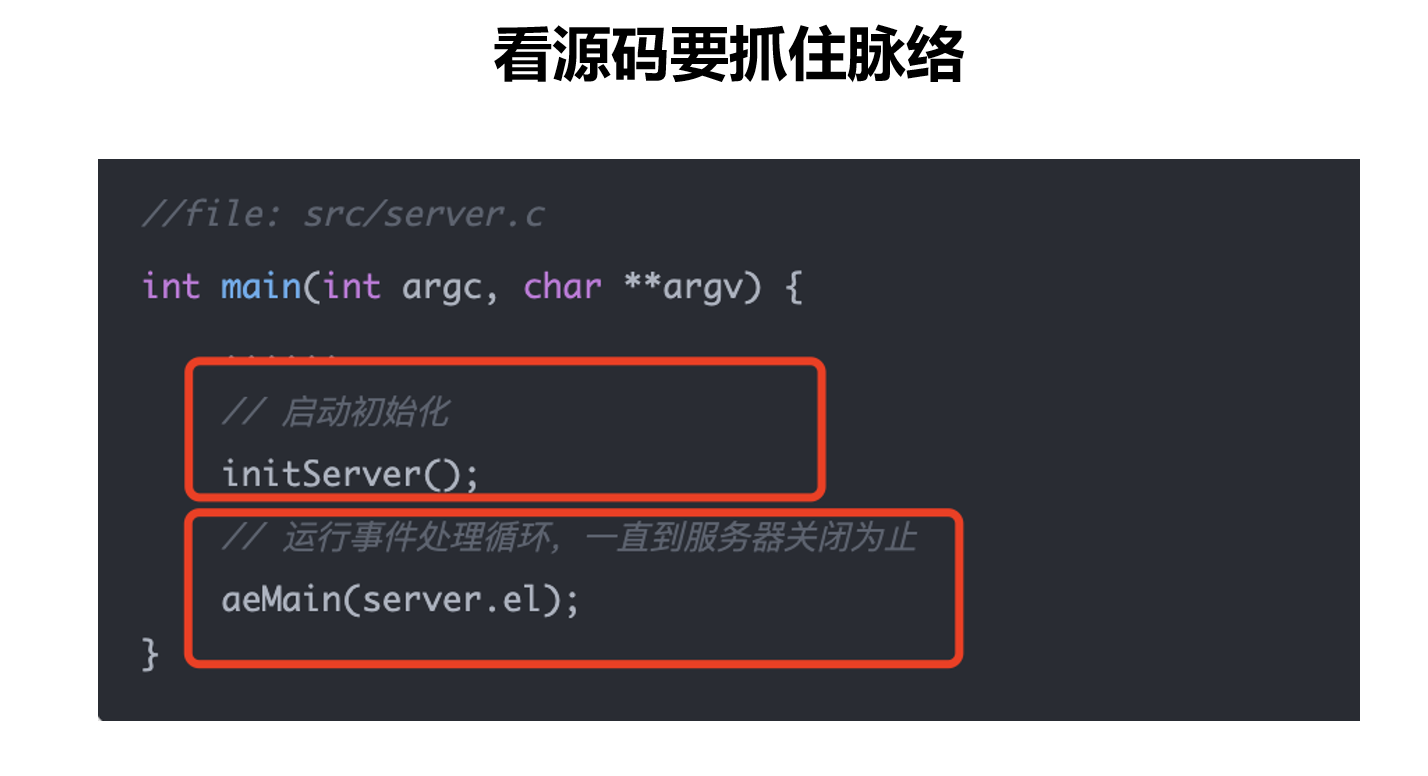
redis服务启动后其实就2个主要函数
‘启动初始化
事件循环
下面我们来看下启动初始化initServer主要干的事情
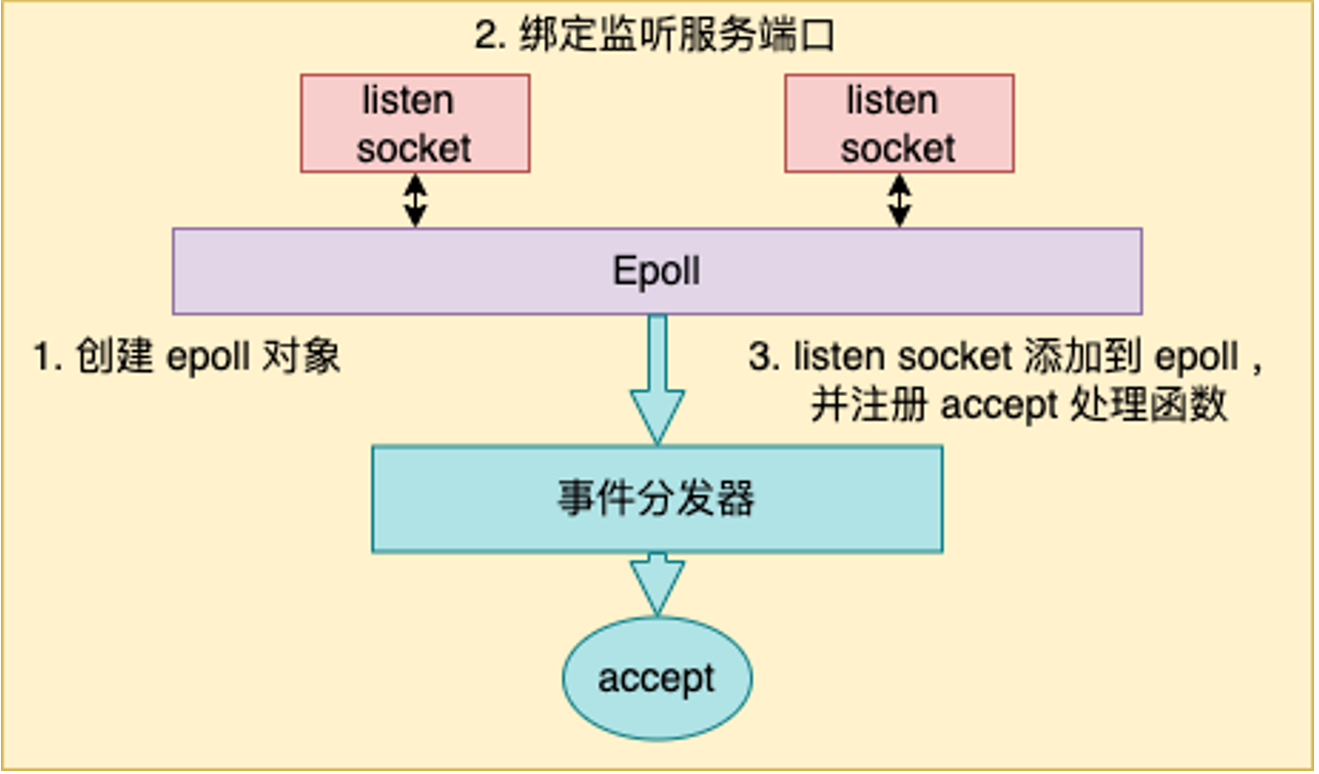
主要有以下几步
创建epoll对象
绑定监听服务端口
将listen socket添加到epoll,让epoll对象管理这个连接
注册一个回调函数accept,当后续有对应的listen socket的事件到达时,回调accept函数
源码大致如下
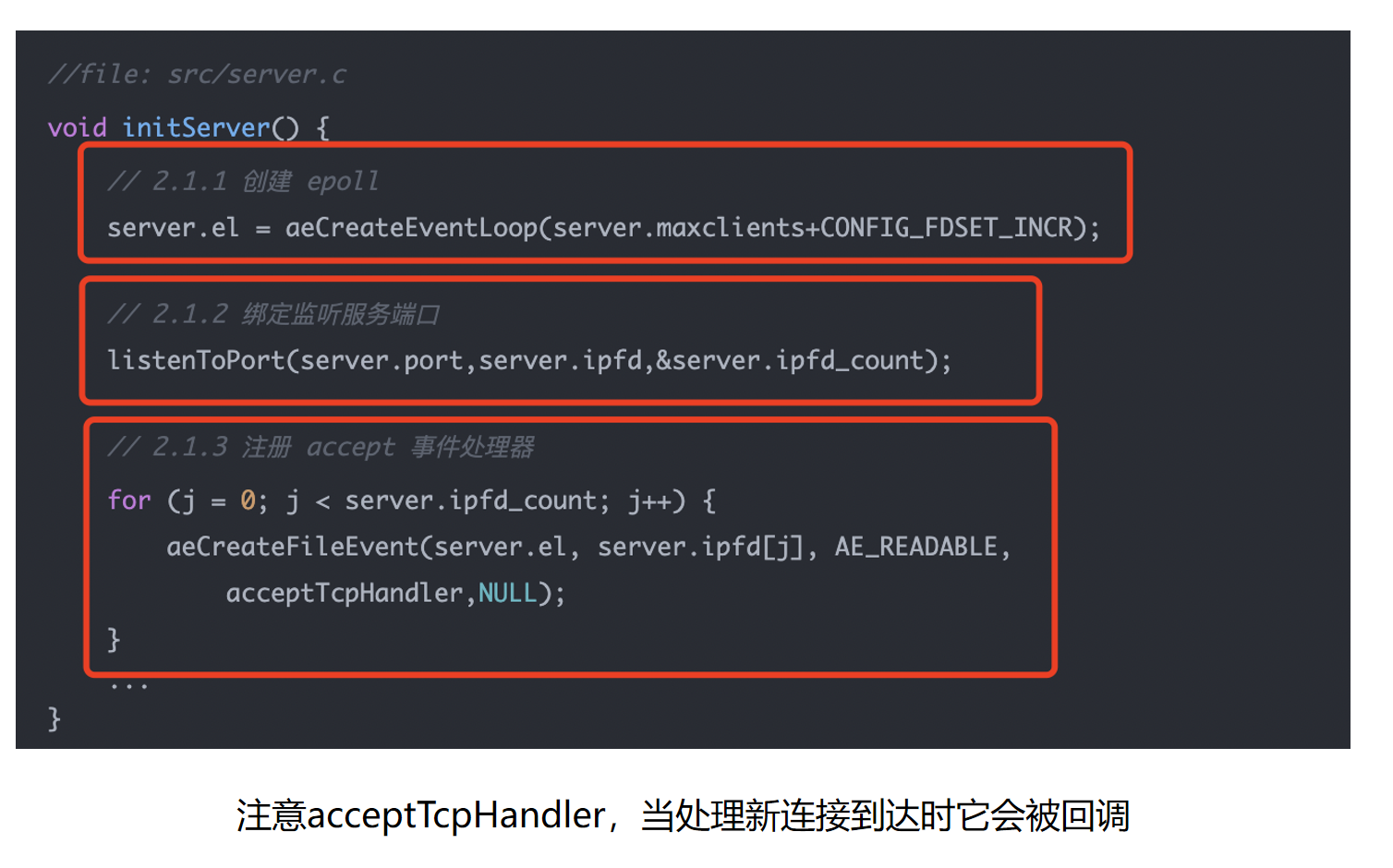
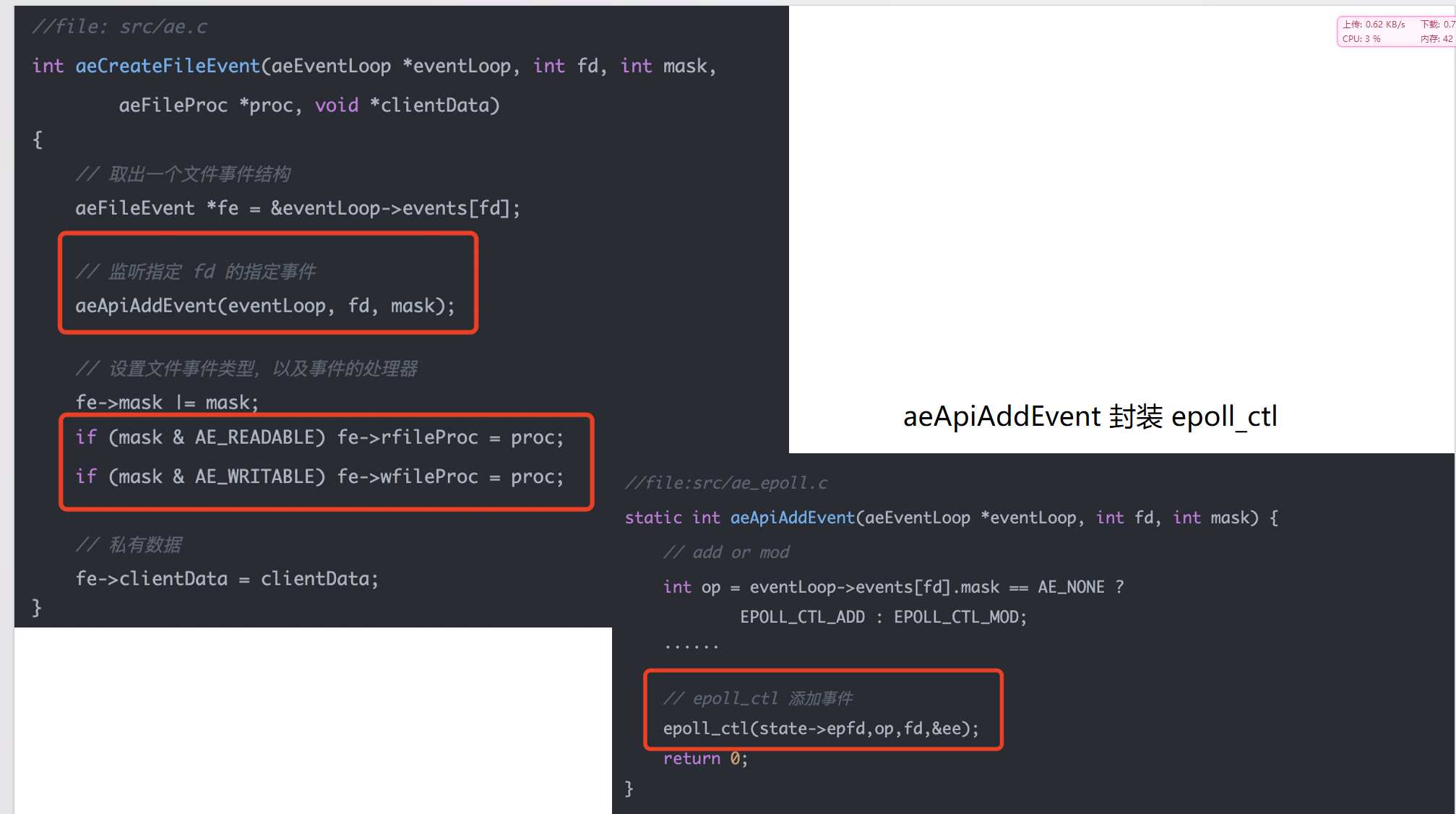
我们重点来看aeCreateFileEvent这其中的流程
事件循环
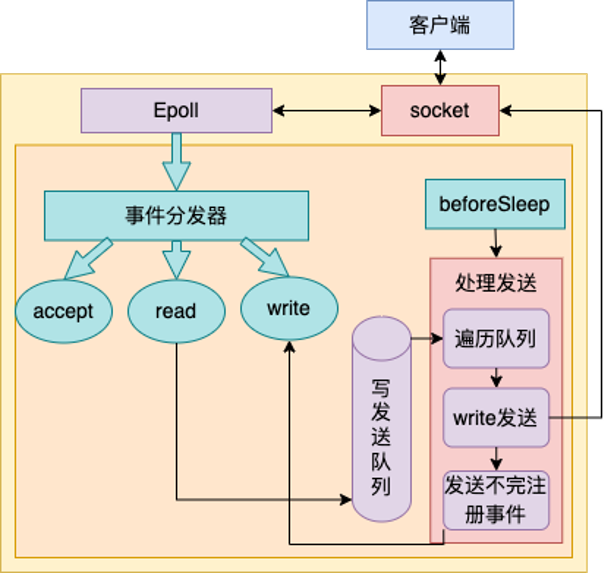
初始化时epoll对象,listen对象创建好了,事件处理也已经就绪了,接下来就要进入事件循环中去,等待用户连接到达。
如下图
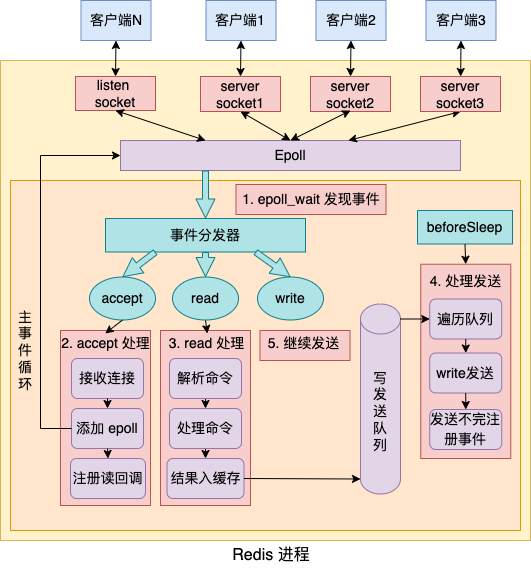
多个listen socket被epoll对象管理
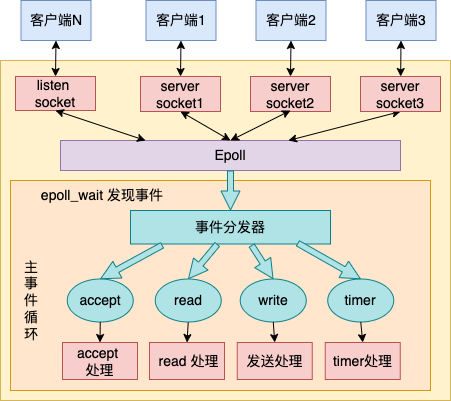
通过epoll_wait发现事件,并区分不同的事件类型处理
根据不同的事件类型进行不同的处理
这里需要注意的是:虽然上面的图将
beforeSleep这个处理发送的逻辑标为第4步,但是实际上redis的源码中,epoll_wait的实现代码第一步就调用了beforeSleep函数,即先处理写发送队列中的内容,然后再来看事件分发处理
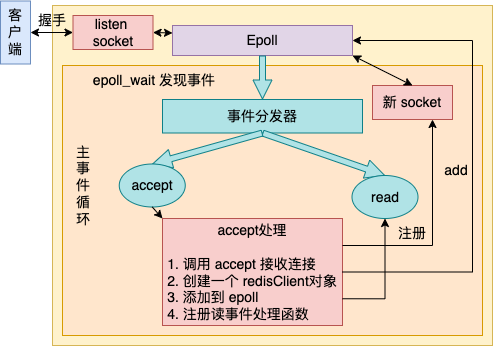
其中对于accept的处理如下
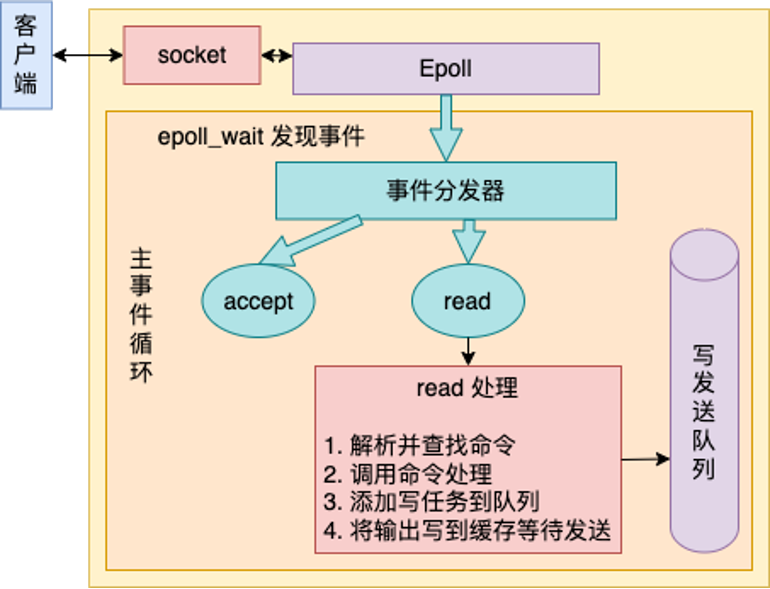
对于read事件的处理如下
发送处理如下
2、相关源码阅读
更加详细的内容可以参考张彦飞-epoll应用案例之Redis源码分析
主要的源码函数在于
//file: src/server.c
int main(int argc, char **argv) {
......
// 启动初始化
initServer();
// 运行事件处理循环,一直到服务器关闭为止
aeMain(server.el);
}接下来我们就去redis 5.0版本的源码中去查看对应函数的向下处理。这里用的IDE是CLion,vscode和cursor的点击源码进行跳转大哦对应函数都不够好用
initServer
首先我们来看下initServer()的具体源码,来查看究竟里面干了写什么东西
我们进入这个其中的调用完整函数中进行查看阅读
void initServer(void) {
int j;
signal(SIGHUP, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
setupSignalHandlers();
if (server.syslog_enabled) {
openlog(server.syslog_ident, LOG_PID | LOG_NDELAY | LOG_NOWAIT,
server.syslog_facility);
}
server.hz = server.config_hz;
server.pid = getpid();
server.current_client = NULL;
server.fixed_time_expire = 0;
server.clients = listCreate();
server.clients_index = raxNew();
server.clients_to_close = listCreate();
server.slaves = listCreate();
server.monitors = listCreate();
server.clients_pending_write = listCreate();
server.slaveseldb = -1; /* Force to emit the first SELECT command. */
server.unblocked_clients = listCreate();
server.ready_keys = listCreate();
server.clients_waiting_acks = listCreate();
server.get_ack_from_slaves = 0;
server.clients_paused = 0;
server.system_memory_size = zmalloc_get_memory_size();
createSharedObjects();
adjustOpenFilesLimit();
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
if (server.el == NULL) {
serverLog(LL_WARNING,
"Failed creating the event loop. Error message: '%s'",
strerror(errno));
exit(1);
}
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
/* Open the TCP listening socket for the user commands. */
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR)
exit(1);
/* Open the listening Unix domain socket. */
if (server.unixsocket != NULL) {
unlink(server.unixsocket); /* don't care if this fails */
server.sofd = anetUnixServer(server.neterr,server.unixsocket,
server.unixsocketperm, server.tcp_backlog);
if (server.sofd == ANET_ERR) {
serverLog(LL_WARNING, "Opening Unix socket: %s", server.neterr);
exit(1);
}
anetNonBlock(NULL,server.sofd);
}
/* Abort if there are no listening sockets at all. */
if (server.ipfd_count == 0 && server.sofd < 0) {
serverLog(LL_WARNING, "Configured to not listen anywhere, exiting.");
exit(1);
}
/* Create the Redis databases, and initialize other internal state. */
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType,NULL);
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
server.db[j].blocking_keys = dictCreate(&keylistDictType,NULL);
server.db[j].ready_keys = dictCreate(&objectKeyPointerValueDictType,NULL);
server.db[j].watched_keys = dictCreate(&keylistDictType,NULL);
server.db[j].id = j;
server.db[j].avg_ttl = 0;
server.db[j].defrag_later = listCreate();
}
evictionPoolAlloc(); /* Initialize the LRU keys pool. */
server.pubsub_channels = dictCreate(&keylistDictType,NULL);
server.pubsub_patterns = listCreate();
listSetFreeMethod(server.pubsub_patterns,freePubsubPattern);
listSetMatchMethod(server.pubsub_patterns,listMatchPubsubPattern);
server.cronloops = 0;
server.rdb_child_pid = -1;
server.aof_child_pid = -1;
server.rdb_child_type = RDB_CHILD_TYPE_NONE;
server.rdb_bgsave_scheduled = 0;
server.child_info_pipe[0] = -1;
server.child_info_pipe[1] = -1;
server.child_info_data.magic = 0;
aofRewriteBufferReset();
server.aof_buf = sdsempty();
server.lastsave = time(NULL); /* At startup we consider the DB saved. */
server.lastbgsave_try = 0; /* At startup we never tried to BGSAVE. */
server.rdb_save_time_last = -1;
server.rdb_save_time_start = -1;
server.dirty = 0;
resetServerStats();
/* A few stats we don't want to reset: server startup time, and peak mem. */
server.stat_starttime = time(NULL);
server.stat_peak_memory = 0;
server.stat_rdb_cow_bytes = 0;
server.stat_aof_cow_bytes = 0;
server.cron_malloc_stats.zmalloc_used = 0;
server.cron_malloc_stats.process_rss = 0;
server.cron_malloc_stats.allocator_allocated = 0;
server.cron_malloc_stats.allocator_active = 0;
server.cron_malloc_stats.allocator_resident = 0;
server.lastbgsave_status = C_OK;
server.aof_last_write_status = C_OK;
server.aof_last_write_errno = 0;
server.repl_good_slaves_count = 0;
/* Create the timer callback, this is our way to process many background
* operations incrementally, like clients timeout, eviction of unaccessed
* expired keys and so forth. */
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
/* Create an event handler for accepting new connections in TCP and Unix
* domain sockets. */
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
if (server.sofd > 0 && aeCreateFileEvent(server.el,server.sofd,AE_READABLE,
acceptUnixHandler,NULL) == AE_ERR) serverPanic("Unrecoverable error creating server.sofd file event.");
/* Register a readable event for the pipe used to awake the event loop
* when a blocked client in a module needs attention. */
if (aeCreateFileEvent(server.el, server.module_blocked_pipe[0], AE_READABLE,
moduleBlockedClientPipeReadable,NULL) == AE_ERR) {
serverPanic(
"Error registering the readable event for the module "
"blocked clients subsystem.");
}
/* Open the AOF file if needed. */
if (server.aof_state == AOF_ON) {
server.aof_fd = open(server.aof_filename,
O_WRONLY|O_APPEND|O_CREAT,0644);
if (server.aof_fd == -1) {
serverLog(LL_WARNING, "Can't open the append-only file: %s",
strerror(errno));
exit(1);
}
}
/* 32 bit instances are limited to 4GB of address space, so if there is
* no explicit limit in the user provided configuration we set a limit
* at 3 GB using maxmemory with 'noeviction' policy'. This avoids
* useless crashes of the Redis instance for out of memory. */
if (server.arch_bits == 32 && server.maxmemory == 0) {
serverLog(LL_WARNING,"Warning: 32 bit instance detected but no memory limit set. Setting 3 GB maxmemory limit with 'noeviction' policy now.");
server.maxmemory = 3072LL*(1024*1024); /* 3 GB */
server.maxmemory_policy = MAXMEMORY_NO_EVICTION;
}
if (server.cluster_enabled) clusterInit();
replicationScriptCacheInit();
scriptingInit(1);
slowlogInit();
latencyMonitorInit();
}我们发现它的前半段大部分都是在进行配置参数的初始化设置,这一块都不是我们现在的重点
其中真正与epoll高性能使用的相关语句只有
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
/* Open the TCP listening socket for the user commands. */
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR)
exit(1);
/* Create an event handler for accepting new connections in TCP and Unix
* domain sockets. */
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
这些代码的作用依次是
创建epoll对象
绑定监听用户的TCP服务端口连接
创建对于接受新的TCP连接的事件处理器
接下来我们详细看看这部分函数
aeCreateEventLoop函数
在IDE中点击aeCreateEventLoop函数,进入其具体的的代码
// src/ae.c
aeEventLoop *aeCreateEventLoop(int setsize) {
aeEventLoop *eventLoop;
int i;
if ((eventLoop = zmalloc(sizeof(*eventLoop))) == NULL) goto err;
eventLoop->events = zmalloc(sizeof(aeFileEvent)*setsize);
eventLoop->fired = zmalloc(sizeof(aeFiredEvent)*setsize);
if (eventLoop->events == NULL || eventLoop->fired == NULL) goto err;
eventLoop->setsize = setsize;
eventLoop->lastTime = time(NULL);
eventLoop->timeEventHead = NULL;
eventLoop->timeEventNextId = 0;
eventLoop->stop = 0;
eventLoop->maxfd = -1;
eventLoop->beforesleep = NULL;
eventLoop->aftersleep = NULL;
if (aeApiCreate(eventLoop) == -1) goto err;
/* Events with mask == AE_NONE are not set. So let's initialize the
* vector with it. */
for (i = 0; i < setsize; i++)
eventLoop->events[i].mask = AE_NONE;
return eventLoop;
err:
if (eventLoop) {
zfree(eventLoop->events);
zfree(eventLoop->fired);
zfree(eventLoop);
}
return NULL;
}其中的源码主要干了下面这几件事情:
分配
aeEventLoop结构体eventLoop为
eventLoop分配空间,做各种中间变量的初始化调用底层 I/O 多路复用 API 的初始化函数
aeApiCreate初始化所有文件事件的
mask为AE_NONE(表示没有事件)
我们主要接着aeApiCreate往下面看过去,源码如下
// src/ae.epoll.c
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
if (!state->events) {
zfree(state);
return -1;
}
state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */
if (state->epfd == -1) {
zfree(state->events);
zfree(state);
return -1;
}
eventLoop->apidata = state;
return 0;
}分配并初始化一个
aeApiState,这是 Redis 对 epoll 的封装。为 epoll 事件数组分配空间。
调用
epoll_create创建内核中的 epoll 实例,得到 epoll 文件描述符。把这个
aeApiState挂到事件循环对象eventLoop->apidata上
这段源码有很多内容,但是我们看源码一定要带着学习目的来看,我们本章节主要是研究epoll在redis中的使用,这里我们不需要关注那么多redis对epoll的封装,我们只需要知道在redis的main函数启动时,调用了初始化函数initServer,而initServer调用了aeCreateEventLoop,然后其中又调用了aeApiCreate,在这里面我们看到了epoll基本使用代码的epoll_create函数。即initServer中最初就开始了epoll对象的创建
接下来我们来看initServer有关epoll使用的第二段重点代码listenToPort干了些什么
listenToPort
其中的源码我们进入如下
// src/server.c
int listenToPort(int port, int *fds, int *count) {
int j;
/* Force binding of 0.0.0.0 if no bind address is specified, always
* entering the loop if j == 0. */
if (server.bindaddr_count == 0) server.bindaddr[0] = NULL;
for (j = 0; j < server.bindaddr_count || j == 0; j++) {
if (server.bindaddr[j] == NULL) {
int unsupported = 0;
/* Bind * for both IPv6 and IPv4, we enter here only if
* server.bindaddr_count == 0. */
fds[*count] = anetTcp6Server(server.neterr,port,NULL,
server.tcp_backlog);
if (fds[*count] != ANET_ERR) {
anetNonBlock(NULL,fds[*count]);
(*count)++;
} else if (errno == EAFNOSUPPORT) {
unsupported++;
serverLog(LL_WARNING,"Not listening to IPv6: unsupproted");
}
if (*count == 1 || unsupported) {
/* Bind the IPv4 address as well. */
fds[*count] = anetTcpServer(server.neterr,port,NULL,
server.tcp_backlog);
if (fds[*count] != ANET_ERR) {
anetNonBlock(NULL,fds[*count]);
(*count)++;
} else if (errno == EAFNOSUPPORT) {
unsupported++;
serverLog(LL_WARNING,"Not listening to IPv4: unsupproted");
}
}
/* Exit the loop if we were able to bind * on IPv4 and IPv6,
* otherwise fds[*count] will be ANET_ERR and we'll print an
* error and return to the caller with an error. */
if (*count + unsupported == 2) break;
} else if (strchr(server.bindaddr[j],':')) {
/* Bind IPv6 address. */
fds[*count] = anetTcp6Server(server.neterr,port,server.bindaddr[j],
server.tcp_backlog);
} else {
/* Bind IPv4 address. */
fds[*count] = anetTcpServer(server.neterr,port,server.bindaddr[j],
server.tcp_backlog);
}
if (fds[*count] == ANET_ERR) {
serverLog(LL_WARNING,
"Could not create server TCP listening socket %s:%d: %s",
server.bindaddr[j] ? server.bindaddr[j] : "*",
port, server.neterr);
if (errno == ENOPROTOOPT || errno == EPROTONOSUPPORT ||
errno == ESOCKTNOSUPPORT || errno == EPFNOSUPPORT ||
errno == EAFNOSUPPORT || errno == EADDRNOTAVAIL)
continue;
return C_ERR;
}
anetNonBlock(NULL,fds[*count]);
(*count)++;
}
return C_OK;
}这种源码阅读要带着关注的目的来看,不然很容易被它绕晕。
我们注意有段注释写到绑定IPV4,我们的epoll之所以高性能就是因为监听多个连接
/* Bind the IPv4 address as well. */
fds[*count] = anetTcpServer(server.neterr,port,NULL,
server.tcp_backlog);我们进入anetTcpServer函数
// src/anet.c
int anetTcpServer(char *err, int port, char *bindaddr, int backlog)
{
return _anetTcpServer(err, port, bindaddr, AF_INET, backlog);
}
static int _anetTcpServer(char *err, int port, char *bindaddr, int af, int backlog)
{
int s = -1, rv;
char _port[6]; /* strlen("65535") */
struct addrinfo hints, *servinfo, *p;
snprintf(_port,6,"%d",port);
memset(&hints,0,sizeof(hints));
hints.ai_family = af;
hints.ai_socktype = SOCK_STREAM;
hints.ai_flags = AI_PASSIVE; /* No effect if bindaddr != NULL */
if ((rv = getaddrinfo(bindaddr,_port,&hints,&servinfo)) != 0) {
anetSetError(err, "%s", gai_strerror(rv));
return ANET_ERR;
}
for (p = servinfo; p != NULL; p = p->ai_next) {
if ((s = socket(p->ai_family,p->ai_socktype,p->ai_protocol)) == -1)
continue;
if (af == AF_INET6 && anetV6Only(err,s) == ANET_ERR) goto error;
if (anetSetReuseAddr(err,s) == ANET_ERR) goto error;
if (anetListen(err,s,p->ai_addr,p->ai_addrlen,backlog) == ANET_ERR) s = ANET_ERR;
goto end;
}
if (p == NULL) {
anetSetError(err, "unable to bind socket, errno: %d", errno);
goto error;
}
error:
if (s != -1) close(s);
s = ANET_ERR;
end:
freeaddrinfo(servinfo);
return s;
}
static int anetListen(char *err, int s, struct sockaddr *sa, socklen_t len, int backlog) {
if (bind(s,sa,len) == -1) {
anetSetError(err, "bind: %s", strerror(errno));
close(s);
return ANET_ERR;
}
if (listen(s, backlog) == -1) {
anetSetError(err, "listen: %s", strerror(errno));
close(s);
return ANET_ERR;
}
return ANET_OK;
}其中的anetTcpServer进入调用_anetTcpServer
而在_anetTcpServer中,它实际是是 Redis 网络库 anet.c 里的一个内部函数,用来创建一个 TCP 服务器监听 socket(代码
p = servinfo)。它基本上就是socket+bind+listen的封装,同时带有一些健壮性和跨平台处理而其中对应
bind+listen的封装就在anetListen函数
所以在这里我们明白initServer创建完epoll对象后,调用listenToPort函数,创建了socket并对这个socket进行了绑定监听操作
aeCreateFileEvent
其对应源码如下
// src/ae.c
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
if (fd >= eventLoop->setsize) {
errno = ERANGE;
return AE_ERR;
}
aeFileEvent *fe = &eventLoop->events[fd];
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
fe->clientData = clientData;
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}这段代码实际是 Redis 事件驱动框架里非常关键的一个接口,用来在事件循环中注册文件事件(读/写事件)
先检查要监听的文件描述符fd(socket fd)是否越界
然后找到对应的aeFileEvent结构
aeFileEvent *fe = &eventLoop->events[fd];然后调用底层接口注册事件
aeApiAddEvent(eventLoop, fd, mask)然后设置好监听事件的读写函数的回调函数
fe->rfileProc = proc;,fe->wfileProc = proc最后更新最大 fd,在某些多路复用实现(如
select)中需要知道最大 fd,提升效率
我们主要的重点是在aeApiAddEvent这个函数中,源码如下
// src/ae_epoll.c
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}在这段源码中我们看到了epoll基本使用的代码
epoll_ctl,这个函数就是将多个TCP连接放在一个epoll对象上进行监控的关键,也是epoll多路复用的核心体现。
因此在initServer操作中,redis先是通过aeCreateEventLoop函数创建了epoll对象,然后通过listenToPort创建了socket并对socket进行了bind和listen操作(绑定IP端口,进行被动监听),最后通过aeCreateFileEvent函数将socket加入一个epoll对象中进行监听,从而实现了多路复用,让redis有了一个线程就有极高的QPS。
acceptTcpHandler
在initServer的对于aeCreateFileEven函数的调用中,传入了acceptTcpHandler这个回调函数
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
while(max--) {
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
acceptCommonHandler(cfd,0,cip);
}
}在 anetTcpAccept 中执行非常的简单,就是调用 accept 把连接接收回来。
//file: src/anet.c
int anetTcpAccept(char *err, int s, char *ip, size_t ip_len, int *port) {
int fd;
struct sockaddr_storage sa;
socklen_t salen = sizeof(sa);
if ((fd = anetGenericAccept(err,s,(struct sockaddr*)&sa,&salen)) == -1)
return ANET_ERR;
if (sa.ss_family == AF_INET) {
struct sockaddr_in *s = (struct sockaddr_in *)&sa;
if (ip) inet_ntop(AF_INET,(void*)&(s->sin_addr),ip,ip_len);
if (port) *port = ntohs(s->sin_port);
} else {
struct sockaddr_in6 *s = (struct sockaddr_in6 *)&sa;
if (ip) inet_ntop(AF_INET6,(void*)&(s->sin6_addr),ip,ip_len);
if (port) *port = ntohs(s->sin6_port);
}
return fd;
}接下来在 acceptCommonHandler 为这个新的客户端连接 socket,创建一个 redisClient 对象。
//file: src/networking.c
static void acceptCommonHandler(int fd, int flags) {
// 创建 redisClient 对象
redisClient *c;
c = createClient(fd);
......
}在 createClient 中,创建 client 对象,并且为该用户连接注册了读事件处理器。
//file:src/networking.c
redisClient *createClient(int fd) {
// 为用户连接创建 client 对象
redisClient *c = zmalloc(sizeof(redisClient));
if (fd != -1) {
...
// 为用户连接注册读事件处理器
aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c)
}
...
}aeMain
接着我们来看看redis初始化后执行的事件处理循环的逻辑
其源码如下
// src/ae.c
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}其中一直调用的是一个while循环,对循环事件进行处理
但是在处理之前它会优先调用
beforesleep函数,然后才会调用事件理函数aeProcessEvents
beforeSleep
其中beforeSleep函数源码如下
// src/server.c
/* This function gets called every time Redis is entering the
* main loop of the event driven library, that is, before to sleep
* for ready file descriptors. */
void beforeSleep(struct aeEventLoop *eventLoop) {
UNUSED(eventLoop);
/* Call the Redis Cluster before sleep function. Note that this function
* may change the state of Redis Cluster (from ok to fail or vice versa),
* so it's a good idea to call it before serving the unblocked clients
* later in this function. */
if (server.cluster_enabled) clusterBeforeSleep();
/* Run a fast expire cycle (the called function will return
* ASAP if a fast cycle is not needed). */
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
/* Send all the slaves an ACK request if at least one client blocked
* during the previous event loop iteration. */
if (server.get_ack_from_slaves) {
robj *argv[3];
argv[0] = createStringObject("REPLCONF",8);
argv[1] = createStringObject("GETACK",6);
argv[2] = createStringObject("*",1); /* Not used argument. */
replicationFeedSlaves(server.slaves, server.slaveseldb, argv, 3);
decrRefCount(argv[0]);
decrRefCount(argv[1]);
decrRefCount(argv[2]);
server.get_ack_from_slaves = 0;
}
/* Unblock all the clients blocked for synchronous replication
* in WAIT. */
if (listLength(server.clients_waiting_acks))
processClientsWaitingReplicas();
/* Check if there are clients unblocked by modules that implement
* blocking commands. */
moduleHandleBlockedClients();
/* Try to process pending commands for clients that were just unblocked. */
if (listLength(server.unblocked_clients))
processUnblockedClients();
/* Write the AOF buffer on disk */
flushAppendOnlyFile(0);
/* Handle writes with pending output buffers. */
handleClientsWithPendingWrites();
/* Before we are going to sleep, let the threads access the dataset by
* releasing the GIL. Redis main thread will not touch anything at this
* time. */
if (moduleCount()) moduleReleaseGIL();
}先影响全局状态的事(Cluster、过期)→ 再满足复制与阻塞语义(GETACK、WAIT、模块阻塞)→ 再尽量把输出与落盘做完(AOF、pending writes)→ 最后释放 GIL
这样安排能在不延迟睡眠太久的前提下,把“已经就绪的进度”尽量推进一格,提升吞吐与交互的及时性
我们主要关注
handleClientsWithPendingWrites这块的函数
// src/networking.c
/* This function is called just before entering the event loop, in the hope
* we can just write the replies to the client output buffer without any
* need to use a syscall in order to install the writable event handler,
* get it called, and so forth. */
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
/* If a client is protected, don't do anything,
* that may trigger write error or recreate handler. */
if (c->flags & CLIENT_PROTECTED) continue;
/* Try to write buffers to the client socket. */
if (writeToClient(c->fd,c,0) == C_ERR) continue;
/* If after the synchronous writes above we still have data to
* output to the client, we need to install the writable handler. */
if (clientHasPendingReplies(c)) {
int ae_flags = AE_WRITABLE;
/* For the fsync=always policy, we want that a given FD is never
* served for reading and writing in the same event loop iteration,
* so that in the middle of receiving the query, and serving it
* to the client, we'll call beforeSleep() that will do the
* actual fsync of AOF to disk. AE_BARRIER ensures that. */
if (server.aof_state == AOF_ON &&
server.aof_fsync == AOF_FSYNC_ALWAYS)
{
ae_flags |= AE_BARRIER;
}
if (aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c) == AE_ERR)
{
freeClientAsync(c);
}
}
}
return processed;
}通过源码的注释,我们可以明白这段代码主要是 Redis 在进入事件循环前尝试把“待写数据”的客户端尽量同步写出,以避免额外的系统调用(安装可写事件、等待回调再写)。核心目标:能直接写就直接写;写不完再挂可写事件。
在 handleClientsWithPendingWrites 中,遍历了发送任务队列 server.clients_pending_write,并调用 writeToClient 进行实际的发送处理。
注意:发送 write 并不总是能一次性发送完的。假如要发送的结果太大,而系统为每个 socket 设置的发送缓存区又是有限的。在这种情况下,clientHasPendingReplies 判断仍然有未发送完的数据的话,就需要注册一个写事件处理函数到 epoll 上。等待 epoll 发现该 socket 可写的时候再次调用 sendReplyToClient进行发送。
在执行完beforeSleep函数后就会进入aeProcessEvents函数。
aeProcessEvents
其源码如下
// src/ae.c
/* Process every pending time event, then every pending file event
* (that may be registered by time event callbacks just processed).
* Without special flags the function sleeps until some file event
* fires, or when the next time event occurs (if any).
*
* If flags is 0, the function does nothing and returns.
* if flags has AE_ALL_EVENTS set, all the kind of events are processed.
* if flags has AE_FILE_EVENTS set, file events are processed.
* if flags has AE_TIME_EVENTS set, time events are processed.
* if flags has AE_DONT_WAIT set the function returns ASAP until all
* if flags has AE_CALL_AFTER_SLEEP set, the aftersleep callback is called.
* the events that's possible to process without to wait are processed.
*
* The function returns the number of events processed. */
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
/* Nothing to do? return ASAP */
if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0;
/* Note that we want call select() even if there are no
* file events to process as long as we want to process time
* events, in order to sleep until the next time event is ready
* to fire. */
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int j;
aeTimeEvent *shortest = NULL;
struct timeval tv, *tvp;
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
long now_sec, now_ms;
aeGetTime(&now_sec, &now_ms);
tvp = &tv;
/* How many milliseconds we need to wait for the next
* time event to fire? */
long long ms =
(shortest->when_sec - now_sec)*1000 +
shortest->when_ms - now_ms;
if (ms > 0) {
tvp->tv_sec = ms/1000;
tvp->tv_usec = (ms % 1000)*1000;
} else {
tvp->tv_sec = 0;
tvp->tv_usec = 0;
}
} else {
/* If we have to check for events but need to return
* ASAP because of AE_DONT_WAIT we need to set the timeout
* to zero */
if (flags & AE_DONT_WAIT) {
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
/* Otherwise we can block */
tvp = NULL; /* wait forever */
}
}
/* Call the multiplexing API, will return only on timeout or when
* some event fires. */
numevents = aeApiPoll(eventLoop, tvp);
/* After sleep callback. */
if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP)
eventLoop->aftersleep(eventLoop);
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int fired = 0; /* Number of events fired for current fd. */
/* Normally we execute the readable event first, and the writable
* event laster. This is useful as sometimes we may be able
* to serve the reply of a query immediately after processing the
* query.
*
* However if AE_BARRIER is set in the mask, our application is
* asking us to do the reverse: never fire the writable event
* after the readable. In such a case, we invert the calls.
* This is useful when, for instance, we want to do things
* in the beforeSleep() hook, like fsynching a file to disk,
* before replying to a client. */
int invert = fe->mask & AE_BARRIER;
/* Note the "fe->mask & mask & ..." code: maybe an already
* processed event removed an element that fired and we still
* didn't processed, so we check if the event is still valid.
*
* Fire the readable event if the call sequence is not
* inverted. */
if (!invert && fe->mask & mask & AE_READABLE) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
/* Fire the writable event. */
if (fe->mask & mask & AE_WRITABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
/* If we have to invert the call, fire the readable event now
* after the writable one. */
if (invert && fe->mask & mask & AE_READABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
processed++;
}
}
/* Check time events */
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
return processed; /* return the number of processed file/time events */
}这段代码好长好长,但是它的注释写的也很清楚,处理所有挂起的时间事件,然后处理所有挂起的文件事件(包括刚才时间事件回调里新注册的文件事件),在没有特殊标志时,函数会休眠,直到有文件事件触发,或直到下一次时间事件到期(如果有)。
对于其中有很多if,但是其中
numevents = aeApiPoll(eventLoop, tvp);是单独的,它专门用来处理已注册 fd 的可读/可写就绪的文件事件(I/O 事件)
我们阅读一下其源码
// src/ae_epoll.c
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
if (retval > 0) {
int j;
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
return numevents;
}这里面调用了epoll_wait,这个epoll专门用来处理多个TCP连接的函数
到这里一切都清晰了redis在启动基本把所有的epoll基础代码全部使用了,利用了epoll的多路复用。
拓展详细阅读资料
参考资料
深入理解Linux网络